A Partly Read-Only
Portable Web Site Solution
Benjamin Kolin
Table of Contents
Implementation and Related Design Decisions
Overhead and Other Considerations
Introduction
CD-ROMs were a very important step in the computer world. For the first time, the average user had a way to transport rather large volumes of data on a single, durable disk. The unfortunate part of this otherwise very attractive media is that it is read-only. This is the root of our problem. We have an Egyptologist friend who runs an archaeological web site. He has to travel to Egypt to do research. While traveling, he needs to be able to access the home web site and make changes and additions to it. His solution is to copy the content of the web site onto a CD-ROM and bring that with his laptop. He knows that any changes he makes on his local copy will not take effect until he updates the home web site. To make matters worse, he likes to give gift CDs to his colleagues while he is travelling and they have to be able to get updates and sync with each other.
We need to find a way to allow our friend to use the CD while still providing a way for him to make changes. We must also find a way for him to update his colleagues' copies of the CD, even if they are not using the latest version. And lastly, we must find a way for him to successfully upload all of the changes he made while on the road back to the main web site.
First we should identify the desirable properties of a solution. We want to develop a system that is easy to maintain. It should facilitate changing any web page in the site, as well as adding any new web pages. Our solution should allow users to perform update and synchronization tasks without being computer experts. It should also be within reasonable limits of disk space and processing power.
The key to my solution lies in the difference between the regular version of the web site and the version on the CD-ROM. The organization of the home web site is not important. By this I simply mean that the HTML files can all be in the same directory or they can be in different directories, it is not particularly important, as long as their locations are known. Now we must determine if the type of link (relative vs. absolute) is important to us. If the home site is designed using relative links, the entire site can be moved to another host machine and still work correctly (assuming that all files are placed in their corresponding directories on the new host). If the links are absolute, we will need to change them if we change hosts. Luckily, my solution will work for both cases, depending only on how a certain translation program to be discussed later is written.
Implementation and Related Design Decisions
The first large design decision I made concerned which generation of browsers I was planning to support. My system relies on the META tag, which first appeared in the Netscape Navigator browser, version 1.1, which was released in early 1995. A bit of research showed that the vast majority of the Internet supports the functionality of this browser, so I consider this a valid decision. One alternative here is to use some of the empty space left on the CD to distribute browsers.
Before we examine the procedure used for creating the CD-ROMs, we should discuss the use of the META tag. This tag is used to include extra information in an HTML page, for example the author, publishing program, or refresh information. We will be using its Refresh option, which causes pages to reload after a specific interval. This command is usually used on web sites that have changing content and want to update what their users are seeing after a specified time period. For example, the CNN web page (http://www.cnn.com) has the line <meta http-equiv="Refresh" content="1800"> at the top of the first page, which tells the browser to reload the file every 30 minutes (1800 seconds). A slightly modified use of this command is where a different URL is specified in the Content field. This configuration is often used in situations where a web site has moved and the old site (the one the user accessed) wants to display a message telling the user where the new site is and then transfer the user directly there after a specified amount of time. For example, the following HTML page will tell the user that they are about to see my homepage and will then load it after ten seconds:
(Example 1)
<html>
<head>
<title>About to Refresh</title>
<META HTTP-EQUIV="Refresh" Content="10; URL=http://www.mit.edu/people/benkolin/">
</head>
<body>
You will be transferred to Ben Kolin's home page in 10 seconds.
</body>
</html>
My solution requires that we tweak this last use of META by setting the Refresh delay to zero seconds, causing an instantaneous redirection that should be transparent to the user. For example, the following web page will load Netscape's web page as soon as it is loaded:
(Example 2)
<html>
<head>
<META HTTP-EQUIV="Refresh" Content="0; URL=http://www.netscape.com">
</head>
<body>
</body>
</html>
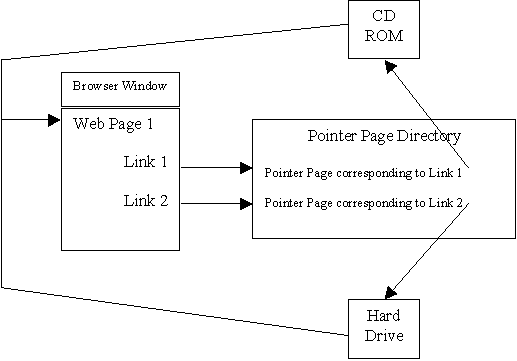
The trick here is that every link on the CD will point to a page that has only the basic necessary HTML code and a redirecting META command (just like Example 2 from above). When the CD is burned, the web site is completely up to date, so all redirecting pages will point back to HTML pages on the CD. We can set up a useful metaphor here of the redirecting HTML pages as pointers to other web pages, especially since they are not actually viewed by the user. (From now on, a pointer page refers to a web page such as Example 2.)
Now we will discuss the actual implementation of this solution and then we will move on to discuss the overhead involved and possible alternatives. Two parsing programs need to be written for the Egyptologist, to create CD's and update the home site, and one more must be written for the users, to update sites with each other and to update their sites from the web.
The first program, which we will call Creator, takes the home web site and outputs the CD copy of the web site as well as one HTML page for every link on the site. As I stated above, this program is written to be able to understand either relative or absolute links, whichever way the home site was designed. The CD copy of the web site consists of every web page on the site, exactly the same as it is in the home site with the exception of the links. The parser will make all links in the CD copy of the site point to HTML pointer pages on the hard drive. One extra file is added to the root directory of the CD which contains the time and date the CD was created. This file is useful for version control considerations. The CD is now burned with this modified copy of the site. The HTML pointer pages are stored in a standardized place on the hard drive, for example c:\pointerpages. At this point the CD will work as if our friend had full access to the home web site. The Egyptologist can verify that the CD works correctly by using one of the commercially available link checking packages which automatically follows every link and makes sure that it correctly loads a page.
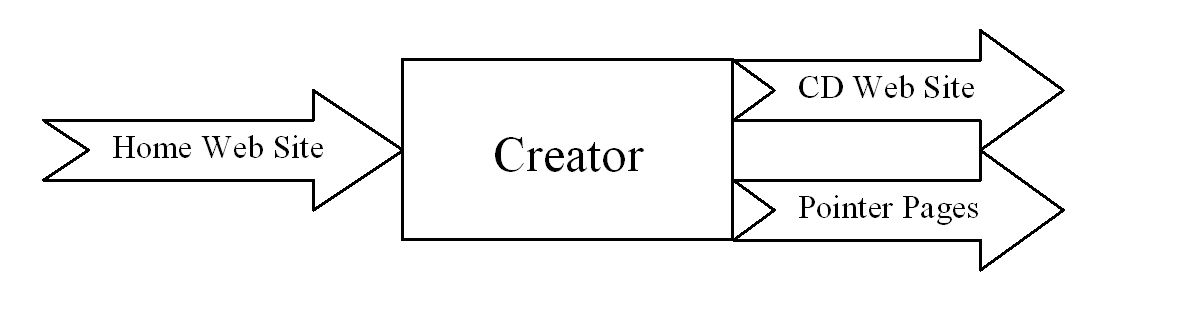
The procedure for adding or revising pages is comprised of two steps. First, the new page is created (if a modification is required for an old page, that page is copied and modified and then treated as a new page). We will call these modified files site pages to differentiate them from pointer pages. Next, any pointer pages stemming from this page that currently point to the CD are modified to point to the location of the new page on the hard drive. Common sense tells us that it is simplest to store all new site pages in the same place on the hard drive.
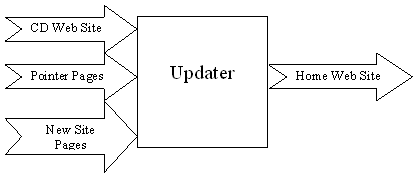
This leads us to the second parser, which we will call Updater. Updater knows the standardized location of both the pointer pages as well as the modified or new site pages (assuming any exist). Its function is simple. It checks the creation date of the CD (which is in a file in the root directory as discussed above) and then searches the pointer page directory and the modified site page directory for pages created or modified after this date. It takes these pages and reformats them to fit the home site (using relative or absolute links, whichever the home site uses). This just means that it makes links point to the actual other HTML files rather than to pointer pages. This process is simple since it only requires searching through the new site pages for links and then looking up the destinations in the corresponding pointer pages. Updater outputs the new HTML files, ready to be uploaded to the home site. It also copies any other necessary files to the upload directory (for example new graphic files). It finds these by checking for references to graphics (or other non-HTML elements) which do not already exist on the CD-ROM. At this point, our Egyptologist friend need only FTP to the home site server and drop the new files into place. Once again, it would be much easier if the home site is organized in a way such that files are easy to find, but that is a convenience issue and not a necessity.
At this point we know how our friend will get a "snapshot" of the home web site and we also know how he will make updates to the home web site from the field. What remains is to figure out how users (including himself) can sync with each other and with the home site. These are two separate problems. First we will discuss how users sync with the home web site. The easiest way to do this is to have a page on the home site of updates available by date and just allow the user to download a single, self-installing compressed file which when uncompressed will drop all the updated pages in the correct places. This update distribution page requires little maintenance since our Egyptologist friend can make these self-installing files easily as an extension of the process by which he updates the home site. Any time he updates the home site, all new and modified files go into the distribution file. This is easy to do because the parser program which prepares updates to the web site outputs a directory of new files, so we already know which files need to go into the self-installing update file. Users can tell which update file they need by checking the date of their CD. For example, if Person A has the first version of the CD and Person B has the second version of the CD and the current version is the third version, the update page would have choices [Update Version 1
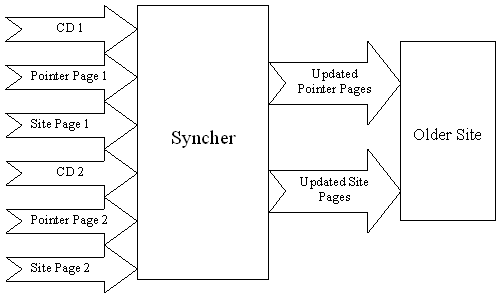
à 2], and [Update Version 2à 3]. Person A would need to download both updates and install them in order by date with the earliest date first. Person B would only need to download and install [Update Version 2à 3]. I am making a clear sacrifice at this point. The user actually has to go and look for new updates rather than have them attempt to load automatically. Any other method would have to request pages, file dates, or some other property of pages on the home site which would help determine if new pages existed. This would introduce some complexity issues in terms of figuring out if the user is currently connected to the internet, dealing with browser timeouts on slow or bad connections, and other things of a timing type nature. My method accomplishes the same goals with a little more effort on the part of the user and much less complexity in the design.The third parser program, which we will call Syncher, will allow users with different copies of the CD to update with each other. This includes having our friend update his colleagues' CD's with newly created pages. Syncher can be distributed on the CD in some of the left over space. For this section I am assuming that the two computers to be synched are connected to each other in a way which allows file dates to be checked and files to be transferred. I am assuming that appropriate software and hardware exists on all available platforms to make this possible, since otherwise this design would require us to write network software (and possible build hardware interfaces), which is beyond the scope of this project. The process of synching two computers is not difficult. They both have pointer page directories and modified page directories (although the modified page directories might be empty). All we need to do is to find the latest dated file in either of these directories on with of the computers. The computer which has this file has the newer version of the site. If they both have this file, the process is repeated for every file in the directories until all files have been compared. If both computers have all files with the same dates and neither computer has files which the other computer is missing, the computers are already synched. Once we have established which computer has the newer version of the site, we need to transfer files. Now the parser gets to do its work. It searches the newer version of the site for all files dated later than the latest file date on the older version. These files can come from either the CD or the hard drive of the computer with the newer version (the parser will select the latest copy). Once all the new HTML pages and graphics are transferred, the pointer pages have to be updated. The parser will look through all the new site pages and convert their links to point to pointer pages on the hard drive. These pointer pages will then have to be modified to point back to the most recent version of the site page in question. This can be accomplished by doing a simple date search, or we could modify our original search to keep a transaction record since we have already searched for new files by date. A simple date search would be very quick to program so we will choose that method at the expense of wasting some processor time in the synching process. Once the pointer pages are updated, the sites are synched.
Overhead and Other Considerations
Like any other solution, this solution to the design problem has its positive and negative points. The first thing to consider is the fact that we will need hard drive space on every computer that uses a CD copy of the site. This space is for storing pointer pages and modified site pages. A few quick calculations give us an idea of how much space we need. Each pointer page is about 100 characters so that is 100 bytes per page. Due to hard drive cluster sizing issues on some platforms, these 100 bytes may take up a number of kilobytes. But even with a thousand pointer pages, we are still only dealing with about 25 megabytes, and could be dealing with as few as 100 kilobytes. We will also need space to store any new site pages and graphics. Another serious concern is development. This solution requires writing three programs as discussed above. These programs are not especially complicated but they have to be constructed to run on all available platforms since they will be distributed along with the CD. It is nice to be able to design them to handle either relative or absolute links because that way we can avoid the complexity introduced by trying to use the BASE element, but making the program so modular again adds to the level of complexity. If very quick development and implementation is required, this may not be the best solution. One nice feature of this solution is that once these programs are written, synching, uploading, and downloading are all completely automated procedures that do not require the user to have any explicit knowledge of the system beyond how to connect two computers together. A similar bonus is that no special modifications must be made to the rest of the system. No web server software needs to be run on the laptop.
I also explored a number of other solutions. First I thought of the most trivial solution I could, which would be to copy the entire contents of the CD onto the hard drive. That way changes could be made and the site could still be viewed locally. I abandoned this solution without putting too much thought into it because I felt that requiring 650 megabytes of free hard drive space was outside of the reasonable expectations of user resources.
The next option was to use a custom web server. This web server would resemble a standard proxy server. All page requests would go to this server, which would keep track of the location of the newest version of each page. It would do this by checking the CD, the hard drive of the local computer, and the Internet. This was an attractive approach because updates would be basically transparent, processor and disk overhead would be low, and overall system design would be fairly simple. The reason I did not favor this method is because of the level of complexity it would introduce. Web server applications would have to be written for every platform. Every browser would have to be reconfigured to use the local server as a proxy server which would make it unusable for the rest of the internet without reconfiguring each time the browser was started. This is not only inconvenient, it is also beyond the abilities of many internet users. I did not consider this an acceptable constraint, so I abandoned this method.
The project was to design a partly read-only, portable web site which could receive updates and could version sync with other copies of the site. I traded complexity for overhead and vice versa in various places to arrive at a solution that would be easy for the end user to use, fairly easy for the developer to implement, and easy for the Egyptologist to maintain. Once this system is set up, no computer specialists should be necessary to maintain the site. I consider that a good indication that this is a good solution to the problem.
HTML Primer
, Mark AndreessenMicrosoft (www.microsoft.com)
Netscape's Web Site (www.netscape.com, developer.netscape.com)
Daniel Connolly. HTML 2.0 Specification. World-Wide Web project office, March 29, 1995.