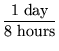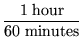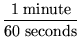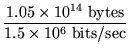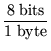Maintaining the Integrity of a Digital Library
Sarah Ahmed - Matthew Berman - Kyle Jamieson
Professor Hari Balakrishnan
6.033 Computer System Engineering
#012358
June 28, 1999
While increases in disk storage capacity allow
entire libraries of information to be kept online, maintaining the
integrity of large amounts of data is a challenging task. We describe
the design of a distributed, web-accessible system responsible for
maintaining the integrity of a digitized library archive. To achieve
this goal, we replicate servers and establish at least three copies of
submitted data before acknowledgment of receipt. Similar processes
and internal data structures manage the process of adding a new
replica to the system. Throughout the system, we exploit
cryptographic hash codes to streamline the implementation of object
identifiers and verify the correct transmission and receipt of data
over the network. Finally, we show how the above mechanisms are
sufficient for the detection and repair of disk and replica failures
when a maintenance process operates continuously in the background at
each replica.
With the exponential growth of the Internet and the increasing
availability of cheap, high-capacity hard disks, on-line digital
libraries are becoming a reality. Due to the huge quantity of
information that can be stored in such libraries and the dynamic
nature of the Internet, maintaining the integrity of the data becomes
a major concern. The Library of Congress is planning to take
advantage of these new technological possibilities and digitize its
entire collection of 105,000,000 objects. Maintaining the integrity
of this many objects is no easy task, and the Library desires a
repository, procedures, and protocols that will address this problem.
To ensure continuous availability of the digital library, the Library
would like to establish replica sites in Australia, Russia, South
Africa, and Ecuador, in addition to the Washington, D.C. site.
In this paper we design a repository for reliably storing a library's
data. We provide the repository interfaces put and get
for adding and retrieving items, a set of procedures for creating a
new replica, and other protocols and procedures for updating and
preserving data integrity. Our primary design goal is integrity: we
provide distinct procedures for maintaining intra-replica integrity,
inter-replica consistency, and ensuring reliability of disk reads and
writes.
Section 2 of this paper outlines the
desirable properties of our repository.
Section 3 describes our design in
detail. Section 4 presents alternative
design choices that we considered and rejected together with the
tradeoffs of the design we chose. A summary and our conclusions are
given in Section 5.
Design Criteria
This section lists the major design criteria for the archival storage
system of a digital library. The requirements are dominated by
integrity concerns, but other considerations include performance and
usability constraints.
The user should not be constrained to submit (put) or query
(get) library data from any particular replica; instead the
client software should be able to query all replicas. This lets
clients optimize their own accesses, provides for the distribution of
network load, and provides for load-balancing on each replica.
Additionally, the system should not rely on users to avoid duplicate
data; users should be able to enter the same information more than
once without harming integrity.
Guaranteeing that the same data submitted to the repository are
available for later retrieval is the most important requirement of the
system.
We require that different put operations on the repository do
not interfere with each other, so that we obtain serializability.
Each replica in the repository must eventually store every piece of
data successfully submitted to the system. To meet this requirement,
replicas will be obligated to engage in protocols that ensure
propagation of data throughout the entire system within a reasonable
amount of time. Furthermore, due to the unreliability of the network,
when a replica receives a new piece of data, it must also verify its
validity.
If a librarian presents the same data to the repository more than
once, the repository should not dedicate any additional system
resources to that piece of data. This requirement is consistent with
the semantics of the put operation [#!handout27!#]; an item
successfully put to the library more than once need not be
treated any differently than an item successfully put to the
library only once.
The next requirement is a condition on the validity of the data seen
by librarians when they perform get operations to retrieve
information. The repository should not return any data as the result
of a get operation that was not supplied to the system as the
argument of a put operation. We term data that violates this
condition ``bogus'' data.
The underlying hardware and network that the repository system uses is
prone to failure, and a failure in the hardware should not jeopardize
data integrity. Failures can be divided into the following
categories:
- 1.
- Disk-Related Errors: Files stored in replica hard disks may be
incompletely written or incorrectly read; the repository system must
recover from these errors. Additionally, the directory structure may
be corrupted: entries may silently disappear or be damaged.
- 2.
- Network-Related Errors: Packets sent over the network may be
corrupted or dropped. We assume the use of a TCP channel between
replicas, which has a 32-bit checksum. However, with a number of
operations at least on the order of magnitude of
 1.0 x 108 put operations
1.0 x 108 put operations 
 5 replicas
5 replicas  = 5 x 108 transactions over the lifetime of the
system, the probability of an error is non-negligible, so replicas
must make the probability of network data corruption very low.
= 5 x 108 transactions over the lifetime of the
system, the probability of an error is non-negligible, so replicas
must make the probability of network data corruption very low.
- 3.
- Server Crashes: Natural disasters or unrecoverable hardware
errors may cause an entire server to fail. When a server fails, all
data on the server are lost. We require that server crashes not
cause an inconsistency in the data stored at other servers.
New replicas may be added to the system at any time; we require that
the addition of a replica occur concurrently with ongoing additions
and queries to the repository. Additionally, the new replica must
reach a state consistent with the other replicas within a reasonable
amount of time. The process that copies files to the new replica
may be interrupted several times before completion, so it must be
recoverable.
Object Identifiers (OIDs) name items in the system; we require that
they be unique to each item and immutable. Furthermore, we require
that different replicas in the system come to a consensus on the
object ID assigned to a new object. No other requirements are placed
on OIDs by users of the system.
Performance
We can estimate an upper bound on the required average time per
request with the assumption that librarians put data to the
repository only during the work week, during an 8-hour window of the
day. These figures yield
an average rate that a successful system must meet or exceed. The
system does not require performance above this bound, however.
Recommended Solution
We divide the system into two levels: the repository level and the
replica level.
Figure:
Structure of the proposed solution. One of the replicas is
designated primary for each client operation.
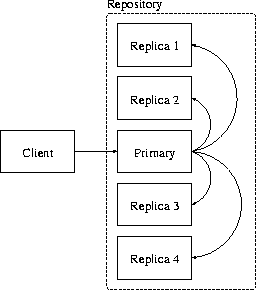 |
In the repository level, one replica is designated as the primary
replica for each put request. The client repository software
chooses a primary replica out of all replicas available, and
sends the data to that replica. The primary is responsible for
immediately storing the data locally and sending it to all other
replicas. When the primary is satisfied that at least two other
replicas have stored the data, it returns the object ID to the client.
To make a get request, clients are responsible for contacting as
many replicas as necessary to fulfill the request. There is no
constraint on which replicas the client contacts for a put or
get request.
In our design, the name of each file is the SHA1 hash
[#!schneier!#, pp. 442-445] which is also the OID. This ensures with
high probability that each file has a unique OID and allows for an OID
to be trivially translated into a file name. Since the hash
calculation needs to be performed to check data integrity, usage of
the SHA1 hash as the OID and filename simplifies the system
considerably. Also, this design trivializes the process of duplicate
data detection, as explained in Section 3.1.3.
Although the OID of a given file is the same in each replica, the disk
in which the file is stored at each replica may vary. Therefore, in
order to map OIDs to the directory in which the file resides, we
maintain a balanced tree data structure at each replica site. Whenever
a new OID is stored at a replica, a new node is entered into the
replica's tree. In order to guarantee reliability under the threat of
disk failure, the tree is replicated across three disks at each
replica site.
The amount of storage needed for the trees is on the order of several
Gigabytes. An estimate of the necessary storage, assuming 100 bits of
bookkeeping information per node, 160 bits per node for the SHA1 hash
and 8 bits per node for the disk number, is
1.05 x 108 nodes x  160 bits + 8 bits + 100 bits
160 bits + 8 bits + 100 bits  = 3.5 GB.
= 3.5 GB.
When get or the integrity checker operations (see
Sections 3.1.4, 3.2.1) need
to query an OID in a given replica, they query all three OID trees in
that replica, and use majority polling to resolve differences.
The client repository software decides the order in which it tries to
use each replica as primary. Because librarians will submit put
requests primarily from the Washington, D.C. area, and because the
Washington, D.C. site has the highest-bandwidth Internet connection,
nearly all put requests will use that site as their primary.
Get requests will be more equally-distributed among the replicas
because people from all over the world will issue such requests.
Put Protocol
The primary purpose of the put protocol is to guarantee that if
the client receives an acknowledgment message, the system will store
the data with very high probability.
Figure:
Psuedocode for client-side put functionality.
 |
The operation of the put protocol is shown in
Figure 5. First, the client chooses a replica to send the
initial put request to; that replica is designated the
primary. On receipt of the put request, the primary first
generates the appropriate object ID by computing the SHA1 hash of the
data, and atomically raises a busy flag (stored on disk) that
indicates a put operation is in progress.
Figure:
Psuedocode for primary replica put functionality.
|
Next, the primary invokes a local store method (shown in
Figure 3), which searches the object ID tree,
checking that the freshly-submitted object ID is not a duplicate. The
store method finds duplicates by checking that the OID of the
new file is already in the OID tree and that the hash of the file
pointed at by the tree node matches the hash of the new file. Here
the usage of a search tree simplifies the detection of duplicate
files, since the tree can be efficiently searched for a given OID.
Figure:
Psuedocode for secondary replica put functionality.
|
Next, store receives the data and computes its SHA1 hash in
order to verify it with the hash provided in the call. Then it finds
a suitable disk, given the size of the data that it is to write. It
then calls create and careful-write-file to write the
information to disk. The primary then adds all other replicas to a
pending list for the present object ID. Then it waits for a
background process to schedule those replicas on the pending list for
updates via the store operation. When the replica receives two
responses from other clients, it atomically lowers the busy flag and
returns an acknowledgment to the client.
Figure:
The sequence of messages sent in the course of a put
operation. The user receives an acknowledgment only after each
replica has acknowledged a store message.
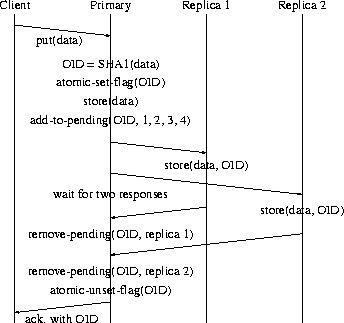 |
Failures may occur anywhere in the sequence of operations shown in
Figure 5. We designed the put protocol to ensure
that if a client receives an acknowledgment of a put operation,
then at least three replicas have the information contained within
that put request. Put uses a flag that is atomically
raised when the operation begins and atomically lowered right before
the client receives the acknowledgment and OID. If the system
crashes while the flag is raised, then on restart, the system will
know that the client never received an OID. If the flag is lowered
when the crash occurs, then on restart the system will know the client
did receive an OID.
The put procedure avoids phantom files (files which are not
present in the OID tree) but does not prevent missing files (when the
OID tree has a record of a file which does not actually exist) from
occurring. Phantom files are avoided because the node for an OID is
inserted into the OID tree before the file is actually written to
disk. Also, it is difficult for disk failures to cause phantom files,
since the OID tree is replicated. Thus, if a file is on disk, it will
be in the OID tree. By this same reasoning, missing files may happen
if the system crashes after the node is inserted in the OID tree but
before the file is written. This will not cause any problems because
the integrity-checker will detect the missing file and request it from
other replicas. All the other replicas will eventually notify that
they don't have the file; therefore the integrity-checker at the
primary site will get rid of the OID.
We list the possible points of system failure during the put
operation as follows. In each case, the system will remain in a
consistent state.
- 1.
- If the primary crashes before the flag is raised then there
clearly are no consistency problems because nothing has been written
to disk and the client will never receive any OID.
- 2.
- If the primary crashes after the flag is raised but before
store is called, then when the system restarts it will find the flag
raised and know that the client never received an OID. It will then
check the OID table and not see any nodes with the specific OID, and
it will tell all other replicas to delete that OID (even though none
of them will actually have that OID).
- 3.
- If the primary crashes after the store function has added
a node to the OID tree but before create-file has been called,
then when the system restarts it will find the flag raised and know
that the client never received an OID. It will check the OID table,
find the node with the OID it is looking for, delete this node, and
tell all other replicas to delete that OID (even though none of them
will actually have that OID).
- 4.
- If the primary crashes after the store function has called
create-file but careful-write-file has not completed, then
when the system restarts it will find the flag raised and know that
the client never received an OID. It will check the OID table, find
the node with the OID it is looking for, delete the node, delete the
partially (or not-at-all) written file, and tell all other replicas to
delete that OID (even though none of them will actually have that
OID).
- 5.
- If the primary crashes after the careful-write-file
called by store has completed but before add-to-pending
has completed, then when the system restarts it will find the flag set
on and know that the client never received an OID. It will check the
OID table, find the node with the OID it is looking for, delete the
node, delete the file, and tell all other replicas to delete that OID
(even though none of them will actually have that OID).
- 6.
- If the primary crashes after add-to-pending has completed
but before the flag has been lowered (which is when a second
acknowledgment is received), then when the system restarts it will
find the flag raised and know that the client never received an OID.
It will check the OID table, find the node with the OID it is looking
for, delete the node, delete the file, and tell all other replicas to
delete that OID (and some of them may have the file and will delete
it).
- 7.
- If the primary crashes after the flag has been lowered but
before an OID has actually been sent to the user, then when the system
crashes and restarts it will think that it has sent the client an OID
even though it has not. So the primary will find the pending list and
attempt to send the file to all replicas still in the list, as usual.
Hence the end result will be that the client thinks that the file has
not been stored, but it actually has been stored. If the client again
attempts to put the file into the repository, the replica will
detect a duplicate and send an acknowledgment. Although disk space
may be wasted if the client never again tries to put, nothing
worse will happen.
Inter-replica consistency is implicitly maintained by the repository's
distribution protocols. Whenever a new file is put into the
repository, the primary replica is responsible for ensuring that each
replica in the system eventually receives and stores a copy of the
file. For each new file, the primary creates a new pending list
containing every other replica. The significance of the pending list
is that replicas in the set still need to receive a copy of the new
file. When the primary receives an acknowledgment that a replica has
stored a file, the primary removes that replica from the appropriate
pending list. An empty pending list indicates that all replicas have
a copy of the file. The primary tries to empty each pending list by
periodically attempting to send the file to replicas still in the
list. The frequency at which each list is flushed decreases over time
using an exponential backoff similar to that used in
[#!ethernet!#, p. 400]. Thus, all replicas converge towards a
consistent state in which each file is at every replica.
Performance
We perform an average-case analysis for a put operation under
the assumptions that the primary is single-threaded and that the first
two replicas that the primary contacts respond immediately and at the
same speed. Tracing each step of the protocol1 we
see that the system meets performance specifications.
Get Protocol
The purpose of the get protocol is to obtain the file with a
specified OID. When the client issues a get command, the
software tries to contact each replica until it finds one which
contains the desired data. Each replica determines whether it has the
data by searching its object ID trees for the submitted OID as
described above.
Figure:
Psuedocode for client get functionality.
|
Figure:
Psuedocode for replica get functionality.
|
Whenever any data is transferred over the Internet, the receiving
replica recomputes the hash of the data and compares it with a hash
that was sent along with the data. If they do not match, the
receiving replica requests that the data be transferred again. When
clients issue get requests, they attempt to communicate with as
many replicas as necessary to find one which is available. Thus, only
if none of the replicas can be contacted will the get be aborted
because of network unavailability.
There are in fact no consistency problems associated with the
get protocol. A particular replica in the repository may write a
file to disk at the same time that it services a get request to
read the file. If the file is only partially written (and the OID of
the file is in the OID tree), then when the file is read, the computed
and stored hashes will not match, and the replica will return an
error. In that case, the repository software at the client's machine
will try another replica, and that replica will have the file. This
is because if a get request arrives at the same time that a file
is being copied to disk, then the replica is not the primary for that
file (otherwise the client requesting the file would have no way of
knowing the OID), so some other replica is the primary and will have
the file.
Performance
The client get procedure iterates over replicas until it
receives a positive response from one of them. While the worst-case
time for this operation is proportional to the propagation delay and
number of replicas, the common case is fast. We maintain a consistent
state across replicas so that the first request usually returns a
result to the client.
A new replica is created in two distinct steps. First, a new set of
hard disks is brought to a pre-existing replica, and its files are
copied onto the new set of hard disks. The files are copied by an
inorder traversal of the object ID tree at the pre-existing site:
files are copied onto the new disk as they are read by the traversal.
As each file is copied, we update a logical pointer on disk to refer
to the most recently copied file. To make the update of this logical
pointer atomic, it is implemented as two physical pointers with an
auxiliary bit indicating which physical pointer is in use. Thus the
copy operation will ensure that all files that were in the source
replica at that time will be stored in the new replica.
We estimate a lower bound on the time spent in the first step by
disregarding hard disk seek and rotational latency times:
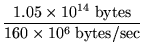 = 7.6 days.
= 7.6 days. |
|
|
|
Since the actual time spent in the first step (including seek and
rotational latency) cannot be more than a factor of ten greater than
this figure [#!handout33!#], we estimate an upper bound of 71 days to
create a new replica.
The second step ensures that all files stored in only a subset of the
replicas at the time the new replica is created will be stored in the
new replica. Before the start of the first step, each replica whose
pending list for a given OID is not empty adds the new replica site to
that pending list; this implies that the new site will receive every
file which has not yet been distributed to all replicas. Thus the new
replica will eventually receive every file which was put in the
repository before and during the replica creation operation.
Figure:
Psuedocode replica creation functionality.
|
At the replica level, each replica maintains a balanced tree data
structure in which each tree node is keyed by object ID and also
contains the directory name in which the corresponding data file
resides. This tree is replicated on three hard disks in order to
guard against failure of any one disk. Consistency is achieved
through a majority polling of the three data structures. We maintain
data integrity with a background process that runs at each replica and
traverses the object ID tree. For each node, the background process
computes the cryptographic hash of the corresponding file and compares
this hash against the hash stored in the file metadata. If they are
unequal, the replica requests a new copy of the file from another
replica.
New replicas are created by locally copying all disks of a
pre-existing replica onto a new set of disks and physically
transporting this set of disks to the new replica site. Protocols
shared by the put function and the replica creation function
ensure that a new replica will eventually become consistent with all
other replicas.
Integrity Checking
Intra-replica integrity is enforced by a background process that
traverses the OID trees, checking the integrity of the file associated
with each node and cross-checking the validity of the OIDs stored in
each tree.
The process first chooses one OID tree, called the master to
walk over. We choose masters cyclically to avoid problems with
missing files (see Figure 9,
Section 3.1.3). Then, for each node in the master
OID tree with OID x, we verify the directory entries for OID x in
the other two trees. If there is a discrepancy, majority polling
updates the fields of one of the three trees. An intolerable error
occurs if all three trees differ in their opinion of x's directory.
Next, for each OID-directory number pair (x, d ) successfully
verified, the process looks for the file named with x at d,
computes the SHA1 hash of the file data, and compares this computed
hash with the hash stored in the file metadata. If the two match,
then the file is presumed to be correct and the process continues to
the next node in the inorder master tree traversal. If the hash
values are unequal, then the file data is corrupt with high
probability, and the replica must request a correct copy of the file
from another replica site.
The integrity checking process maintains a current pointer on
disk which points to the most recently examined node in the master
tree. To make the updating of this pointer atomic, it is implemented
as two physical pointers with a bit switch, as in
[#!chapter8!#, p. 82]. After a node is checked, the process
increments the current pointer and atomically switches the auxiliary
bit. This feature prevents any interruptions in the integrity
checking process from influencing how often certain OID notes are
checked: all OIDs are checked equally often. This increases the
reliability of the system.
Figure:
Background integrity checking functionality.
|
The time to check the integrity of a single object can be estimated as
25.25 ms + 10 ms +  6 ms + 3 ms
6 ms + 3 ms 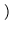 = 44.25 ms where 25.25 ms, 10 ms, and 9ms
are the estimated times for careful-read-file (see
Appendix A), computing a hash, and
setting an atomic pointer on disk.
= 44.25 ms where 25.25 ms, 10 ms, and 9ms
are the estimated times for careful-read-file (see
Appendix A), computing a hash, and
setting an atomic pointer on disk.
The total time to cycle through the entire object ID tree and check the integrity of each file can be estimated as
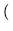 105, 000, 000 iterations 105, 000, 000 iterations 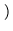 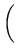 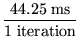
  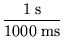
 |
|
|
|
 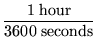
 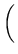 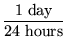
 54 days
54 days |
|
|
|
assuming there are no corrupt files and the tree contains all 105
million objects. The length of the integrity checking process thus
justifies the inclusion of the current pointer.
Our design functions in the presence of disk failures, including
single sector and whole disk failures. All data is written to disk
using careful-write-file, shown in
Figure 10. This procedure repeatedly writes to
disk, reads the data it has just written, computes the SHA1 hash of
the read data, and compares the hash with the stored hash in the file
metadata. If the hashes don't match, the procedure writes and reads
again; if the hashes do match, then the data has been successfully
written to disk. If the procedure tries to write to a sector and
encounters a transient error, it will repeat the write until the
hashes match. Data is read from disk using careful-read-file,
shown in Figure 11. This procedure reads from
disk and then computes and compares hashes until the hashes match;
thus transient failures while reading from disk are circumvented.
Hard errors on disk sectors are flagged and avoided by the file
system. If an entire disk fails, then the file system will mark every
sector in that disk as having a hard disk error, and the inter-replica
consistency mechanisms described previously will allow all data on the
failed disk to be obtained eventually.
Figure:
Psuedocode for careful writing to disk.
 |
Figure:
Psuedocode for careful reading from disk.
|
When a put request is directed to a primary replica, the primary
creates a pending list for the file, places each replica in the list,
and writes the list to disk. The pending list data structure is an
unordered list of the replicas that have not yet received the file.
A non-empty pending list implies that not all replicas have the
associated file. When the last replica is removed from a list, the
list is deleted; the absence of a pending list for a particular file
means that all replicas have a copy of that file. These properties
are useful in maintaining inter-replica consistency, as previously
described. A daemon process at each replica continuously cycles
through all the pending lists, and for each list tries to send the
associated file to the replicas in that list.
Design Alternatives
This section briefly describes alternate implementations of the
design and compares them with the recommended solution.
One alternative considered to using SHA1 as the OID was the
segmentation of the OID namespace into n ranges where n is the
number of replicas in the system. We use an OID of
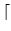 lg(1.05 x 108)
lg(1.05 x 108) = 27 bits. Then, if a client chooses replica
i
= 27 bits. Then, if a client chooses replica
i 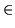 [1, n] as the primary, i arbitrarily assigns an OID only in the
range
[1, n] as the primary, i arbitrarily assigns an OID only in the
range
 227
227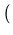
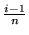
 , 227
, 227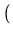
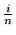
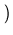
![$ \left.\vphantom{ 2^{27} \left( \frac{i - 1}{n} \right), 2^{27} \left(
\frac{i}{n} \right) }\right]$](img54.gif) . This method is desirable because like
the recommended design, it obviates the need for put and
get protocols to keep OIDs from conflicting with each other.
Additionally, a segmented OID namespace allows much shorter
OIDs--27 bits instead of 160 bits--making OIDs human-readable.
Finally, a segmented namespace causes conflicting OID assignment
with probability 0, while the recommended design offers very low
probability of OID conflicts.
. This method is desirable because like
the recommended design, it obviates the need for put and
get protocols to keep OIDs from conflicting with each other.
Additionally, a segmented OID namespace allows much shorter
OIDs--27 bits instead of 160 bits--making OIDs human-readable.
Finally, a segmented namespace causes conflicting OID assignment
with probability 0, while the recommended design offers very low
probability of OID conflicts.
We chose the recommended solution over the segmented namespace design
because the segmented namespace places a limit on the number of OIDs
that may be assigned by one replica. Since most requests are coming
from one geographical area, we expect that one replica will be chosen
as primary most of the time. This will exhaust the namespace of that
replica quickly, leaving the system unable to accept new requests
without a more complicated mechanism of addressing the problem. With
regard to conflicts, the probability of any two OIDs in the system
conflicting is sufficiently small (approximately 2-104
[#!handout33!#]) that the hash method is preferable.
Another alternative for OID implementation was use of the Library of
Congress call number, Dewey Decimal System call number, or ISBN
number. This approach requires the user to externally supply the
object identifier as an argument to the put request. One
problem with this method is that it requires an additional mapping
between the filename and OID, since the two are not identical. In
contrast, the recommended solution does not require that this mapping
be kept in any data structure; it is instead implicit in the system.
Also, since correctness of the stored information requires that the
system trust the client, the reliability of the system is compromised.
Therefore, we decided against this approach.
Initially, we chose to implement the OID to filename mapping as a
table. The use of table is convenient for a system that uses
sequential OID. Tables keyed by OID make it easy to locate the entry
corresponding to an OID. Even though we are not using sequential OIDs,
we could still maintain the sorted OIDs in a table. However, tables
are inconvenient for inserting elements. It is more convenient to use
a balanced tree structure for that purpose, since it makes it easy for
searching and inserting elements that do not have sequential ordering.
An alternative method that we considered for replica creation was to
copy files directly over the Internet, or on CD-ROM. However, we
ruled out these alternatives because of time constraints on the
creation of a new replica. If we assume a U.S. domestic Internet
connection, then since the network bandwidth will be the limiting
factor in the transfer, we estimate that the copy replica operation
will take
at worst, and
at best (using the estimates on Internet bandwidth given in
[#!handout33!#]). If we copy files on CD-ROM, we must complete two
separate copy operations, one at the source site and one at the target
site. Each copy operation is again limited by the bandwidth of the
CD-ROM, so we estimate an lower bound on the time for this method by
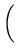 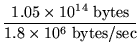
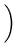 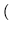 2 operations 2 operations 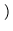 = 3.7 years.
= 3.7 years. |
|
|
|
Each of these estimated times is prohibitively long; we thus chose the
recommended solution instead, yielding a copy time of 7.6 days.
One possible way to achieve additional redundancy is to use some level
of RAID [#!raid!#] within each replica site. This might enable
replicas to correct some errors without having to request a file from
another replica. The drawback is that even more disks would be
necessary, and operations such as write-file and read-file might take
longer to complete because the redundant disks might have to be
written or read. We decided that the redundancy provided by multiple
replica sites was adequate for our needs and that the additional
redundancy of RAID disks did not justify the added complexity and
overhead.
Conclusion
In this paper, we have reviewed the desirable criteria of a digital
repository. Integrity of stored data is by far the most important
property of the repository: once put, a file should never be
lost. Our recommended solution relies heavily on redundancy to
maintain data integrity. Multiple replica sites, the use of
cryptographic hashes, mirrored copies of the OID tree at each replica
site, and the storage of the hash in both the OID tree and the file
metadata are all examples of redundancy in guarding against failure.
Finally, we compared our solution with several design alternatives for
the assignment of OIDs and and for OID-to-filename data structures.
As the price per megabyte of persistent storage continues to drop,
applications such as digital libraries will likely continue to
increase in importance. Effective designs for storing large amounts
of data will be necessary when a very high degree of fault-tolerance is
required. There will always be tradeoffs between size and
reliability, and a good design addresses these issues to ensure the
integrity of data.
2
Performance Estimates
This appendix gives performance estimates for some of the low-level
file operations. Time estimates made in the previous sections are
based on these figures.
Time spent in read-file for the successful completion of a 1
MB read operation:
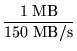 + 6 x 10-3 s +
+ 6 x 10-3 s + 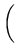 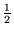 rotation
rotation  |
|
|
|
 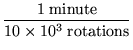
  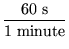
 = 15.25 ms
= 15.25 ms |
|
|
|
Time spent in careful-read-file for the successful completion of
a 1 MB read operation:
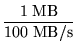 + tread - file = 25.25 ms
+ tread - file = 25.25 ms |
|
|
|
Maintaining the Integrity of a Digital Library
This document was generated using the
LaTeX2HTML translator Version 98.1 release (February 19th, 1998)
Copyright © 1993, 1994, 1995, 1996, 1997,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 -no_navigation -no_math -html_version 3.2,math paper.
The translation was initiated by Kyle A. Jamieson on 1999-06-28
Footnotes
- ... protocol1
- From
Figure 5 we see that the time for a put operation is
the sum of the following delays: transmission delay (client to
primary), latency (client to primary), hash computation time (at
primary), careful-write (at primary), add-pending (at
primary), transmission delay (primary to replica), transmission delay
(primary to replica), latency (primary to replica), hash computation
(at replica), careful-write (at replica), transmission delay
(replica to primary), latency (replica to primary),
remove-pending (at primary), latency (primary to client). Note that
only one primary to replica latency is included in this calculation
since only the primary to replica #2 latency is on the critical path
of the protocol, given the assumptions stated above. We use the
following numerical estimates: average data size = 1 MB, network
bandwidth = 10 MB/s, transmission time = 10 ms, hash computation
time = 100 MB/s. Substituting these numbers in the above expression
gives 2.92 seconds per transaction, well under the required upper
bound described in Section 2.5.
Kyle A. Jamieson
1999-06-28