

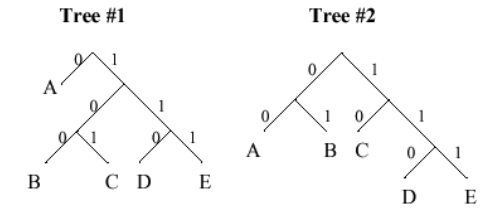
0 = A
100 = B
0 = A
111 = E
101 = C
1*p(A) + 3*p(B) + 3*p(C) + 3*p(D) + 3*p(E) = 2.0
Using Tree #2, the expected length of the encoding for one symbol is:
2*p(A) + 2*p(B) + 2*p(C) + 3*p(D) + 3*p(E) = 2.25
So using the encoding represented by Tree #1 would yield shorter messages on the average.
| Grade | Probability of occurrence |
|---|---|
| A | p(A) = 18% |
| B | p(B) = 27% |
| C | p(C) = 25% |
| D | p(D) = 15% |
| F | p(E) = 15% |
| Modulator value | # of occurrences |
|---|---|
| 00 | 25875 |
| 01 | 167836 |
| 10 | 167540 |
| 11 | 25974 |
| Letter | p(Letter) |
|---|---|
| R | .21 |
| E | .31 |
| D | .11 |
| S | .16 |
| O | .19 |
| X | .02 |
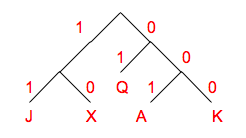
Encoding for A: 001
Encoding for K: 000
Encoding for Q: 01
Encoding for J: 11
Encoding for X: 10
| Course (Department) | # of students | Prob. |
|---|---|---|
| I (Civil & Env.) | 121 | .07 |
| II (Mech. Eng.) | 389 | .23 |
| III (Mat. Sci.) | 127 | .07 |
| VI (EECS) | 645 | .38 |
| X (Chem. Eng.) | 237 | .13 |
| XVI (Aero & Astro) | 198 | .12 |
| Total | 1717 | 1.0 |
code for course I: 0 1 1 0
code for course II: 0 1 0
code for course III: 0 1 1 1
code for course VI: 1
code for course X: 0 0 0
code for course XVI: 0 0 1
There are of course many equivalent codes derived by swapping the "0" and "1" labels for the children of any interior node of the decoding tree. So any code that meets the following constraints would be fine:
code for VI = length 1
code for II, X, XVI = length 3
code for I, III = length 4