| Testing the Model (ppt) | Predicting Behavior (ppt) | Matlab source files |
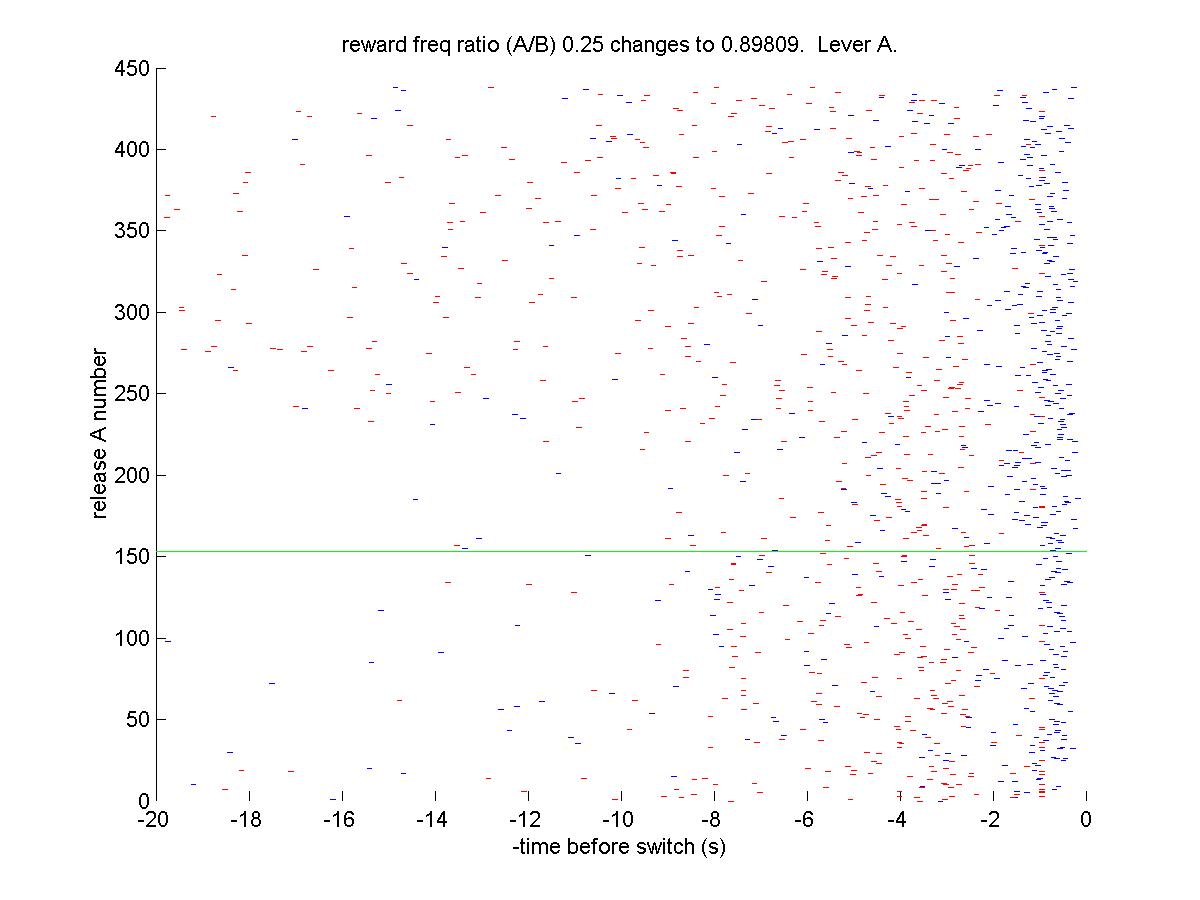
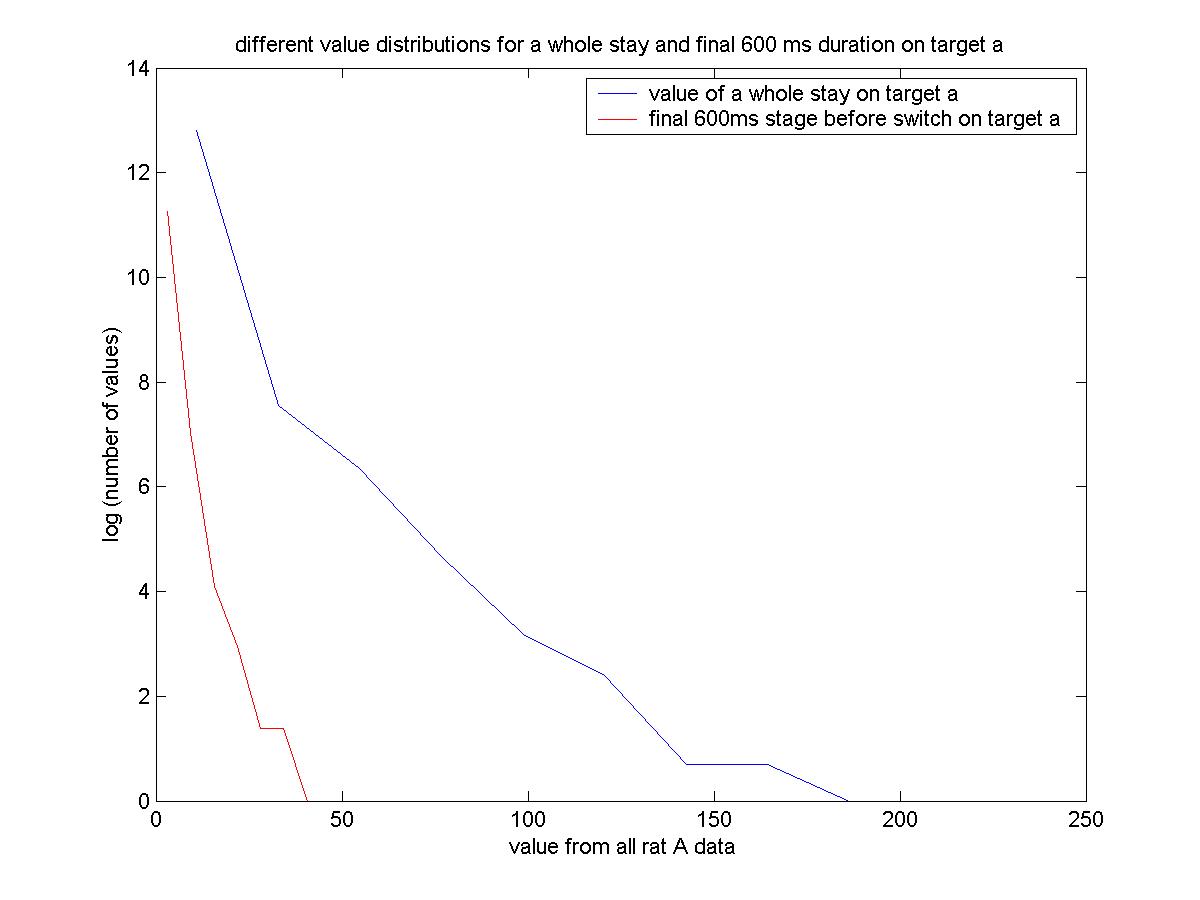
| Abstract: In some perspective, life is a process of making decisions. To make decisions for better rewards, animals will consider the values of response options, which probably affect animal behavior, such as switching their foraging sites. Here with the given data, I tested the matching law with animal behavioral data and leaky integrator model based on reward history to simulate the values of two possible alternatives that animals can choose in the experimental paradigm. |