- Tuesday: lab in W31-301 from 4 PM to 7 PM with
the primary lab presentation taking
place from 4:10-5 PM. - Thursday: lecture in 9-450A from 5-6:30 PM.
- Optional lab times as needed
- Monday, 4-5:00 in W31-301 (together with 11.188 lab time)
- Optional additional lab time on Friday: 1:30 - 3:00 pm in
9-554
- Feb. 9 focus on MS-Access basics for data management and laptop software setup
- Other help via Eric Huntley (DUSP GIS specialist, 9-528) and GIS Lab in Rotch Library
- My office hours: Tuesday, 2:00 - 3 and Thursday, 10:30 - noon in my office (Room 9-532 )
- Everyone in lab last Tuesday should have MIT athena accounts for
WinAthena PC logins, and will soon have a personal Postgres accounts
(to replace the shared 'parcels' account):
- Harvard students: please tell me your MIT Athena login name so we can register it for Postgres as well
- After this week, and/or during Tuesday's lab, log into a CRON machine & test your access to Postgres
- Try http://cronpgsql.mit.edu/phppgadmin with the shared
'sqlguest' account today and then later with your personal
Postgres account:
- same userid as MIT userid
- get one-time password from me, then change to something safe (8+ letters/numbers, non-word, without any spaces or special characters)
- Class locker access: http://mit.edu/11.521/www (unrestricted) and http://mit.edu/11.521/data (may need kerberos tickets)
- 11.205 - Introduction to GIS and Spatial Planning this past Fall: http://stellar.mit.edu/S/course/11/fa15/11.205
- Or, first few labs from 11.188 - http://11.188/www16/labs last Spring (with ArcGIS 10.1)
- Plus some familiarity with quantiative reasoning (such as concurrent enrollment in 11.220: http://stellar.mit.edu/S/course/11/sp16/11.220)
- ArcGIS - download possible from MIT: http://ist.mit.edu/software-hardware?type=27 (MIT certificate required)
- Kerberos and Cisco VPN software from MIT:
http://ist.mit.edu/services/software/available-software
- needed for virtual private network access to MIT so ArcGIS license manager allows off-campus use
- File access (to class data locker at
/afs/athena.mit.edu/course/11/11.521/data):
- OpenAFS (for AFS network file access to class locker): http://www.openafs.org/
- Or, fetch, securefx (from MIT software site) or another secure ftp program to transfer files from class locker
- Open Source tools
- PostgresSQL relational database management software: http://www.postgresql.org/
- You may also want PostGIS for spatial operators, pgAdminIII for administration, and psqlodbc for ODBC connections
- SQuirreL SQL client: a java-based universal SQL client that
runs on Macs and PCs (in place of SQL*Plus for Oracle or pgAdmin
for Postgres)
- Available at: http://squirrel-sql.sourceforge.net/
- PostgresSQL relational database management software: http://www.postgresql.org/
- During lab time (after lab presentation) get help from me with personal software setup
- Most of you have limited familiarity with MS-Access
- Several online help pages and tutorials (besides those from Microsoft) will help you get more comfortable.
- Past lecture & Recitation Notes
- Relational database notes from 11.520 (Fall 2010): http://mit.edu/11.520/www/lectures/lecture5.html
- MS-Access notes by Lulu Xue and Shan Jiang: rec2_database_datafile.pdf
- Useful online 'business skill' tutorials by http://www.GCFLearnFree.org
- The Goodwill Community Foundation of East North Carolina provides these
- The MS-Access tutorials are here: http://www.gcflearnfree.org/access2010
- And, some useful pages on MS-Access query building are here:
- MIT also uses Skillsoft online training resources: http://ist.mit.edu/training/wbt (click 'Atlas' and search for 'ms-access'
Class Introduction - - spatial database management & geospatial services
- Desired spatial analysis skills
- Capitalize on new data streams
- from urban sensing, GIS repositories, administrative transaction records, etc.
- Use personal and parcel-scale data to examine spatial patterns
- of accessibility, housing affordability, vehicle miles traveled, etc.
- Study land use, transportation, and environmental interactions
- Anticipate the effects of alternative metropolitan growth scenarios
- Capitalize on new data streams
- Analytic and computational complications
- One-to-many issues
- multiple condos on a parcel, businesses in a building, etc.
- overlapping zones (census tracts, police/fire/school districts, watersheds, etc.)
- Complex, voluminous datasets
- cross-agency:
- land use, housing, assessing, transportation, utilities, etc.
- complex administrative transaction datasets:
- all housing sales, safety inspections, meter readings, urban sensing feeds, etc.
- complex transportation networks and modes
- major/minor roads, transit schedules and performance
- peak hour congestion
- car sharing, kiss-and-ride, mixed-mode, family dependencies
- cross-agency:
- Statistical autocorrelation
- modifiable areal unit problems (MAUP)
- requires geostatistical analysis
- One-to-many issues
- Methods and Skills learned in the class
- Spatial database management
- Relational tabular data model with SQL query language
- Geospatial tools for manipulating vector and raster data models
- Enterprise GIS and geospatial services
- Group level data sharing
- Use of database and map servers
- Map mashups
- Geostatistics (introduction)
- Kriging techniques, hot-spot analysis
- Spatial regression modeling using Stata and/or R
- Design of
GeoSpatial Databases
- How would you structure a city database for storing parcel, tax, zoning, assessment records?
- How would you embed locational information, provide access to basemaps, publish maps on the web, facilitate location-based services,benefit from crowdsourcing
- Spatial database management
Illustrative Example of One-To-Many Complications - Mass population density
- Prepare thematic map of population density
in Mass
- Shapefile of Mass municipalities - available
from MassGIS and (MIT Library Geodata Repository)
- State GIS Agency - MassGIS: http://www.mass.gov/mgis/
- Also available as shapefile (ma_towns00.shp) in class data locker: Z:\athena.mit.edu\course\11\11.521\data\
- Use ArcMap to plot thematic map of density = pop90 / area
- Shapefile of Mass municipalities - available
from MassGIS and (MIT Library Geodata Repository)
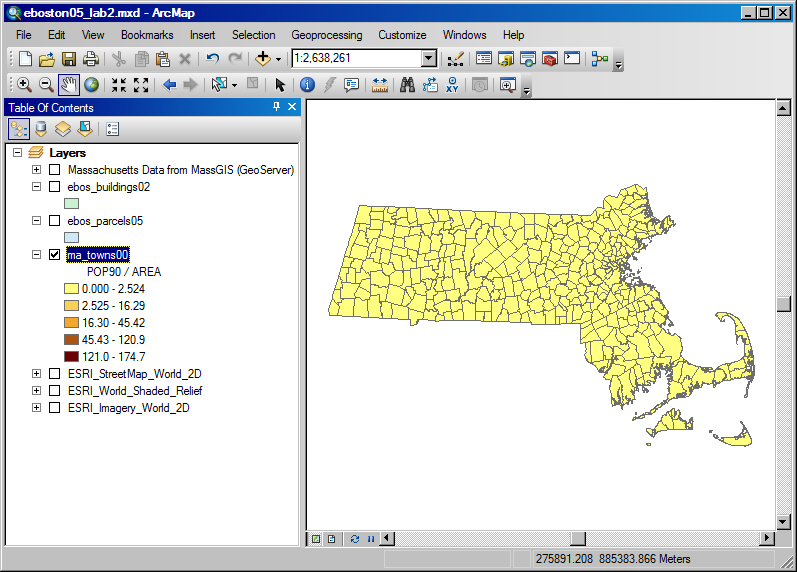
- Problem
- Dataset is fine, but simple density map is wrong
- densities are incorrect (too little variation across towns and highest values are far too high)
- Explore strategies for overcoming problem
- Data manipulation in ArcMap - need extra 'summarize' tables
- Data manipulation in MS-Access (then pull into ArcMap) - fix datatype problems
- Data manipulation in Postgres (then pull into ArcMap & Excel) - more complex but easily shareable
- See 11.520 lab exercise for further details of within-ArcMap solution
Using SQL queries to solve Mass 'density' computation problem
- In MA Town shapefile, some Towns have many parts (polygons) but the population counts are for the whole town:
select town_id, town, count(*) AS parts, avg(pop90) AS pop90, sum(area) AS area, 10000*(avg(pop90)/sum(area)) AS density from matown2000 group by town_id, town order by townTOWN_ID TOWN PARTS POP90 AREA DENSITY
---------- --------------------- ---------- ---------- ---------- ----------
85 EAST LONGMEADOW 1 13367 33675444 3.96936118
86 EASTHAM 10 4462 37154979.2 1.20091576
87 EASTHAMPTON 1 15537 35234084 4.40965061
88 EASTON 1 19807 75713048 2.61606163
89 EDGARTOWN 5 3062 74423017.1 .411431856
90 EGREMONT 1 1229 48896216 .251348693
91 ERVING 1 1372 37206844 .368749362
92 ESSEX 8 3260 37689239 .86496838
93 EVERETT 2 35701 8925302.06 39.9997667
etc...
- Instead of creating a new table, just create a view (that is, save the SQL statement):
create view v_madensity as
select town_id, town, count(*) as parts, avg(pop90) as pop90,
sum(area) as area, 10000*(avg(pop90)/sum(area)) as density
from matown2000
group by town_id, town
order by town;
- Finally, grab the 'jf.madensity' view from
Postgres into ArcMap, join to shapefile, and create density map
(people per hectare):
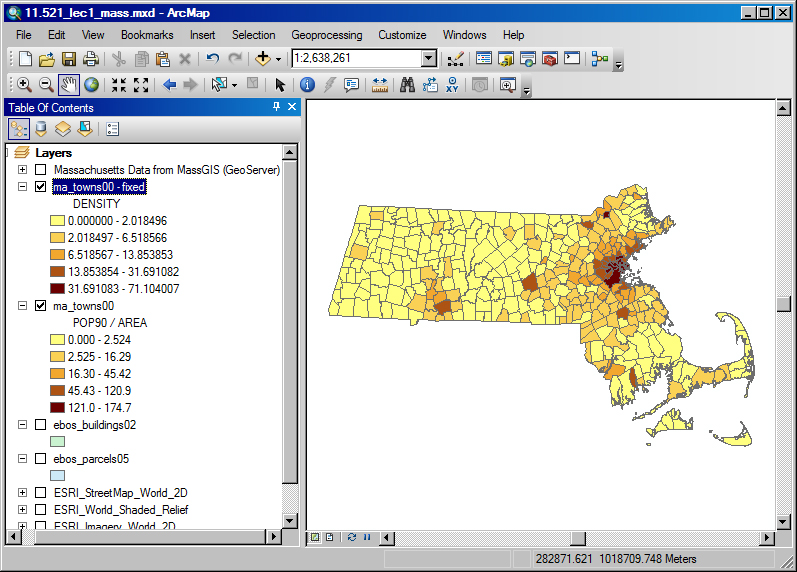
- Caveat: MS-Access does not permit complex SQL
expressions such as (avg(pop90)/sum(area) within a
'select' statement. Instead, you need to construct two queries:
one to aggregate and save the area of each town and another to
divide the town population by the total town area.
- In Postgres or PostgreSQL, you can do this in one SQL query.
- In Friday's optional lab, I will show how to use MS-Access together with ArcGIS to compute town-level densities for Mass.
Intro to Relational Model for tabular data
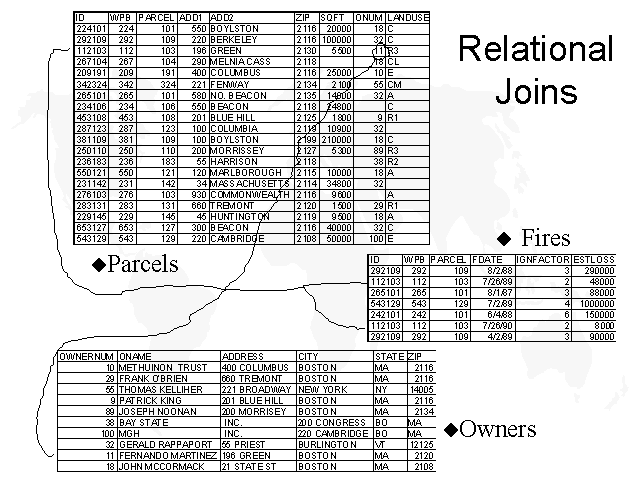
- Motivating questions regarding LANDUSE and
OWNERSHIP
- Who owns the parcels that had more than one fire during the past two years?
- Which blocks, containing at least 10 parcels with rental units, have had fires and building permits while they've had taxes in arrears?
- What vacant land in this neighborhood is suitable for redevelopment, sale to a neighbor, etc?
- How affordable is this neighborhood?
- What neighborhood businesses might be successful given the local demographics, existing business mix, etc.?
- In the relational model, ALL data are represented
as tables (as in the sample Parcel
Database )
- Each table can be stored or viewed as one 'flat file'
- Tables are comprised of rows and columns with
single entries in each cell
- Fully 'normalized' tables have additional properties we'll discuss later
- Simple queries select particular rows and
columns from a table (or several 'joined' tables)
- SELECT one-or-more columns
- FROM one-or-more tables
- WHERE various conditions are met
- ...
- Each table has a primary key, a unique identifier constructed from one or more columns
- A table can be linked (joined)
to another table if the values in one or more of its columns
can be matched to corresponding values in columns of another
table
- That is, the first table has column(s) that list the other table's primary key.
- Such an included column(s) is called a foreign key
- More complex queries relate (join) multiple tables using such primary/foreign key pairs
- The results of any given query are just another table! (so complex queries can involve sub-queries)
- One-to-many relations can be handled through the use of aggregation functions (sum, count, average, minimum, etc.)
- Many-to-many relations can be handled by adding additional 'matching' tables
{kind=link}
- Gets interesting when "rows" in
each table have different meaning and joining
tables involves one-to-many or many-to-many matches.
Consider:
- Census population by town vs. detailed MassGIS map of towns (with islands and separate parts due to rivers)
- house sales in a 'sales' table
- owners in a 'parcel' table
- tax payments in a 'tax' table
- Handling one-to-many and many-to-many relations
can be useful but tricky:
- Owners may own multiple properties; properties may sell more than once; etc.
- How can you join the tables in order to
- Find all owners that have been in arrears on their taxes within two years of buying a property
- See if new owners are more likely to be in arrears on their taxes for properties in a low (high) income census tract?
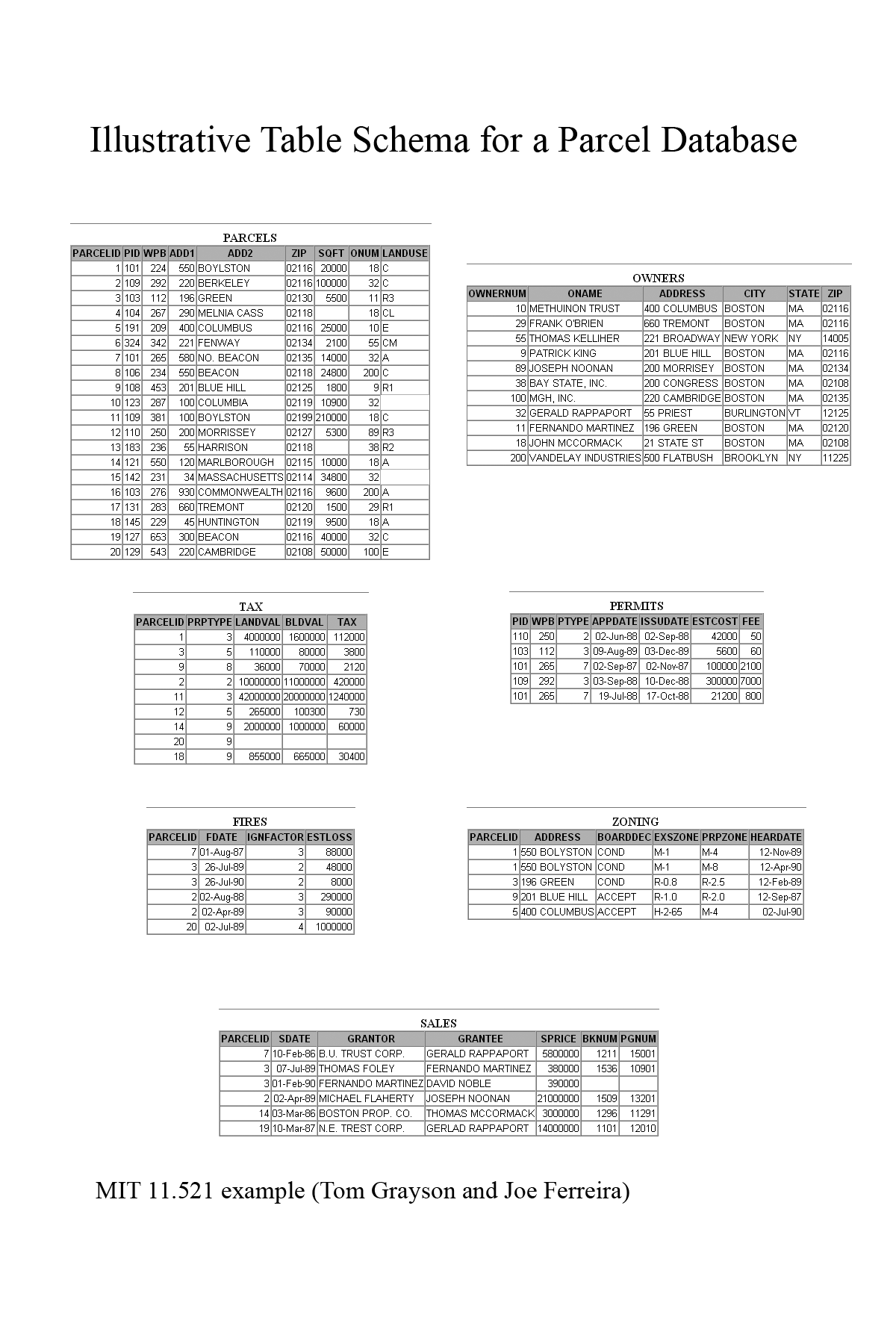
SQL Notes and the Sample Parcel Database
{kind=link}
- The Structured Query Language (SQL)
- lingua franca for network access to relational database servers
- Non-procedural language for doing relational algebra across inter-related tables
- More concepts and examples later on as needed
- The basic SELECT statement to query one or more tables:
SELECT [DISTINCT] column_name1[,
column_name2, ...]
FROM table_name1[,
table_name2, ...]
WHERE search_condition1
[AND search_condition2 ...]
[OR search_condition3...]
[GROUP BY column_names]
[ORDER BY column_names];
- Note that the order of the clauses matters! The clauses, if included, must appear in the order shown! Postgres will report an error if you make a mistake, but the error message (e.g., "ORA-00933: SQL command not properly ended") may not be very informative.
- Examining the Parcel
Database schema: table structure and data
types
- Why spin off an owner's table
- Why have an owner number
- Entity-relationship diagrams and normalization
- Database design issues and tradeoffs
- Sample SQL Queries using the Parcel Database
- Reviewing software setup and using
http://cronpgsql.mit.edu/phppgadmin
- Use of NULL: difference between IS NULL and = NULL
- Spooling files, fixed width fonts, use of COLUMN...
- Table prefixes - why use table alias
- distinguishing table owner
- distributed access to table column: jf.tax.onum@bulfinch.mit.edu
- Use of SQL Notes and Postgres help
Additional Notes - to be covered in more depth later on
- Spatial Database Management:
- Why use a more elaborate database
management system (DBMS)?
- Handling multi-table complexity (one-to-many, ...)
- Ease of documenting/replicating queries/results
- Performance
- Security
- Safe for multiple users
- Sharing data among applications
- Built-in data dictionary
- The Web as an information repository
- A rich information source but a loosely structured collection of relatively unstructured data
- Hard to find what you want without search engines and portals to index and structure the information and standardize the query process
- Hard to utilize and extend knowledge on the Web without controlling/copying it (broken links, complex parsing/extraction, limited quality control, etc.)
- Web 2 efforts (user-developed content) are limited (without a compeling business model for software investment)
- Semantic Web efforts are trying to enable higher levels of automatable abstraction and cross-referencing
- Often need more highly structured data repositories (and query tools)
- Desktop tools such as Excel, MS-Access, Filemaker, etc. handle personal database management needs (mailing lists, survey results, etc.)
- Complex software often needed to manage multi-user access to 'persistent data'
- Types of databases: single-user, corporate, engineering, science, image/video, geographic, ...
- Issues: performance, metadata, user interface, data structure, concurrency, distributed, ...
- Other 'big-system' issues: Security/reliability/integrity requirements (parcel ownership records, census data, major roads)
- Other complications: transaction processing, data warehousing, online analytic processing, data mining, ...
- Our focus: data structure issues and query capabilities
- Planner's perspective and GIS implications
- Complex, semi-structured questions that involve one-of-a-kind analyses:
- Which buildings in Boston have more than 1000 square feet of retail space and are located in neighborhoods with above-average incomes?
- What level of trace gas exposures can be anticipated from EPA's Toxic Release Inventory sites?
- Have 'move-to-opportunity' families had better job-retention experience than inner city residents who receive job training and housing assistance?
- Recognize that planner needs are different from those of City Hall
- (corporate) vs. Professional (end-user) needs/goals
- city hall (enterprise) issues -- efficient data entry/retrieval/accuracy/security using tools that facilitate automation, maintenance, access control, and simple interfaces for edits, reports, common queries
- planning professional issues -- startup/flexibility/modeling/integration/power using tools that can extract, merge, transform data; handle time series; and support complex queries
- Structured vs. unstructured databases
- Highly structured data - Census data parcel records, etc. with SQL query tools
- Unstructured data - Web pages with search engines and 'free-format text retrieval' tools
- GIS 'demos' are easy but spatial analysis is hard
- No sweat if the data you want are already cleaned, parsed, and precisely suited to your question
- Useful spatial analyses involves judicious mixing and matching data from official and local sources
- Tapping into distributed, non-static databases can get complex for non automatable tasks
-
- Data types, parsing, & mix-n-match issues
- Alphanumeric: Character strings; integers, floating point numbers, dates, binary codes, ...
- Multi-dimensional: Images, maps, spatial objects, 3D models, video, math models, ...
- Encoding/parsing addresses, zips, census tracts (77 Mass Ave, Cambridge, MA 02139)
- Storage space, column headers (metadata), null/missing values
-
- GIS complexities
- Handling one-to-many
relationships
- Computing Mass density using town map from MassGIS (on MIT Libraries geodata server)
- Condos and mixed used properties on a single parcel
- Other complexities when you 'roll your own'
and/or share data online
- Using someone else's administrative
data (cross-referencing parcel, tax,
permitting information)
- Group work: Sharing data that changes over time
- Handling complex queries: which properties flipped quickly within a year of foreclosure are they concentrated in a few neighborhoods
- Accumulating reusable knowledge: saving and sharing data edits and reinterpretation
- Using someone else's administrative
data (cross-referencing parcel, tax,
permitting information)
- Handling one-to-many
relationships
- Where we're headed:
- Geospatial web services (WMS and WFS protocols...)
- distributed access to shared databases (3D visualization, mashups, and modeling)
- middleware tools to handle mix-n-match complexities of data sharing and reuse
- new client/server split to enable location-based services for mobile computing
- Qualities of a Good Database Design
- Tables reflect real-world structure of the problem
- Can represent all expected data over time
- Avoids redundant storage of data items
- Provides efficient access to data
- Supports the maintenance and integrity of data over time
- Clean, consistent, and easy to understand
- Note: These objectives are sometimes contradictory!
Developed by Joseph Ferreira and Tom
Grayson.
Last modified: Rounaq Basu February 7, 2018