Problem .
Calculate the latency (total delay from first bit sent to last bit
received) for the following:
Sender and receiver are separated by two 1-Gigabit/s links and a
single switch. The packet size is 5000 bits, and each link introduces
a propagation delay of 10 microseconds. Assume that the switch begins
forwarding immediately after it has received the last bit of the
packet and the queues are empty.
For each link, it takes 1 Gigabits/5Kb = 5 micro seconds to transmit the
packet on the link, after which it takes an additional 10 micro
seconds for the last bit to propagate across the link. Thus, with only
one switch that starts forwarding only after receiving the whole
packet, the total transfer delay is two transmit delays + two
propagation delays = 30 microseconds.
Same as (A) with three switches
and four links.
For three switched and thus four links, the total delta is four
transmit delays + four propagation delays = 60 microseconds.
Problem . Little's Law.
At the supermarket a checkout operator has on average 4
customers and customers arrive every 2 minutes. How long must each
customer wait in line on average?
Throughput time = 4 customers * 1/2 customer/minute = 8 minutes
A restaurant holds about 60 people, and the average person will
be in there about 2 hours. On average, how many customers arrive per
hour? If the restaurant queue has 30 people waiting to be seated, how
long does each person have to wait for a table?
Rate = 60 customers / 2 hrs = 30 customers / hr
Waiting time = 1 hour
A fast-food restaurant uses 3,500 kilograms of
hamburger each week. The manager of the restaurant wants to ensure
that the meat is always fresh, i.e., the meat should be no more than two
days old on average when used. How much hamburger should be kept in
the refrigerator as inventory?
Rate = 3,500 kilograms per week (= 500 kilograms per day)
Average flow time = 2 days
Average inventory = Rate x Average flow time = 500 x 2 = 1,000 kilograms
(Note that the variables are all in the same time frame i.e. days)
A hardware vendor manufactures $300 million worth of PCs per
year. On average, the company has $45 million in accounts receivable.
How much time elapses between invoicing and payment?
Rate= $300 million per year
Average "inventory" = $45 million
Average "flow time" = 45 / 300 per year = .15 years = 1.8 months = 54 days
Problem .
Consider the following networks: network I (containing nodes A, B, C) and network II
(containing nodes D, E, F).
The Distance Vector Protocol described in class is used in both
networks. Assume advertisements are sent every 5 time steps, all
links are fully functional and there is no delay in the links. Nodes
take zero time to process advertisements once they receive them. The
HELLO protocol runs in the background every time step in a way that
any changes in link connectivity are reflected in the next DV
advertisement. We count time steps from t=0 time steps.
Please fill in the following table:
Event
Number of time steps
A's routing table has an entry for B
A's routing table has an entry for C
D's routing table has an entry for E
F's routing table has an entry for D
A's routing table has an entry for B: 5 time steps
A's routing table has an entry for C: 10 time steps
D's routing table has an entry for E: 5 time steps
F's routing table has an entry for D: 5 time steps
Now assume the link B-C fails at t = 51 and link D-E fails
at t = 71 time steps. Please fill in this table:
Event
Number of time steps
B's advertisements reflect that C is unreachable
A's routing table reflects C is unreachable
D's routing table reflects a new route for E
B's advertisements reflect that C is unreachable: 55 time steps
A's routing table reflects C is unreachable: 55 time steps
D's routing table reflects a new route for E: 75 time steps
Problem .
Alyssa P. Hacker manages MIT's internal network that runs link-state
routing. She wants to experiment with a few possible routing
strategies. Of all possible paths available to a particular
destination at a node, a routing strategy specifies the path that must
be picked to create a routing table entry. Below is the name Alyssa
has for each strategy and a brief description of how it works.
MinCost: Every node picks the path that has the smallest sum of link
costs along the path. (This is the minimum cost routing you
implemented in the lab).
MinHop: Every node picks the path with the smallest number of hops
(irrespective of what the cost on the links is).
SecondMinCost: Every node picks the path with the second lowest sum
of link costs. That is, every node picks the second best path with
respect to path costs.
MinCostSquared: Every node picks the path that has the smallest sum of
squares of link costs along the path.
Assume that sufficient information (e.g., costs, delays,
bandwidths, and loss probabilities of the various links) is exchanged
in the link state advertisements, so that every node has complete
information about the entire network and can correctly implement the
strategies above. You can also assume that a link's properties don't
change, e.g., it doesn't fail.
Help Alyssa figure out which of these strategies will work
correctly, and which will result in routing with loops. In case of
strategies that do result in routing loops, come up with an example
network topology with a routing loop to convince Alyssa.
Answer: All except SecondMinCost will work fine.
To see why SecondMinCost will not work: consider the triangle topology
with 3 nodes A, B, D, and equal cost on all the links. The second
route at A to D is via B, and the second best route at B to D is via
A, resulting in a routing loop.
How would you implement MinCostSquared in a distance-vector
protocol?
To implement MinCostSquared, your integrate_announcement routine
would add the square of the link cost (instead of just the link cost)
to any route costs advertised over that link.
Problem .
Consider the following chain topology:
A ---- B ----- C ---- D ---- E
A is sending packets to E using a reliable transport protocol. Each
link above can transmit one packet per second. There are no queues or
other sources of delays at the nodes (except the transmission delay of
course).
What is the RTT between A and E?
8 seconds
What is the throughput of a stop-and-wait protocol at A in the
absence of any losses at the nodes?
1/8 pkts/s
If A decides to run a sliding window protocol, what is the optimum
window size it must use? What is the throughput achieved when using
this optimum window size?
optimum window = 8 pkts, optimum throughput = 1 pkt/s
Suppose A is running a sliding window protocol with a window size
of four. In the absence of any losses, what is the throughput at E?
What is the utilization of link B-C?
throughput=0.5 pkts/s, utilization=0.5
Consider a sliding window protocol running at the optimum window
size found in part 3 above. Suppose nodes in the network get
infected by a virus that causes them to drop packets when odd
sequence numbers. The sliding window protocol starts
numbering packets from sequence number 1. Assume that the sender
uses a timeout of 40 seconds. The receiver buffers out-of-order
packets until it can deliver them in order to the application. What
is the number of packets in this buffer 35 seconds after the sender
starts sending the first packet?
Answer: 7.
With a window size of 8, the sender sends out packets 1--8 in the
first 8 seconds. But it gets back only 4 ACKs because packets 1,3,5,7
are dropped. Therefore, the sender transmits 4 more packets (9--12) in
the next 8 seconds, 2 packets (13--14) in the next 8 seconds, and 1
(sequence number 15) packet in the next 8 seconds. Note that 32
seconds have elapsed so far. Now the sender gets no more ACKs because
packet 15 is dropped, and it stalls till the first packet times out at
time step 40. Therefore, at time 35, the sender would have transmitted
15 packets, 7 of which would have reached the receiver. But because
all of these packets are out of order, the receiver's buffer would
have 7 packets.
Problem .
Which of these statements are true for correctly implemented versions
of unslotted Aloha, slotted Aloha, and Time Division Multiple Access
(TDMA) as discussed in 6.02?
A. When the number of nodes is large, unslotted Aloha has a lower
maximum throughput than slotted Aloha.
B. A correctly implemented TDMA protocol has no packet collisions.
C. There exists no offered load pattern for which TDMA has lower
throughput than slotted Aloha.
A and B are true. C is false.
Problem .
Binary exponential backoff is a mechanism used in some MAC protocols.
Which of the following statements is correct?
A. It ensures that two nodes that experience a collision in a
time slot will never collide with each other when they each
retry that packet.
B. It ensures that two or more nodes that experience a collision in a
time slot will experience a lower probability of colliding with each
ther when they each retry that packet.
C. It can be used with slotted Aloha but not with carrier sense multiple access.
D. Over short time scales, it improves the fairness of the
throughput achieved by different nodes compared to not using the
mechanism.
B is true. The others are false.
Problem .
Consider a shared medium with N nodes running the slotted Aloha MAC
protocol without any backoffs. A "wasted slot" is one in which no
node sends data. The fraction of time during which no node uses the
medium is the "waste" of the protocol.
If the sending probability is p, what is the waste? What are
the smallest and largest possible values of the waste?
(1-p)N. 0 and 1.
If the Aloha sending probability, p, for each node is picked so
as to maximize the utilization, what is the corresponding waste?
1/e --> same as the utlization!
Problem .
Alyssa and Ben are all on a shared medium wireless network running a
variant of slotted Aloha. Their computers are configured such that Alyssa is
1.5 times as likely to send a packet as Ben. Assume that both computers are
backlogged.
For Alyssa and Ben, what is their probability of transmission
such that the utilization of their network is maximized?
With just two nodes U = (A's throughput + B's throughput)/max rate.
max rate is 1 packet per time step (slotted Aloha)
find max U by differentiating and setting to 0, solving for p
0 = 2.5 - 6p => p = 2.5/6 = 5/12
So P_a = 5/8, P_b = 5/12.
What is the maximum utilization?
Determine Umax by substituting 5/12 for p in equation for U in part A.
Umax = (2.5)(5/12) - (3)(25/144) = 25/48 = 0.5208
Problem .
True or false?
Assume that the shared medium has N nodes and they are always
backlogged.
In a slotted Aloha MAC protocol using binary exponential backoff,
the probability of transmission will always eventually converge to some
value p, and all nodes will eventually transmit with probability p.
False - In a binary exponential backoff, the probability of
transmission constantly changes. If the a transmission succeeds, then
the probability goes up. If the transmission fails, the probability
goes down.
Using carrier sense multiple access (CSMA), suppose that a node
"hears" that the channel is busy at time slot t. To maximize utilization,
the node should not transmit in slot t and instead transmit the packet
in the next time slot with probability 1.
False - The node should not transmit at time t+1 with 100%
probability. Other nodes may have also "heard" that the channel is
busy and would want to send a packet at time t+1. So the node should
send with a probability less than 100% to reduce the possibility of a
collision.
There is some workload for which an unslotted Aloha with
perfect CSMA will not achieve 100% utilization.
True - Multiple nodes may think that the channel is idle and send a
packet at the same time, resulting in a collision. Thus, the
utilization can never reach 100%.
Problem . Time-domain multiplexing.
Eight Cell Processor cores are connected together with a shared
bus. To simplify bus arbitration, Ben Bittdidle, young IBM
engineer, suggested time-domain multiplexing (TDM) as an arbitration
mechanism. Using TDM each of the processors is allocated a
equal-sized time slots on the common bus in a round-robin fashion.
He's been asked to evaluate the proposed scheme on two types of
applications: 1) core-to-core streaming, 2) random loads.
1) Core-to-core streaming setup: Assume each core has the same stream bandwidth requirement.
Help Ben out by evaluating the effectiveness (bus utilization) of
TDM under these two traffic scenarios.
1) All cores have same bandwidth requirements during streaming, so,
bus utilization is 100%
2) Each core is given 12.5% of bus bandwidth, but not all cores can
use it, and some need more than that. So bus utilization is: 12.5% +
12.5% + 10% + 5% + 1% + 3% + 1% + 12.5% = 57.5%
Problem .
Circuit switching and packet switching are two different ways of
sharing links in a communication network. Indicate True or False for
each choice.
Switches in a circuit-switched network process connection establishment and
tear-down messages, whereas switches in a packet-switched network do not.
True.
Under some circumstances, a circuit-switched network may prevent some senders
from starting new conversations.
True.
Once a connection is correctly established, a switch in a circuit-switched network
can forward data correctly without requiring data frames to include a destination address.
True.
Unlike in packet switching, switches in circuit-switched networks do not need
any information about the network topology to function correctly.
False.
Problem .
Which of the following tasks does a router R in a packet-switched network perform when it gets
a packet with destination address D? Indicate True or False for each choice.
R looks up D in its routing table to determine the outgoing link.
True.
R sends out a HELLO packet or a routing protocol advertisement to its neighbors.
False.
R calculates the minimum-cost route to destination D.
False.
R may discard the packet.
True.
Problem .
Over many months, you and your friends have painstakingly collected a
1,000 Gigabytes (aka 1 Terabyte) worth of movies on computers in your
dorm (we won't ask where the movies came from). To avoid losing it,
you'd like to back the data up on to a computer belonging to one of
your friends in New York.
You have two options:
A. Send the data over the Internet to the computer in New York. The data rate for transmitting
information across the Internet from your dorm to New York is 1 Megabyte per second.
B. Copy the data over to a set of disks, which you can do at 100
Megabytes per second (thank you, firewire!). Then rely on the US
Postal Service to send the disks by mail, which takes 7 days.
Which of these two options (A or B) is faster? And by how much?
Method A takes (1000 * 109 bytes)/(106 bytes/s) = 11.5 days
Method B takes (1000 * 109 bytes)/(100 * 106 bytes/s) + 7 days = 7.1 days
Method B is 4.4 days faster than Method A!
Problem .
Alice and Bob are responsible for implementing Dijkstra's
algorithm at the nodes in a net- work running a link-state
protocol. On her nodes, Alice implements a minimum-cost algorithm. On
his nodes, Bob implements a "shortest number of hops"
algorithm. Give an example of a network topology with 4 or more nodes
in which a routing loop occurs with Alice and Bob's
implementations running simultaneously in the same network. Assume
that there are no failures.
(Note: A routing loop occurs when a group
of k ≥ 1 distinct nodes, n_0 , n_1 , n_2 , …, n_(k-1) have routes
such that n_i's next-hop (route) to a destination is n_(i+1 mod k).
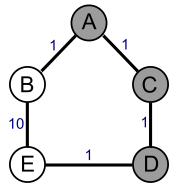
In the picture below, the grey nodes (A in particular) run
Bob's algorithm (shortest number of hops), while the white
nodes (B in particular) run Alice's (minimum-cost).
Suppose the destination is E. A will pick B as its next hop because
ABE is the shortest path. B will pick A as its next hop because BACDE
is the minimum-cost path (cost of 4, compared to 11 for the ABE
path). The result is a routing loop ABABAB...
Problem .
Network designers generally attempt to deploy networks that don't have
single points of failure, though they don't always succeed. Network
topologies that employ redundancy are of much interest.
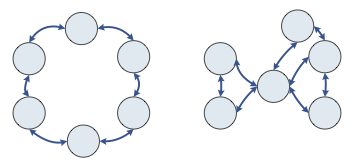
A. Draw an example of a six-node network in which the failure of a
single link does not disconnect the entire network (that is, any node
can still reach any other node).
B. Draw an example of a six-node network in which the failure of
any single link cannot disconnect the entire network, but the failure
of some single node does disconnect it.
C. Draw an example of a six-node network in which the failure of
any single node cannot disconnect the entire network, but the failure
of some single link does disconnect it.
Note: Not all the cases above may have a feasible example.
Here is an example topology for part A (left) and B (right).
C. Impossible. If the failure of some link disconnects the network,
then pick a node adjacent to that link and fail it. The link in
question will fail, and the network will be disconnected, violating
the condition that the failure of any single node cannot disconnect
the network.
Problem .
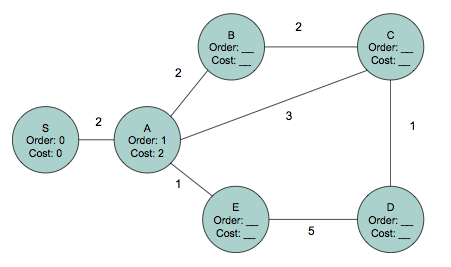
Consider the network shown below. The number near each link is its cost.
We're interested in finding the shortest paths (taking costs into
account) from S to every other node in the network. What is the
result of running Dijkstra's shortest path algorithm on this network?
To answer this question, near each node, list a pair of numbers: The
first element of the pair should be the order, or the iteration of the
algorithm in which the node is picked. The second element of each pair
should be the shortest path cost from S to that node.
To help you get started, we've labeled the first couple of nodes: S
has a label (Order: 0, Cost: 0) and A has the label (Order: 1, Cost:
2).
A: order = 1, cost = 2
E: order = 2, cost = 3
B: order = 3, cost = 4
C: order = 4, cost = 5
D: order = 5, cost = 6
Problem .
Consider any two graphs(networks) G and G' that are identical except
for the costs of the links. Please answer these questions.
The cost of link l in graph G is c_l > 0, and the cost of
the same link l in Graph G' is k*c_l, where k > 0 is a constant
and the same scaling relationship holds for all the links.
Are the shortest paths between any two nodes in the two graphs
identical? Justify your answer.
Yes, they're identical. Scaling all the costs by a constant factor doesn't
change their relative size.
Now suppose that the cost of a link l in G'
is k*c_l + h, where k > 0 and h > 0 are
constants. Are the shortest paths between any two nodes in the two
graphs identical? Justify your answer.
No, they're not necessarily identical. Consider two paths between nodes A and
B in graph G. One path takes 3 hops, each of cost 1, for a total cost of 3. The
other path takes 1 hop, with a cost of 4. In this case, the shortest path between
nodes A and B is the first one.
Consider k=1 and h=1 and compute the costs and shortest paths in G'. Now the
3-hop path has cost 6 and the 1-hop path has cost 5. In G' the shortest path is
the second path.
Problem .
Ben Bitdiddle implements a reliable data transport protocol intended
to provide "exactly once" semantics. Each packet has an 8-bit
incrementing sequence number, starting at 0. As the connection
progresses, the sender "wraps around" the sequence number once it
reaches 255, going back to 0 and incrementing it for successive
packets. Each packet size is S = 1000 bytes long (including all packet
headers).
Suppose the link capacity between sender and receiver is C = 1
Mbyte per second and the round-trip time is R = 100 milliseconds.
What is the highest throughput achievable if Ben's
implementation is stop-and-wait?
The highest throughput for stop-and-wait is (1000 bytes)/(100ms) =
10 Kbytes/s.
To improve performance, Ben implements a sliding window
protocol. Assuming no packet losses, what should Ben set the window
size to in order to saturate the link capacity?
Set the window size to the bandwidth-delay product of the link, 1 Mbyte/s
* 0.1 s = 100 Kbytes.
Ben runs his protocol on increasingly higher-speed bottleneck
links. At a certain link speed, he finds that his implementation stops
working properly. Can you explain what might be happening? What
threshold link speed causes this protocol to stop functioning
properly?
Sequence number wraparound causes his protocol to stop functioning
properly. When this happens, two packets with different content but
the same sequence number are in-flight at once, and so an ack for the
firstt spuriously acknowledges the second as well, possibly causing
data loss in Ben's "reliable" protocol. This happens when
Problem .
A sender S and receiver R are connected over a network that has k
links that can each lose packets. Link i has a packet loss rate of p_i
in one direction (on the path from S to R) and q_i in the other (on the
path from R to S). Assume that each packet on a link is received or
lost independent of other packets, and that each packet's loss
probability is the same as any other's (i.e., the random process
causing packet losses is indepedent and identically distributed).
Suppose that the probability that a data packet does not reach
R when sent by S is p and the probability that an ACK packet sent by R
does not reach S is q. Write expressions for p and q in terms of the
p_i's and q_i's.
p = 1 - (1 - p_1)(1 - p_2)…(1 - p_k) and
q = 1 - (1 - q_1)(1 - q_2)…(1 - q_k)
If all p's are equal to some value α << 1 (much smaller
than 1), then what is p (defined above) approximately equal to?
p = 1 - (1 - &alpha)k ≈1 - (1 - kα) = kα
Suppose S and R use a stop-and-wait protocol to
communicate. What is the expected number of transmissions of a packet
before S can send the next packet in sequence? Write your answer in
terms of p and q (both defined above).
The probability of a packet reception from S to R is 1-p and the probability of an ACK reaching
S given that R sent an ACK is 1-q. The sender moves from sequence number k to k + 1 if the
packet reaches and the ACK arrives. That happens with probability (1-p)(1-q). The expected
number of transmissions for such an event is therefore equal to 1/((1-p)(1-q)).
Problem .
On the Internet, TCP checksums all the data it sends even when each
link on the path has its own CRC-based checksum. Should TCP save the
network bandwidth consumed by its checksums over such paths and get
rid of it?
No. Errors in the switch or the end point's network layer
could cause the data to be corrupted even though each link has good
error detection.
Problem .
Consider a 40 kbit/s network link connecting the earth to the
moon. The moon is about 1.5 light-seconds from earth.
1 Kbyte packets are sent over this link using a stop-and-wait
protocol for reliable delivery, what data transfer rate can be
achieved? What is the utilization of the link?
Stop-and-wait sends 1 packet per round-trip-time so the data
transfer rate is 1 Kbyte/3 seconds = 333 bytes/s = 2.6 Kbit/s.
The utilization is 2.6/40 = 6.5%.
If a sliding-window protocol is used instead, what is the
smallest window size that achieves the maximum data rate? Assume that
error are infrequent. Assume that the window size is set to achieve
the maximum data transfer rate.
Achieving full rate requires a send window of at least
Consider a sliding-window protocol for this link with a window
size of 10 packets. If the receiver has a buffer for only 30 undelivered
packets (the receiver discards packets it has no room for, and sends
no ACK for discarded packets), how bits of sequence number are needed?
The window size determines the number of unacknowledged packets the
transmitter will send before stalling, but there can be arbitrarily
many acknowledged but undelivered (because of one lost packet) packets
at the receiver. But if only 30 packets are held at the receiver,
after which it stops acknowledging packets except the one it's
waiting for, the total number of packets in transit or sitting in
the receivers buffer is at most 40.
So a 6-bit sequence number will be sufficent to ensure that all
unack'ed and undelivered packets have a unique sequence number (avoiding
the sequence number wrap-around problem).
Problem .
Huffman and other coding schemes tend to devote more bits to the coding of
(A) symbols carrying the most information
(B) symbols carrying the least information
(C) symbols that are likely to be repeated consecutively
(D) symbols containing redundant information
Answer is (A). Symbols carrying the most information, i.e., the symbols that are less
likely to occur. This makes sense: to keep messages as short as possible, frequently
occurring symbols should be encoded with fewer bits and infrequent symbols with
more bits.
Problem .
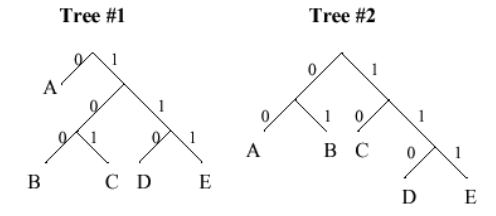
Consider the following two Huffman decoding tress for a variable-length
code involving 5 symbols: A, B, C, D and E.
Using Tree #1, decode the following encoded message: "01000111101".
Starting at the root of the decoding tree, use the bits of the message
to traverse the tree until a leaf node is reached; output that symbol.
Repeat until all the bits in the message are consumed.
0 = A
100 = B
0 = A
111 = E
101 = C
Suppose we were encoding messages with the following
probabilities for each of the 5 symbols: p(A) = 0.5, p(B) = p(C) =
p(D) = p(E) = 0.125. Which of the two encodings above (Tree #1 or
Tree #2) would yield the shortest encoded messages averaged over many
messages?
Using Tree #1, the expected length of the encoding for one symbol is:
1*p(A) + 3*p(B) + 3*p(C) + 3*p(D) + 3*p(E) = 2.0
Using Tree #2, the expected length of the encoding for one symbol is:
2*p(A) + 2*p(B) + 2*p(C) + 3*p(D) + 3*p(E) = 2.25
So using the encoding represented by Tree #1 would yield shorter messages on the
average.
Using the probabilities of part (B), if you learn that the first symbol in a message is "B",
how many bits of information have you received?
bits of info received = log2(1/p) = log2(1/.125) = 3
Using the probabilities of part (B), If Tree #2 is used to encode messages what is the average
length of 100-symbol messages, averaged over many messages?
In part (B) we calculated that the expected length of the encoding for
one symbol using Tree #2 was 2.25 bits, so for 100-symbol messages the
expected length is 225 bits.
Problem .
Huffman coding is used to compactly encode the species of fish tagged
by a game warden. If 50% of the fish are bass and the rest are evenly
divided among 15 other species, how many bits would be used to encode
the species when a bass is tagged?
If a symbol has a probability of ≥ .5, it will be incorporated into the
Huffman tree on the final step of the algorithm, and will become a child
of the final root of the decoding tree. This means it will have a 1-bit
encoding.
Problem .
Ben Bitdiddle has been hired by the Registrar to help redesign the grades
database for WebSIS. Ben is told that the database only needs to store one of five
possible grades (A, B, C, D, F). A survey of the current WebSIS repository reveals the
following probabilities for each grade:
Grade
Probability of occurrence
A
p(A) = 18%
B
p(B) = 27%
C
p(C) = 25%
D
p(D) = 15%
F
p(E) = 15%
Given the probabilities above, if you are told that a
particular grade is "C", give an expression for the number of bits of
information you have received.
# of bits for "C" = log(1/pC) = log(1/.25) = log(4) = 2
Ben is interested in storing a sequence of grades using as few
bits as possible. Help him out by creating a variable-length encoding
that minimizes the average number of bits stored for a sequence of
grades. Use the table above to determine how often a particular grade
appears in the sequence.
using Huffman algorithm:
- since D,F are least probable, make a subtree of them, p(D/\F) = 30%
- now A,C are least probable, make a subtree of them, P(A/\C) = 43%
- now B,DF are least probable, make a subtree of them P(B/\(D/\F)) = 55%
- just AC,BDF are left, make a subtree of them (A/\C)/\(B/\(D/\F))
- so A = 00, B = 10, C = 01, D = 110, F = 111
Problem .
Consider a sigma-delta modulator used to convert a particular analog waveform
into a sequence of 2-bit values. Building a histogram from the 2-bit values we get the
following information:
Modulator value
# of occurrences
00
25875
01
167836
10
167540
11
25974
Using probabilities computed from the histogram, construct a
variable-length Huffman code for encoding these four values.
p(00)=.0668 p(01)=.4334 p(10)=.4327 p(11)=.0671
Huffman tree = 01 /\ (10 /\ (00 /\ 11))
Code: 01="0" 10="10" 00="110" 11="111"
If we transmit the 2-bit values as is, it takes 2 bits to send
each value (doh!). If we use the Huffman code from part (A) what is
the average number of bits used to send a value? What compression
ratio do we achieve by using the Huffman code?
sum(pi*len(code for pi)) = 1.7005, which is 85% of the original 2- bit per symbol
encoding.
Using Shannon's entropy formula, what is the average information content
associated with each of the 2-bit values output by the modulator? How does this
compare to the answers for part (B)?
sum(pi*log2(1/pi)) = 1.568, so the code of part(B) isn't quite as efficient as
we can achieve by using an encoding that codes multiple pairs as in one code
symbol.
Problem .
Several people at a party are trying to guess a 3-bit binary number. Alice is
told that the number is odd; Bob is told that it is not a multiple of 3 (i.e., not 0, 3, or 6);
Charlie is told that the number contains exactly two 1's; and Deb is given all three of
these clues. How much information (in bits) did each player get about the number?
N = 8 choices for a 3-bit number
Alice: odd = {001, 011, 101, 111} M=4, info = log2(8/4) = 1 bit
Bob: not a multiple of 3 = {001, 010, 100, 101, 111} M=5, info = log2(8/5) = .6781 bits
Charlie: two 1's = {011, 101, 110} M=3, info = log2(8/3) = 1.4150
Deb: odd, not a multiple of 3, two 1's = {101}, M=1, info = log(8/1) = 3 bits Problem .
In honor of Daisuke Matsuzaka's first game pitching for the Redsox, the
Boston-based members of the Search for Extraterrestrial Intelligence (SETI) have
decided to broadcast a 1,000,000 character message made up of the letters "R", "E", "D",
"S", "O", "X". The characters are chosen at random according the probabilities given in
the table below:
Letter
p(Letter)
R
.21
E
.31
D
.11
S
.16
O
.19
X
.02
If you learn that one of the randomly chosen letters is a vowel
(i.e., "E" or "O") how many bits of information have you received?
p(E or O) = .31 + .19 = .5, log2(1/pi) = 1 bit
Nervous about the electric bill for the transmitter at Arecibo,
the organizers have asked you to design a variable length code that
will minimize the number of bits needed to send the message of
1,000,000 randomly chosen characters. Please draw a Huffman decoding
tree for your code, clearly labeling each leaf with the appropriate
letter and each arc with either a "0" or a "1".
Huffman algorithm:
choose X,D: X/\D, p = .13
choose S,XD: S/\(X/\D), p = .29
choose R,0: R/\O, p = .40
choose E,SXD: E/\(S/\(X/\D)), p = .6
choose RO,ESXD: (R/\O) /\ (E/\(S/\(X/\D)))
code: R=00 O=01 E=10 S=110 X=1110 D=1111
Using your code, what bit string would they send for "REDSOX"?
00 10 1111 110 01 1110
Problem .
You're playing an on-line card game that uses a deck of 100 cards containing 3 Aces, 7 Kings, 25
Queens, 31 Jacks and 34 Tens. In each round of the game the cards are shuffled, you make a bet
about what type of card will be drawn, then a single card is drawn and the winners are paid off.
The drawn card is reinserted into the deck before the next round begins.
How much information do you receive when told that a Queen has
been drawn during the current round?
information received = log2(1/p(Queen)) = log2(1/.25) = 2 bits
Give a numeric expression for the average information content received when
learning about the outcome of a round.
(.03)log2(1/.03) + (.07)log2(1/.07) + (.25)log2(1/.25) + (.31)log2(1/.31) + (.34)log2(1/.34)
= 1.97 bits
Construct a variable-length Huffman encoding that minimizes the length of
messages that report the outcome of a sequence of rounds. The outcome of a single round is
encoded as A (ace), K (king), Q (queen), J (jack) or X (ten). Specify your
encoding for each of A, K, Q, J and X.
Encoding for A: 001
Encoding for K: 000
Encoding for Q: 01
Encoding for J: 11
Encoding for X: 10
Using your code from part (C) what is the expected length of a message reporting
the outcome of 1000 rounds (i.e., a message that contains 1000 symbols)?
(.07+.03)(3 bits) + (.25+.31+.34)(2 bits) = 2.1 bits average symbol length using Huffman code.
So expected length of 1000-symbol message is 2100 bits.
The Nevada Gaming Commission regularly receives messages in which the
outcome for each round is encoded using the symbols A, K, Q, J and X. They discover that
a large number of messages describing the outcome of 1000 rounds (i.e. messages with 1000
symbols) can be compressed by the LZW algorithm into files each containing 43 bytes in
total. They immediately issue an indictment for running a crooked game. Briefly explain
their reasoning.
In order to achieve such a dramatic compression ratio, the original
messages much have exhibited a very regular pattern - regular patterns
would be very rare if the outcomes were truly random, hence the
conclusion that the game was rigged. LZW should exhibit some
improvement over Huffman since it will compactly encode pairs,
triples, etc. But for messages of only 1000 symbols that process
would not achieve an almost 10-to-1 improvement over Huffman.
Problem .
X is an unknown 8-bit binary number. You are given another 8-bit
binary number, Y, and told that the Hamming distance between X (the
unknown number) and Y (the number you know) is one.
How many bits of information about X have you been given?
You've learned that X differs in exactly 1 of its 8 bits from the known number
Y. So that means that knowing Y, we've narrowed down the value of
X to one of 8 choices. Bits of information = log2(256/8) = 5 bits.
Problem .
In Blackjack the dealer starts by dealing 2 cards each to himself and
his opponent: one face down, one face up. After you look at your
face-down card, you know a total of three cards. Assuming this was
the first hand played from a new deck, how many bits of information do
you now have about the dealer's face down card?
We've narrowed down the choices for the dealer's face-down card from
52 (any card in the deck) to one of 49 cards (since we know it can't
be one of three visible cards. bits of information = log2(52/49).
Problem .
The following table shows the current undergraduate and MEng enrollments for the School of
Engineering (SOE).
Course (Department)
# of students
Prob.
I (Civil & Env.)
121
.07
II (Mech. Eng.)
389
.23
III (Mat. Sci.)
127
.07
VI (EECS)
645
.38
X (Chem. Eng.)
237
.13
XVI (Aero & Astro)
198
.12
Total
1717
1.0
When you learn a randomly chosen SOE student's department you
get some number of bits of information. For which student department
do you get the least amount of information?
We'll get the smallest value for log2(1/p) by choosing the choice
with the largest p => EECS.
Design a variable length Huffman code that minimizes the average number of
bits in messages encoding the departments of randomly chosen groups of students. Show
your Huffman tree and give the code for each course.
step 1 = {(I,.07) (II,.23) (III,.07) (VI,.38) (X,.13) (XVI,.12)}
step 2 = {([I,III],.14) (II,.23) (VI,.38) (X,.13) (XVI,.12)}
step 3 = {([I,III],.14) (II,.23) (VI,.38) ([X,XVI],.25)}
step 4 = {([II,[I,III]],.37) (VI,.38) ([X,XVI],.25)}
step 5 = {([[X,XVI],[II,[I,III]]]),.62) (VI,.38)}
step 6 = {([[[X,XVI,[II,[I,III]],VI],1.0)}
code for course I: 0 1 1 0
code for course II: 0 1 0
code for course III: 0 1 1 1
code for course VI: 1
code for course X: 0 0 0
code for course XVI: 0 0 1
There are of course many equivalent codes derived by swapping the
"0" and "1" labels for the children of any interior node of the decoding
tree. So any code that meets the following constraints would be fine:
code for VI = length 1
code for II, X, XVI = length 3
code for I, III = length 4
If your code is used to send messages containing only the encodings of the
departments for each student in groups of 100 randomly chosen students, what's the
average length of such messages? Write an expression if you wish.
100*[(.38)(1) + (.23 + .13 + .12)*(3) + (.07 + .07)*(4)] = 238 bits