Problem 1 (5+5+5+5+5 points)¶
In this problem, you will use least-square fitting to examine the original 1662 data demonstrating Boyle's law: the volume $v$ of a gas is inversely proportional to the pressure $p$ (for constant mass and temperature).
In that experiment, described here (UVa), Robert Boyle measured the volume of air trapped in the sealed end of a glass tube as they poured mercury in the other end. The total pressure $p$ on the trapped air is proportional to the height of the mercury, plus the height of mercury balancing atmospheric pressure (as measured by a Torricelli barometer). They found that the volume of the gas varied inversely with $v$. The experiment is depicted here:
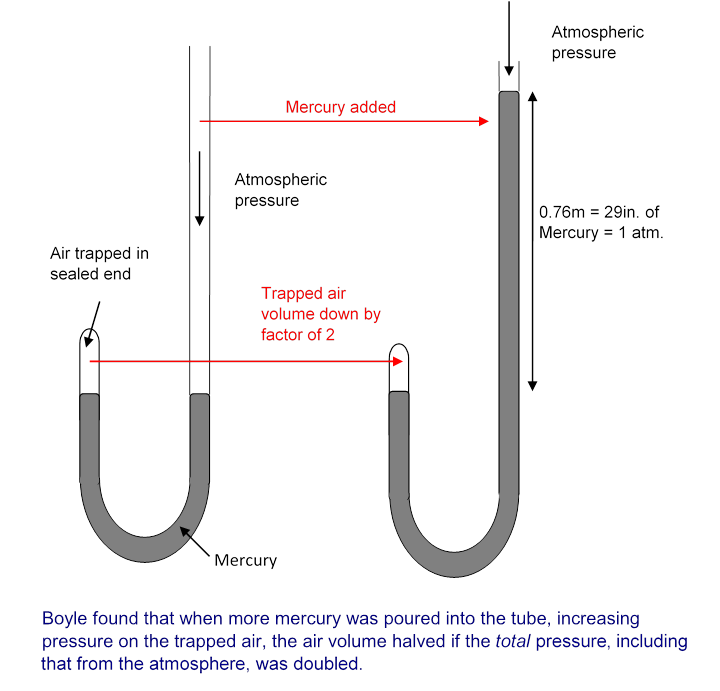
(a) Open Boyle's 1662 manuscript, find the chapter on the "new experiment", and locate the experimental data, which is labelled A Table of the Condensation of Air. Extract the data from the first column "A" and enter it into a Julia array v below — this is the height of the air column, proportional to its volume. (There is a second column "A" that contains the same data divided by 4.) Extract the data from the column "D" and enter it into a Julia array p below — this is the height of the mercury column (including the amount corresponding to atmospheric pressure), and is proportional to the total pressure.
(b) Perform a least square fit to the model $v = \alpha / p$, i.e. find $\alpha$ that minimizes the sum of the squared error $\sum_k (v_k - \alpha/p_k)^2$ for Boyle's data points $(p_k, v_k)$. (Note: in Julia, you can make a vector of the inverse pressures with 1 ./ p.) Plot the data and the fit ($v$ vs. $p$) using the provided code below.
Note: if you find yourself using calculus here or in subsequent parts, you are re-inventing the wheel — we already derived how to minimize the squared error in class, so please re-write it as a matrix least-squares problem and use the 18.06 results.
(c) Perform a least-square fit to a more complicated model, $v = \frac{\alpha}{p} + v_0$, for fit parameters $\alpha$ and $v_0$. (That is, suppose that Boyle was slightly wrong, and that there is a minimum volume $v_0$ even for $p \to \infty$, similar to van der Waals equation.) What $\alpha$ and $v_0$ do you obtain?
(d) If the gas in Boyle's experiment exactly obeyed Boyle's law, i.e. if the theoretically correct $v_0$ is 0 in part (c), would you expect to get $v_0 = 0$ from a least-square fit of experimental data? Why or why not? (No detailed math please, just a sentence or two of explanation.)
(e) Alternatively, suppose we don't know the power law in our model: suppose $v = \alpha p^n$ for an unknown power $n$ and an unknown coefficient $\alpha$. This depends nonlinearly on $n$, so at first glance it may seem that we cannot do a linear least-square fit using 18.06 techniques. However, show that $\log v$ depends linearly on two unknown fit parameters in this model, and hence do a least-square fit of $\log v_k$ to the log of the model to estimate the parameters $\alpha$ and $n$ from Boyle's data.


