6.033--Computer System Engineering
Suggestions for classroom discussion of:
Jim [N.] Gray, Paul McJones, Mike Blasgen, Bruce G. Lindsay, Raymond
[A.] Lorie, Tom Price, Franco Putzolu, and Irving [L.] Traiger. The
recovery manager of the System R database manager. ACM Computing
Surveys 13, 2 (June, 1981) pages 223-242.
by J. H. Saltzer, April 30, 1996, from 1982 recitation notes and 1984
teaching staff notes. Updated 1998, May 2001. April 2002, and May 2003.
(Reminder: appendix 8-C of the notes is a guide to reading this paper.)
System R consists of two parts, the data management system and the
underlying storage system, called RSS. This paper examines in detail only the
storage system, but the requirements on RSS are imposed by the higher layer
data management system and aren't always explicitly mentioned in the paper.
Why is RSS so very complex as compared with the atomicity
algorithms described in chapter 8 and in the lectures? (Performance is one
prime reason. To make a high-performance storage system, the system R
designers used disk buffering with lazy write strategies. But since RAM
buffers are volatile, the buffering interacts fiercely with the atomicity
algorithms. The write-ahead log protocol requires careful control of the order in
which writes touch the disk, and this control is hard to exert through a
buffer cache. Page-level locking--described in another paper--is another
performance enhancement that increases complexity.)
Another reason is that there are several simultaneous goals. What
are they?:
(- archiving: keeping old data values in case the user needs to look at
them again.
- recoverability: the system may crash, and invidividual in-progress
transactions may abort, but committed transactions are always remembered.
- storage modularity: data may cross page boundaries.
- storage efficiency: pages may contain data of different transactions.
- coordination and isolation: the locks aren't mentioned in this
paper, but they must have complicated the design.)
A third reason has to do with a change of goals. What changed?
(Early on, their model was that data should survive crashes, so
they focused on implementing recoverable *objects* and invented shadow pages
to help make this happen. Later, they realized that it is also important to provide consistency between different objects, which requires recoverable *transactions*. So they added the log. In making that addition, they didn't rip out the shadow pages, instead they designed a log system that took advantage of the fact that the shadow pages were already there. So RSS ended up with
both mechanisms.)
Yet another view is that there are several interacting mechanisms.
List the mechanisms:
( - Shadowed files
- Log copy of new/old record values [the EXOR log was a later idea]
- Log record of transaction start/end/save
- Log record of system checkpoint
- archive copy from disk -> tape
- RSS actions are individually atomic
- Log is duplexed)
Let's work through these mechanisms one at at time. What do they
mean by "shadow file"? Is this like the shadows of the RAID system?
(No. The RAID people used the DEC definition of "shadow", which means
replication. IBM calls replication "duplexing". IBM uses the term
"shadowing" for the idea, described in chapter 8, of "work on a copy of
the data rather than the original."
RAID DEC IBM
multiple, identical
copies mirror shadow duplex
modify a copy, not
the original shadow
unit of disk
storage block page
How do shadow copies work? (When a file is opened for writing, its
catalog entry is read from the disk into primary memory. The primary
memory copy of the catalog entry is expanded slightly to contain not one,
but two pointers to the page map that shows where on disk each page of the
file is actually stored. Until the instant when the file is actually
written, both "current" and "backup" point to the same page map. When the
first write occurs, the system allocates a second page map, filled with the
same file block pointers, and places a pointer to the new page map in
"current". It also allocates a new page, writes the data to that new page,
and places a pointer to the new page in the "current" page map. FILE SAVE
flushes any unwritten pages from the disk buffer, writes the second page map to disk, writes the directory to disk, sets backup to current,
and releases any file blocks that appear only in what was the backup page
map. FILE RESTORE sets current to backup and releases any file blocks
found only in what was the current page map.)
Suppose that we crash before doing the FILE SAVE step? Could we
use the "current" page map to get to the latest versions of the data?
(No--because there is no assurance that the data mentioned in the current
map is actually on the disk--it may have never gotten beyond the RAM buffer cache.)
The shadow copy is for a whole file at a time. What if two
transactions T1 and T2 both are writing data to different pages of the
same file? When a FILE SAVE occurs don't both transactions get
committed? (No. FILE SAVE has nothing to do with committing the
transaction, it is done only to coordinate with checkpoints as part of
crash recovery, not for transaction consistency.)
Then when is a transaction committed? (When it writes a commit
record in the log. Until that time, no one else can see its data--locks
prevent this, but the paper doesn't talk about them--and if the
transaction aborts its changes will be backed out by UNDOing the transaction unless we crash before the next SAVE following Commit. We need to start talking about how the log works.)
It says the log is duplexed. What does that mean? (See definition
above. They make two copies. This is a simple redundancy measure; two
copies proved adequate.)
But what threat does duplexing the log counter? (hardware decay
failures; the goal is to force copies onto different physical drives.)
Doesn't it also help with software failures? (Not really, because
independence is needed, and software errors will probably affect both
copies.)
Doesn't the log also provide archiving? (It doesn't provide
archiving by itself, but it helps in the archiving process.
there is a distinct archive mechanism, and the log's primary purpose is to
be the transaction atomicity mechanism. This difference is one of the
keys to untangling much of what is going on in System R.)
How far back does the log go? (Long enough to include
- every incomplete transaction
- the latest checkpoint
- the latest time when data was archived to tape
The authors describe the log as "on-line", meaning that because it
doesn't go back to the beginning of recorded history, they can keep it in
a file that is on the disk. Some systems have logs that go back forever,
so the beginning of the log is usually on a series of tapes, dismounted
long ago, with only the most recent log entries available on disk. When
you see a log like that, the designers are probably using the log as an
archive.)
This model suggests that System R distinguishes among three
apparently similar things: Archiving, Replication, Journaling. What
are these functions, more precisely?
(
- Archiving:
- keep a record of old data values, for future auditing
- Replication:
- fight back against hardware decay of current data values
- Journaling:
- group updates to different records into recoverable transactions)
Doesn't log replication also provide extra read performance and
convenience of access? (For things that are read a lot, this is
certainly a possibility. But if no crashes occur and no transactions
abort, noone ever reads the log, so read performance improvements seem
uninteresting. So system R doesn't pick up on this opportunity.)
What is a "write-ahead log"? (The protocol is that you always put
a record of proposed changes to data in the log before making those
changes to the data itself.)
What good does that do? (It is part of the pre-commit atomicity
mechanism: make sure that you can back out. It guarantees that all
modifications to data can be discovered and undone, if necessary, by
examining the log. If the data were modified first, and a crash occurs
before the log is written, those data changes could never be discovered
to decide whether or not they should be retained. Chances are they are
part of an incomplete transaction that should be backed out.)
How can System R use a WAL protocol given that it has an
LRU-managed disk buffer pool? If the LRU algorithm decides when to
write a particular page out, how can anyone be sure that the log gets
written to disk before the data? (The shadow file system provides
the missing, precise control. If the LRU buffer pool decides to
write a new page out, that affects only the "current" copy, which
will be automatically discarded if the system crashes. Only when
someone does a SAVE_FILE does the data become visible. So the WAL
protocol in system R becomes "make sure the log page that mentions a
file update is written to disk before doing a SAVE_FILE on that
file." The paper doesn't say much about log writing, but it does
talk about forcing the log, which means writing any buffered log pages
to disk.)
How is the log implemented? (This is one of the
things that is hard to read out of the paper. Parts of the mechanics
are described in four different places, and some things are left for
speculation. Some of the following comes from reading between the lines,
and may be wrong. But it is all consistent with what the paper says.
- They allocate a separate disk partition--called an "extent"--to
hold the log. (p. 240) If duplexed, there are two such partitions.
- There is a log manager program that directly reads and writes to
this partition; the log is not a file in the file system.
- The log partition is managed as a big ring buffer of disk sectors.
(p. 236) The next log page to be written goes into the next sector
of the partition.
- There is a single RAM buffer for the log; that is where things are
"written to the log". (p. 232) When the buffer fills, it is written to
the disk into the current log sector, the buffer is cleared, and the
record of the current log sector advanced by one. When checkpoints and
commit records are written, the current buffer is simply written to the disk in the current log sector. This is what "forcing the log" means.
Does System R use a backout-list or an intentions-list logging
protocol? (Yes. It uses a backout-list protocol for things before
the latest checkpoint and an intentions-list protocol for things
after the latest checkpoint.)
Suppose that a transaction decides that it has gotten into
trouble--perhaps the client looked at the available hotel room and
decided to cancel the trip--how does it UNDO? (go to the log, follow
the chain of events for this transaction backward, undoing each action.
When you get to the START record, the effects of the transaction are
completely undone.)
Suppose instead that the system crashes. How is atomicity of
transactions guaranteed?
(The key observation is that since System R always writes transaction data
to shadow files, those writes always go to a copy that doesn't become
permanent until someone does a FILESAVE. If a crash occurs after a write
but before a FILESAVE, it is as if that write never happened.)
Now consider four different ways System R could be organized to take
advantage of this property of shadow files.
First, suppose no one ever calls FILESAVE. What would things look like, and how would recovery go?
(In that case, the system might
run all day, logging planned writes and then doing those writes, and then
logging commits. Then, a crash occurs. All writes are lost; the
disk looks just like it did when the system started--except for the log,
which is not a shadowed file, it is in a partition of its own. But since
the log contains all the writes and commit records, we can recover by
REDO'ing every committed transaction.)
When a crash occurs, how can we identify the committed transactions?
(Every commit includes forcing the log to disk, so that
data is safely stored. So we start at the last written page
of the log and work backwards looking for commit records. When we get to
the front of the log we have a complete list of all commit records. Then
we can scan the log forward, and make sure that every data change
belonging to a committed transaction actually has been made to the \corresponding file as seen on the disk.)
Second, suppose that System R watches, and whenever it notices that things
are quiet and there are no active transactions (every transaction that has
begun has committed or aborted) it takes the opportunity to perform a
FILESAVE on every open, shadowed file. Then, sometime later, a crash occurs.
(It now needs to REDO only transactions that committed after the FILESAVE.
The log from before that point can be discarded.)
Third, suppose instead that system R performs a FILESAVE (again, on every
open, shadowed file) every time anyone commits any transaction. Then, after some more work, there is a crash.
(All writes up to that commit are permanent, even writes for
uncommitted transactions that happened to be in progress at the time the
most recent transaction committed. All writes after that commit are as if
they had never happened. From this state, we can recover by UNDO'ing the
logged writes of every transaction that was pending at the time of the last
commit.)
Last (this is what system R actually does) suppose that the only time
anyone every issues a FILESAVE is at a periodic checkpoint, say every ten
minutes, and we make a log entry to show when the checkpoint was taken.
(If
a crash occurs after a checkpoint, all writes up to the checkpoint are
permanent (perhaps including some writes for transactions that never got to
commit), all writes after the checkpoint are lost (perhaps including some
writes for transactions that did commit). So the recovery procedure is to
REDO any writes after the checkpoint that belong to committed transactions,
and UNDO any writes before the checkpoint that belong to losers.)
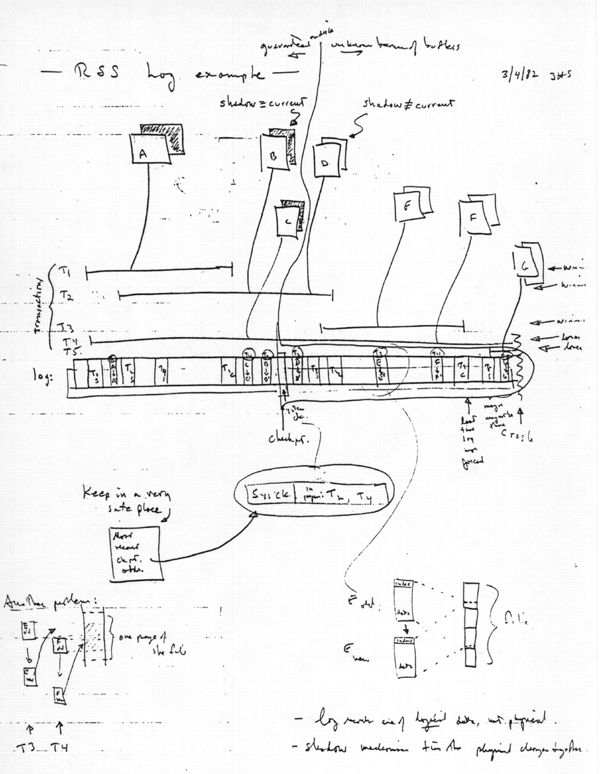
At this point it is appropriate to sketch a log
scenario on the board such as the one of figure 11 on page 235 of
the paper, with the addition of
pointers to show the status of shadow versus current pages for various
files that the five transactions may happen to have open. For an
example, there is
a scan of a nearly unintelligible hand-drawn figure. (Karen Sollins contributed easier-to-read
Acrobat and
PowerPoint versions of most of that same figure.
The idea is to examine each of the transactions T1 - T5 in turn to see how
it is affected by a system crash at the point indicated. Those five
transactions include every possible combination of {completed, incomplete}
at crash time and {preceding, spanning, following} the latest checkpoint.)
How about a transaction that
aborted just before the crash? It has recorded an ABORT
record in the log but its UNDO's are trapped in the buffer
cache. (While doing the log scan we should have made a list
of them, too, and made sure that every change they made has
actually been undone. This set of COMMITed and ABORTed
transactions is called the list of "winners".)
Another transaction may have written several changes to the log, and
also done FILESAVE on those changes, but not yet committed at the time of
the crash. What about those transactions? (During our backward log scan
we also made a list of "losers" and performed UNDO on any modifications
they made.)
How are losers discovered? (The first evidence of their existence
during the LIFO log scan is a MODIFY record in the log, rather than a
COMMIT or ABORT record.)
So what is a checkpoint? (A note in the log intended to help reduce
the distance back you have to scan.)
What is the simplest checkpoint contents? (A note saying "Hey,
look. There aren't any outstanding transactions right now so I just
flushed the disk buffer cache and did a FILE_SAVE on all open files.)
Why does that limit the distance back that we have to review the
log? (Because when you come across such a note, you know that your list
of winners and losers is complete. There can't be any more losers,
because when the checkpoint was written there weren't any outstanding
transactions. There is no need to look for more winners because we are
assured that all the data of older winners--both committed and
aborted--is safely on the disk in shadow = current versions.)
So why don't we write checkpoints frequently? (We may go a long
time before we see an instant with no transactions in progress.)
How does system R deal with that problem? (By writing hairier
checkpoints. 1. Write a note on the log giving a list of all
outstanding transactions. 2. Do a FILE SAVE on everything in sight.
3. Pray that we don't crash halfway through doing the checkpoint.)
Why does that help? (When the LIFO log review comes to this
checkpoint record it can immediately complete its list of winners and
losers--any transaction it hasn't run across later in the log it adds
to its list of losers. Then it has to continue scanning till it finds
the START record of the earliest-starting loser, but that is as far as it has
to go back.)
What about the shadow state of files? (With checkpoints, there is a
subtle modification to the protocol. The *only* FILESAVE operations to
data files are done by the checkpoint routine. The log is forced to disk both
at checkpoint time and also whenever a commit record is written.)
How does that help? (A simplification--one of the few in System
R--anything shown as modified after the checkpoint has already been
UNDONE by the change of backup -> current. So we only need REDO
winners' modifications that are logged following the checkpoint.
Anything logged as modified before the checkpoint was recorded by the
change of current -> backup that was done by the FILESAVE at checkpoint
time. So we need to UNDO only losers' modifications that were logged
before the checkpoint.)
What is this about praying that we don't crash halfway through a checkpoint? These guys seem to be pretty smart; didn't they come up with a more systematic method that doesn't involve prayer? (Yes, but you have to read between the lines to discover it. Checkpointing really comprises
- write a checkpoint record to the log.
- force the log to disk
- force all shadow page maps to disk
- force to disk new directory entries that refer to the new page maps
- force to disk a new copy of the file system directory, that contains these new directory entries.
- write a one-sector root record (that contains the pointer to the file system directory and the pointer to the log address of the checkpoint) twice, using a recoverable-put algorithm like the one described in chapter 8.
If there is a crash any time before the last step completes, when the
system comes back up it will find the original root record, and none of
the stuff written in the previous steps will be visible, so it looks as
if the entire checkpoint hasn't taken place yet.
So at the end it all comes down to a careful-put of a single sector as
the last step of the recoverable-put.
All this comes from studying a three-sentence explanation on page
234. (Thanks to John Chapin for sorting it out.))
(From Seth Teller) The System R paper doesn't mention file
open or file close operations, and thus it doesn't say anything about
the relation between those operations and SAVE_FILE. In particular,
does closing a file force a SAVE_FILE? If it did, that might
interact with the recovery system. (File open and file close
operations occur when the application starts in the morning or shuts
down for the day, and all files of interest to the application simply
remain open during normal operation of the system. Thus file close won't
happen until all transactions have been recorded, saved, and committed.
This is a database system, not a file system.)
Can you find any examples of fail-fast design in System R? (Page
226: "System R initiates crash and restart whenever it detects damage to
its data structures". Page 227: "We postulate that these errors are
detected and that the system crashes before the data are seriously
corrupted".)
Page 227 invokes Murphy's law. What is Murphy's law? (Something
different from what these authors think. See sidebar in chapter 1, appendix A.)
Section 1.1 says that each RSS action is atomic. How do they
achieve atomicity of these actions? (The paper doesn't tell us. We
have to take it on faith. Or read between the lines, as in the description of how the checkpoint action is atomic.)
How does RDS achieve atomicity? (The RSS recovery functions BEGIN,
ABORT, COMMIT, UNDO, together with write logging are tools to be used
by RDS to achieve atomicity of transactions implemented by RDS. We
have a two-layer atomicity model here.)
Section 2.9, on Media Failure, says that archive copies are made by
copying the data on disk to tape. What makes this such a complicated
job? (The goal is to get a consistent snapshot, so the copy to tape
should be made atomically with respect to current activity.)
Here is a simpler method: wait till an instant when there aren't
any transactions outstanding, start copying to tape, and refuse to start any
new transactions till the tape is complete. Why didn't they choose that
technique? (You may wait forever for a time when the system is
quiescent. And even if you find one, the time required to make the copy
to tape is too long to delay start of new transactions.)
So what do they do instead? (Make a "fuzzy dump" to the tape without
quiescing the system. Dump the current log to tape also. Later, use the
log copy to "focus" the tape copy. Gray says in another paper, "the details
of the algorithm are left as an exercise for the reader." Presumably the
exercise consists of choosing a serialization instant for the dump, and
making sure that the log contains the outcome of every transaction what
wasn't yet committed or aborted at that instant. At restore time, one
can run the log forward and complete or abort those transactions that
committed or aborted before the serialization instant.)
Does this exercise result in the equivalent of an atomic dump?
(Yes. It is as if the dump had been done atomically at the chosen
serialization instant. All transactions that committed or aborted
before that time are represented correctly in the restored copy; any
transactions that committed or aborted after that time do not exist.)
Although not mentioned anywhere in the paper, System R raises an
interesting trade-off among security, privacy, and reliability. Suppose
you are managing a database using System R, and the FBI comes to you with a
report that one of your employees has recorded a state secret--the
president's cell-phone number--in your database. They want you to delete
it. You initiate a transaction that modifies the database, and the
transaction commits. Is the information gone? (Customers who enter the
database through its RDS interface won't see the secret data--unless the
system crashes, damages the disk, and has to be restored from last week's
archive tape. In addition, a system wizard intent on doing so can almost
certainly locate that phone number. The shadow page with the old data is
probably still on the disk somewhere, until it happens to be reallocated to
some other purpose and rewritten; there are two copies of the log on the
disk, each containing old and new data values, the log has been written
onto the most recent archive tape, and all of the old archive tapes still
contain the secret data. A typical policy on archive tapes is to keep one
each month for a year, and one each year forever. So you may never be able
to assure the FBI that the information is really gone. It can be very hard to
really expunge data in a system that employs redundancy. System R is designed not to forget things.)
The assignment question from 1992: When system R takes a system
checkpoint it waits until the system state is action consistent but not
transaction consistent. Discuss briefly the reasons for this decision
and its implications for recovery.
There are several very useful questions that might be used to spur
discussion on pages 7-101 and 7-102. The following two additional
discussion questions were suggested by Eric McDonald:
1) System R possesses the property of "consistency," essentially
transforming concurrent transactions on a shared object (i.e. a file)
into a serial set of transactions. Discuss the reasoning behind this
decision. Describe a situation involving concurrency and shared
objects where System R could cause problems if it didn't serialize
concurrent transactions on shared objects.
(2) In section 3.9, the authors describe their failure to include a
recovery system for output messages as a "major design error." Do
you think they're being a little hard on themselves? Try to identify,
by giving two significantly different real-world examples, why they're
so concerned with message recovery.
Comments and suggestions: Saltzer@mit.edu
{kind=link}