6.033 Review Session - Naming
- Questions on Naming: pages 10-12 through 10-14 of review packet
- Errors:
- Question 5.5 - answer is (1996-2-1b) not (1996-2-1a)
- Question 5.7 - answer is (1987-1-2a) not (1985-2-2)
- Relevant Papers:
- Class Notes Chapter 5
- Grapevine
- NAT
Naming
- reference - used to refer to objects
- used for:
- sharing
- interconnection
- location
In reference to Figure 5.2 in the class notes:
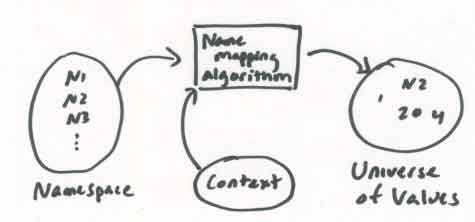
- Name Space - set of possible names.
- Universe of Values - set of all possible values being referenced.
Can be objects, or other names.
- Context - additional data needed to resolve a name. (often table of
name-> value mappings)
- Name-mapping algorithm - provides actual mapping/association between
name space and universe of values.
Name-mapping algorithms:
- Simple table lookup
- table of {name, value} pair
- Ex: telephone book, page table in VM system
- Path name resolution
- absolute - uses wired-in context reference to resolve (like root)
- relative - use different, default context to resolve
- Ex: web.mit.edu
/usr/bin/emacs
- Search
- Multiple table lookups
- ex: setting PATH environment variable to specify where programs are
to be found.
- search not perfect, can return "wrong" value
Context References:
- Important distinction:
- Context is the actual set of bindings/mappings of names to values
- Context Reference is the name of the context
- default - wired in or dynamically determined from environment
- explicit - specified for particular object or "packaged" in name
(qualified name)
Other random information (should also study rest of notes):
- metadata - data about the data. relevant information about the
object, can be contained within the object or outside of it.
- overloading - putting more into name than is needed for reference.
- ex: .jpg extension to show file type
Rendezvous
- protocol for obtaining name
- recursive - need to know 1st place to search to start
UNIX
- uses several layers, hierarchy, corresponding to physical layers
(hardware up to software)
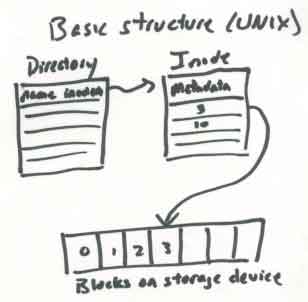
- blocks on storage device
- inodes - group blocks into files
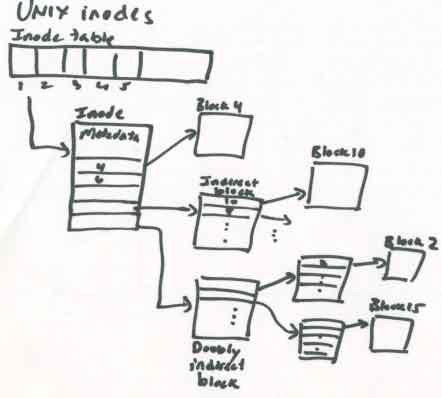
- inode structure - metadata, then block IDs
- last two entries of inode point to indirect and doubly indirect
blocks instead of data blocks
- indirect block - points to a block that is just a list of block IDs
- doubly indirect block - points to a block that lists a bunch of
block IDs of indirect blocks.
- indirect and doubly indirect blocks increase the number of blocks
that can be mapped to a file
- directories - organize inodes
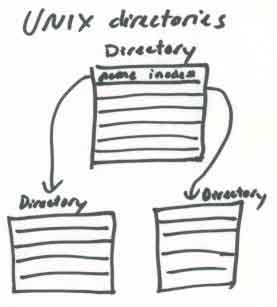
- name to inode mappings
- implemented as file
- can contain entries for other directories
- went over Question 5.1 on p.10-12. Answers in back of review
packet.
DNS
- resolution between user-readable names and Internet addresses
- hierarchical - each name server responsible for specific domain/part
of name space
- iterative resolution of ginger.lcs.mit.edu

- ask root name server
- root name server returns "edu is at __"
- ask edu name server
- edu name server returns "mit.edu is at __"
- ask mit.edu name server
- mit.edu name server returns "lcs.mit.edu is at __"
- ask lcs.mit.edu name server
- lcs.mit.edu name server returns "ginger.lcs.mit.edu is at __"
- can also do recursive resolution - ask a name server, it does the
rest of the lookups for you and then returns the answer
- if do recursive, can cache responses in that name server so that it
can respond to future queries with less delay.
- DNS also has replication for robustness, allows synonyms - all in
notes.
Also, make sure to study URL and anything that wasn't covered here.
Make sure you have a familiarity with the terminology and are
comfortable how it is used and where it applies to various systems.
Lots of examples to help you get a feel for this in the notes.