Daniel L. Rosenband
A remote procedure call (RPC) library[1] provides client applications with transparent access to a server. Services that the server provides to the client could include computational services, access to a file system, access to part of an operating system in a distributed operating system, or most other functions used in a typical client/server framework. RPC was designed at Sun Microsystems where widely used applications, such as the Network Filesystem (NFS), were built on top of an RPC library.
The crucial requirement of an RPC system is that it provide a client with reliable, transparent access to a server. A remote procedure call to a server looks exactly the same to the client application as a local procedure call. This is a very powerful concept. The application programmer does not need to be aware of the fact that he is accessing a remote computer when executing an RPC function.
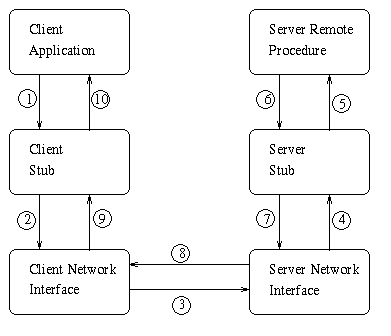
Figure 1 illustrates the flow of a RPC call. In the first step the client application makes a procedure call exactly as it would make any local procedure call. The procedure invoked by the client is called a stub. It flattens the arguments passed to it, packs them with additional information needed by the server, and passes this entire packet to the client network interface. It is important to note that the client application need not know that this stub exists. The stub is generated by the RPC library and provides the illusion of a local procedure call. As far as the client is concerned the stub is actually executing the procedure call.
The network interface then executes a protocol to reliably transfer the stub-generated packet to the appropriate server. In step four the server's network interface calls the server stub. The server stub unpacks the received request and executes the remote procedure on the server. The returned data is then passed back to the server stub, which packages it and has the server network interface transmit it back to the client network interface (step eight). The client network interface then passes the packet to the client stub, which is now responsible for unpacking the received packet and returning the desired data to the client application.
In this paper I will focus on the design of the network interfaces between the client and the server. How an RPC library generates stubs is a very interesting and complex research area but does not fall within the scope of this project. When generating the stubs one needs to consider such issues as authentication (this could also occur at the network layer), how to pass parameters (this is especially difficult when pointers are used), which server the RPC call should be made to, as well as many more issues.
In the following section I will discuss the high-level view of the network interfaces. I will present the constraints faced in their design, as well as desirable features that such network interfaces should provide. I will also describe the software interface to the client and server network interfaces of the RPC library. In subsequent subsections I will then give a detailed description of the design and implementation I chose for the network interfaces. Here I will also discuss some alternative designs that might have been used. Section 4 contains a summary and my concluding remarks.
The most important requirement of the RPC network interfaces is that they provide reliable operation. This is especially challenging in this project because UDP[2] is the network protocol that will be used. This is an unreliable protocol; that is, it can re-order, drop, duplicate, and corrupt packets (corrupted packets are dropped). In addition, it is only able to transmit packets of limited size. Because our RPC library should be capable of handling arbitrarily large packets, the network interfaces will have to be capable of breaking large packets into smaller sub-packets and recombining them at the receiving end.
One might ask why one would ever want to use UDP for an RPC implementation since reliable protocols such as TCP are available. The reason for this choice of network protocol is that a carefully designed implementation on top of UDP can avoid much of the overhead associated with network operations that use TCP. Some people even argue that RPC should not be built on top of UDP, or even IP. Instead, an entirely new protocol should be used to avoid the time spent on name-resolution (across network boundaries) which is accrued when IP or UDP are used. This latency can be eliminated since RPC is usually performed within a small subnet, not across network boundaries. All in all, UDP provides a convenient and sufficiently efficient protocol for our RPC library and was chosen for that reason.
One important aspect of our RPC library is that it provides at-most once semantics. This means that any RPC call will be executed no more than once, but possibly not at all. It would be desirable to have a RPC protocol that provides exactly-once semantics. However, it is extremely difficult to achieve this because of the need to continuously check-point the work that has been done to ensure that execution can be resumed in case of a server crash. At-most once semantics will ensure that an RPC call is not executed multiple times (which could easily occur in a trivial RPC implementation because of the message duplication in the network). Only in rare circumstances, such as a server crash, will the RPC request not be executed at all.
From the client's perspective the most desirable property of the RPC library is that it executes quickly. Small RPC requests have to be handled very efficiently to hide as much latency as possible, and large RPC calls have to be handled efficiently so that they execute quickly, while not using too many resources. In particular, the RPC library should try to use the network resources efficiently. In many applications the network is a bottleneck, and so network bandwidth should not be wasted.
Figure 2 shows how the network interface of the RPC would be used in a typical stub. On the left side of the figure are the procedure calls made by the client, and on the right are those made by the server. The arrows between client and server indicate messages being sent over the network. (Note: more detailed descriptions of the protocols and data structures used will be given in the design and implementation section.)
The first step the client and server need to perform is initialization of their sockets and associated parameters. The server calls the RPC library function bind_service to bind to its appropriate socket (the socket is identified by one of the parameters). bind_service is also responsible for initialization of several internal data structures. The client calls the function setup_srvinfo to initialize its socket. At this point, an internal structure to uniquely identify a client RPC request is also initialized.
Once initialization of the server has been completed, the server will execute the get_request command. This command will block until a request from a client arrives. The server is now ready to receive RPC requests.
After the client has been initialized, it makes a call to rpc. This sends the RPC request (along with any parameter values) over the network to the server. After get_request has received the client-request, it returns the request as well as a client identifier (this is used to reply to the client) to the stub. The stub decodes the request, executes the remote procedure, and then makes a call to put_reply. This takes the value returned by the remote procedure call and sends it to the client. The server then runs get_request again to receive the next RPC request.
Once the client, that is the call to rpc, receives the server's response, an acknowledgment of receipt is sent back to the server and the received value is passed on to the client stub which in turn decodes it and passes it on to the client application. The client can now make additional calls to rpc or close the rpc service by calling teardown_srvinfo. The server can close its service and release all used memory by calling release_service.
The previous paragraphs gave an overview of how the network interface of the RPC may be used. Many details of how the protocols work were not described. These will be discussed in detail in the following section. However, I want to stress that the details of this protocol do not need to be understood by someone using the RPC network interface. The sequence of calls made by the client and server stubs are always the same. Within the called functions, complicated protocols may be executed to ensure at-most once semantics and reliable communication. However, as noted, these details are not visible to the higher layer in the RPC library.
In the the following subsections I will discuss several important design decisions I made when implementing the RPC network interface. I will discuss the implications that these decisions have on the overall performance of the RPC library and what alternatives exist.
The first major decision that had to be made when designing the RPC network interface library was whether it should be multi-threaded or not. On the client side, a single thread is clearly sufficient since the client should block until the rpc call returns. Things are not as clear on the server side. Here it would be nice to have one server thread that reads all the data from the network. Another thread could examine the incoming data and spawn a new thread depending on the action that needs to be performed. Either a thread to perform the RPC call on the server should be spawned or a thread to send a reply to the client should be spawned.
Such a multi-threaded server would clearly be much more efficient than a single-threaded implementation. This is because the functions the server needs to perform are mostly blocking instructions or system calls with much idle time (because of I/O delays). A uni-processor, and especially a multi-processor server, would thus benefit from a multi-threaded implementation, and most commercial RPC systems are almost certainly multi-threaded. However, I chose to make the server a single-threaded process because it makes the design significantly easier. It is not clear to me, if, or how, one can share a single socket to communicate with clients among several threads. Many other issues such as how the server state should be shared among the threads would also need to be studied. In order to make the design simpler I chose a single threaded design.
There are two issues that have to be considered when dealing with long messages. One is how to acknowledge efficiently receipt of long messages and the other is how to indicate what part of the message is being sent.
Extremely long messages need to be broken up into parts since the network protocol, UDP, only allows messages less than 64kb to be sent. At first glance, one might think that the easiest implementation would be to have the transmitting end send the long message as consecutive smaller packets and have the receiving end combine them into the larger message. However, this does not work since packets can be reordered in UDP which would cause the receiver to receive the packets in the wrong order and reconstruct an incorrect message.
The simplest protocol to transmit long messages is to send the first piece, wait for an acknowledgment of receipt, send the second piece, etc., until the entire message is sent. This is clearly very inefficient since one round-trip delay is used for each packet piece, when only a half is needed.
In my implementation I chose to place a tag identifying which piece of the message is being transmitted at the beginning of each packet that is sent. The tag contains the total number of pieces that need to be transmitted for the message, as well as a number identifying which piece is being transmitted. This choice places a restriction on the overall size of messages being sent. I am using 32 bit integers for the tag identifiers, and so a message can be at most 256Gb. Under most circumstances, this is not an unreasonable restriction.
There are three ways to acknowledge receipt of a number of message pieces. One can send an acknowledgment for each message piece received, send a bit vector identifying which message pieces were received, or a message explicitly listing each piece that was received can be sent. I chose to use the third method. Although very simple, the first method is clearly inefficient. I chose the third method over the second because it is easier to implement, and more efficient in some cases. If not all acknowledgments fit into a single message, then they can be split into several messages.
I added two special cases to my implementation of acknowledgments. If all packets that had to be received have been received, then this can be acknowledged with a single, short message. One does not need to list all tags. Similarly, if all but a few messages have been received, it would be a waste to acknowledge all received packets. Instead, it is much more efficient to simply send NACKS (negative acknowledgments). These would indicate requests for retransmission of certain packets.
One very important part of the RPC library that is needed to ensure at-most once semantics is a client request identifier (CRID) which is unique for every RPC request that is made. No two RPC calls should ever have the same CRID. Successive requests made by a single process are guaranteed to be monotonically increasing. This means a server can always tell if it is receiving a new request or a duplicate of an older one.
I chose to use four fields in my CRID representation, all four of which must match for two CRIDs to be equal. The four fields are a hostid identifying the host the client is running on (any two distinct hosts have different hostids), a pid identifying the client's process, a timestamp showing when setup_srvinfo was executed (to initialize the client), and a count identifying the request number for a particular client. The hostid and pid are used to distinguish between different hosts and different processes running on the same host. The request number is incremented after each RPC request and a server is thereby able to distinguish between duplicate requests (created in the network or due to retransmission of a message) and requests that are distinct. The timestamp is used to ensure that the server can distinguish between requests made by different invocations of the RPC client library on a single host. If a client crash occurred then the time stamp might be the only field which distinguishes the new CRID from the old one.
There are many different ways to construct unique identifiers. I believe the method I have chosen guarantees uniqueness (assuming the time is not changed on a client), and is reasonably efficient. One might be able to use fewer than four fields, but compared to the overall execution time of an RPC call, the time required for transmission and comparison of these four fields is negligible.
A server crash is an interesting case in the RPC library design. The challenge is to have the server be able to identify duplicate requests after it has crashed and then been restarted. There seem to be two possible solutions to this problem. One is to have all clients register with the server when executing setup_srvinfo (client initialization). The other is to use a timestamp for when bind_service (server initialization) was executed on the server.
At first it seems as though registering clients with a server is the most reliable solution and poses the least restrictions on synchronization between client and server. However, after examining registration protocols more carefully it becomes clear that synchronization is still needed. It is possible that a client registration message could be duplicated in the network. After a server crash this message could be received by the server and, without synchronization, would be perceived to be a valid registration request. Duplicated RPC requests floating around the network, which were executed prior to the server crash, may now be executed again by the server. This is clearly in violation of the at-most once semantics. Thus, registration turns out to be a difficult problem that requires synchronization between client and server to ensure that only valid registration requests are accepted.
An alternative solution is to store a timestamp of when the server bound to its socket. Since the server needs to be bound to its socket before the client can be initialized, all timestamps in CRIDs of valid requests must be less than the server timestamp. If a CRID contains a timestamp less than that of the server, then the CRID belongs to a request which was sent before the server was initialized and should thus be ignored or an error should be returned to the client.
One complicating factor in this type of server crash identification is that it requires some synchronization between client and server machines. Both have to be set to approximately the same time. If the server's clock is set later than the client's, then no connection can be established.
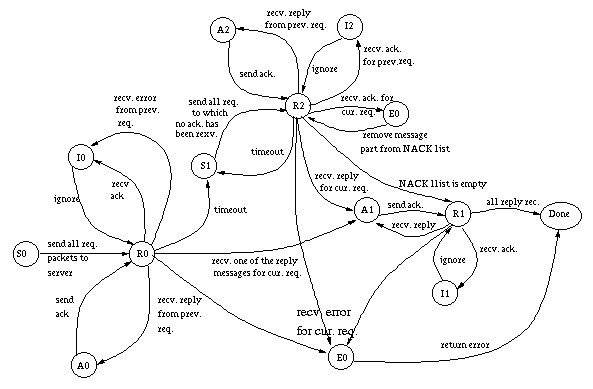
Figure 3 shows the finite state machine (FSM) that is used for the client. In the following paragraphs I will discuss some of the details of this FSM. However, I will not discuss all state transitions as many of them are uninteresting, and can be easily understood by looking at the diagram.
The client starts out in state S0. It sends all packets belonging to the current request to the server and moves to state R0. Each one of these request packets contains a CRID identifying the client from which the request originated. Replies sent by the server will always contain a copy of the CRID that belongs to the client request being processed. This allows the client to distinguish replies to the current request from replies to old requests.
In state R0 the client waits for the server reply. If it is received, the FSM changes to state R1, where the client waits for the remaining reply packets to be received, acknowledging each one as it is received. If all reply packets are received within a short period of time then a single message can be sent to acknowledge them all as described in the section on long messages above. It is assumed that the server will retransmit the replies that have not been acknowledged. After all the packets have been received, the RPC call is finished and the result can be passed to the client stub.
If in state R0 no reply was received for a long period of time, the FSM times out and moves to state S1. Here it will send all request packets again and wait for each of them to be acknowledged. Receipt of a reply will obviously be considered to be an acknowledgment for receipt of all request packets since the server would not have been able to produce the result without having received all the client packets. After receiving acknowledgments for all packets the FSM moves to state R1. In this state it knows that the server has received all packets belonging to the request and it is now waiting for the server reply. The replies are processed as described above.
Most other state transitions in the FSM describe inputs that should be ignored. Messages that should be ignored include any message that belongs to an old request and acknowledgments that have already been received. An error message received in reply to the current request will result in an error being returned to the client stub.
The server FSM for get_request is depicted in Figure 4. Its operation is quite straightforward and can best be understood by examining the state-transition diagram in the figure. get_request basically reads packets from the input, places them in a data structure, returns acknowledgments if they are requested, and returns control to the stub if all packets belonging to one of the requests have been received. If an acknowledgment has been received for a reply previously sent to a client, then the data structure that keeps track of which replies still need to be acknowledged is updated to reflect this. Periodically all replies that have not been acknowledged are sent to their corresponding client.
I chose to implement put_reply differently than was suggested in the problem statement. There it was stated that put_reply should not return until all acknowledgments of the server reply have been received. This seems extremely inefficient to me and could possibly lead to deadlock. If an acknowledgment is lost, and the client does not perform any more rpc calls then put_reply would wait indefinitely for an acknowledgment. Having get_request handle the acknowledgments and letting it do work while waiting for their reception avoids this problem.
I chose to incrementally increase timeouts for retransmissions on both the client and server sides. The reason for this is that a server or client crash would lead to much of the network being wasted, possibly until the remaining part of the system crashes. A longer timeout period would ensure that the number of messages being sent to which no reply could possibly be received (because of client or server crash) decreases over time, thereby limiting the amount of network bandwidth that is wasted.
There are three basic data structures that are used in this part of the RPC library. They are SRVINFO, CLIREQ, and SVCDAT. SRVINFO is used by the client to identify the server it is supposed to use. It also contains the CRID for the client. CLIREQ is the data structure used as an interface between get_request and put_reply. It contains socket information so that the server knows who to reply to as well as the CRID. The CRID is needed by put_reply since the CRID should be returned to the client. In this way it is receiving a reply to its outstanding request rather than to an old request.
The most complicated data structure is SVCDAT. It contains the server timestamp, information pertaining to the socket it is bound to, and a large structure used to store information about clients. This structure contains partially received requests from clients, as well as the latest reply that was sent to each client. This is needed in case a reply has to be retransmitted. It also maintains a vector for each reply identifying which parts of the reply have been acknowledged and thus do not need to be retransmitted. The CLIREQ structure for each client is also duplicated within SVCDAT. It is used to compare the CRID of incoming requests to the CRID of the request that was last processed for this particular client, thereby verifying that it is a new request, not a duplicate of an old one.
It is important to note that this structure needs to be organized very carefully as nearly all messages received will lead to a reference to some element within it. A hash table should be used for efficient access when the structure becomes large. For reasons of simplicity I chose to use a simple linked list in my implementation. This is clearly much less efficient, but significantly easier to implement.
The FSMs as described above are quite similar to those used in other RPC systems[3]. Some designs change the order in which functions are executed or the exact semantics of how acknowledgments are sent. Such modifications will sometimes increase performance but often complicate the design. In order to ensure a reliable RPC library I decided to simplify the overall design while ensuring that the library performs well. I believe I have achieved this goal.
Testing of the implementation is done using a simulated ``bad'' network. By adding controls to change packet duplication rate and drop rate within the network layer (the UDP interface) the functionality of the FSMs can be tested. Some states are hard to reach and exactly which states are reached depends in large part on the timing of when packets are received and transmitted. These factors are hard to control. After running the RPC library over many cases with many different network parameters one should be able to assume that most states are covered; one can verify that they work correctly by validating the final value returned by the RPC call.
All in all I think I have developed an efficient and reliable network interface for an RPC library. It provides at-most once semantics, does not waste excessive amounts of network bandwidth, and tries to hide some of the latency at the server side by multiplexing operations while it is waiting for acknowledgments. Small refinements to the protocol would lead to a more efficient implementation, but most changes seem to involve considerable design complexity. I think I found a good balance between design complexity and performance.