Assignment 3: Grid of Resistors
Due Tuesday March 12
(Note timers and a few other things are starting to be understood.
If you find anything cool, let me know. Your job is to educate
yourself and me in the process! I just hand over the machines
and ideas to get you started. Getting the code to work
in higher dimenstions is relatively easy. Getting performance
may be hard.)
Life is too short to spend writing do loops.
-- Cleve Moler, 1993
The main goal of this assignment is to convince you of the ease of use of the
data parallel programming model. For those problems that lend themselves to
this model, programming a parallel machine can be easier than
programming serial machines. Of course, data parallel languages
can execute on serial machines, but parallel computers have
promoted their use.
Step 1: Let's get used to the SGI machines. Login to
tonka. Why not type the top command that
we learned about from Jack Perry, and even read
the man page.
After doing the xhost/xdisplay thing
type iiv
to see the book shelf.
(I hate acronyms. This one stands for IRIS InSight Viewer.)
You might want to drag down the personal shelf, then
the book shelf. Perhaps take a look at the Fortran
90 Programmer's Guide. Type to see what
SGI's debugger looks like. The second book on
the SGI developer shelf (Develop Magic: Debugger
User's Guide) explains how to use cvd, but you
may not need to read it. The variable browser
is very cool.
Step 2: We will be writing this code using
High Peformance Fortran. A necessary first
step is to issue
some magic incantations.
in your .cshrc file.
See the documentation mentioned on this page.
Next step is grabbing the code:
cp ~edelman/grid_homework/sor_cshift.hpf/*.hpf
You should obtain four hpf files.
Each one of these files is performing the
same operation. It is computing the effective
resistance and voltages of a grid of resistors.
They may all be compiled with the pghpf
command. BU's
HPF guide is terrific. Skim chapters 1 through 3.
You will find out that to run the code on four
processors you can type
sor_cshift -pghpf -np 4
and also you can get statistics via
sor_cshift -pghpf -np 4 -stat cpus
,
but you may want to run fewer iterations.
See
Chapter 3 specifically.
Each program is only one page long.
Also please note the assignment checklist at the end
of this document.
You should also take a look at the .f90 versions
of the same programs. They may be compiled with
the f90 compiler. For me to turn the
hpf codes into f90, all I needed to do was
change the initial comment character, change
the continuation lines, and add the D0 after
the constant for pi. (Do a diff
to see for yourself.) I did not notice the D0
until I figured out that the two programs
were giving slightly different answers. A
previous student in this class (Pete McCorquodale)
discovered a similar necessity when porting MPI
programs to the SP2.
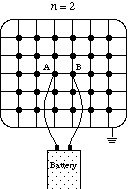
The problem is to compute the voltages and the effective resistance
of a 2n+1 by 2n+2 grid of 1 ohm resistors if a battery is
connected to the two center points. This is a discrete version of finding the
lines of force using iron filings for a magnet.
A contour plot of the answer (for a larger value of n) looks like
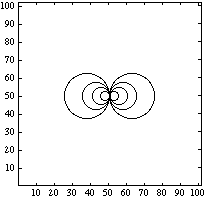
The method of solution that we will use here is successive
overrelaxation (SOR) with red-black ordering. This is certainly not the
fastest way to solve the problem, but it does illustrate many important
programming ideas.
It is not so important that you know the details of SOR. (Some of the basic
ideas may be found on pages 407-409 of Gil Strang's Introduction to
Applied Mathematics, somewhat more in depth discussion may be found any
serious numerical analysis text such as Stoer and Bulirsch's Introduction
to Numerical Analysis.) What is important is that you see that the nodes
are divided in half into red nodes and black nodes. During the first pass,
the red nodes obtain the voltages as a weighted average of their original
voltage, the input (if any) and the four surrounding black nodes. During
the second pass, the black nodes obtain voltages from the four surrounding red
nodes. In the infinite limit, the process converges to the correct answer.
Let us have a look at the first two programs sor_cshift and
sor_eoshift. These programs define a 2n+1 by 2n+2 matrix
v for voltages, and two logical arrays, red and black for
the red/black nodes. The first and last rows and columns (the boundary) are
never modified, they are "grounded", have voltage 0. The difference
in the two programs is only that while in the first one the voltage of the
neighbors is added by cshift, the second uses eoshift for the
same thing. In 1994 on the CM5,
we assigned this problem to 18.337 and found a big
difference in the performance in the two codes. It is a nuisance that such
small choices can radically affect the performance.
In 1995, we
saw that the cshift version is only slightly faster than the eoshift
version.
The third program sor_arraysection uses a quite different approach:
both reds and blacks are determined as two array section ("odds and
evens"). Information from neighbors is obtained directly through
shifting the array sections.
We would like you to time say 200 (or whatever you like) iterations by the
CM_timers. The time for array sections
on the CM5 wass very bad; array
sections as they were implemented on the CM-5 incurred
a huge amount of overhead.
Your first programing assignment is the following: implement the analogous
problem on a 2n+1 by 2n+1 by 2n+2 grid in three
dimensions. Pick whichever code or code you prefer.
This may still be done with two colors. The value of the optimal
mu you have to use is
2*cos(pi/(2*n))+cos(pi/(2*n+1)))/3.
Next solve the problem in four dimensions, with mu =
(3*cos(pi/(2*n))+cos(pi/(2*n+1)))/4. Can you guess the
effective resistances of the various meshes as n --> infinity ?
Let's get smarter. Look at chapters 4 and 5 of the
HPF manual and let's see if with a few compiler directives,
we can't improve the performance tons.
Now this gets harder. In our cshift and eoshift programs we use the
where(reds) statement. Though you might have imagined that the compiler
is smart enough to work in time proportional to the active part (i.e. the
"true" part) of the statement, unfortunately it is not. In fact, the
time spent is proportional to the entire size and even more time for
conditioning.
We would like you to improve the program by putting all the red nodes into one
array called red and all the black nodes in the same size array
black. The data arrangement is given in Figure 1 for the general case,
and in Figure 2 for n=4. For simplicity we require n to be even.
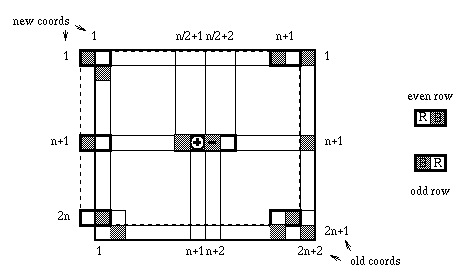
Figure 1. The data arrangement with 2 arrays
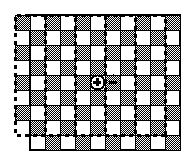
nFigure 2. The case of Figure 1, for n = 4
This arrangement is in our program sor_2arrays. Unfortunately, timing
is not improved; use the timers to discover which is the really slow part of
the program. Try to see if you can improve the program, using two arrays and
CSHIFT only. Or try using four arrays, two for the even rows of red and
black, two for the odd rows.
Assignment Checklist
- Copy the four files
- Understand and time sor_cshift and sor_eoshift
- Repeat for sor_arraysection
- Extend sor to three and four dimensions
Include your min, avg, max, and total user times for
the run with the best total user time and the best
max time for n=32 in three dimensions.
- What is the resistance for an infinite grid in d
dimensions?
- Understand and time sor_2arrays
For the ambitious:
- Improve on sor_2arrays