Language and Vision Ambiguities (LAVA) Corpus
Language and Vision Ambiguities (LAVA) is a multimodal corpus that supports the study of ambiguous language grounded in vision. The corpus contains ambiguous sentences coupled with visual scenes that depict the different interpretations of each sentence. LAVA sentences cover a wide range of linguistic ambiguities, including PP and VP attachment, conjunctions, logical form, anaphora and ellipsis.
Examples
| Sentence |
Visual Setup |
Video |
Image |
Syntactic Parses |
Semantic Parses |
| Danny approached the chair with a yellow bag. |
- Danny with bag
- Chair with bag
|
 
|
 
|
  |
- λx.λy.λz.person(x)∧chair(y)∧bag(z)∧yellow(z)∧has(x,z)∧approach(x,y)
- λx.λy.λz.person(x)∧chair(y)∧bag(z)∧yellow(z)∧has(y,z)∧approach(x,y)
|
| Danny looked at Andrei picking-up a yellow bag. |
- Danny picking-up bag
- Andrei picking-up bag
|
 
|
 
|
 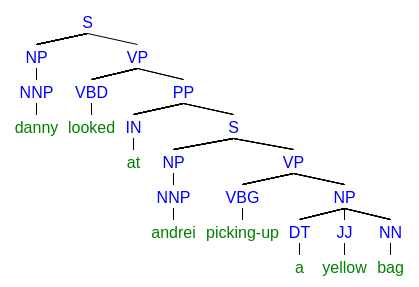
|
- λx.λy.λz.yellow(x)∧bag(x)∧person(y)∧person(z)∧look-at(y,z)∧pick-up(y,x)
- λx.λy.λz.yellow(x)∧bag(x)∧person(y)∧person(z)∧look-at(y,z)∧pick-up(z,x)
|
Download
This corpus is available to the public here.
Reference
Yevgeni Berzak, Andrei Barbu, Daniel Harari, Boris Katz, and Shimon Ullman (2015). Do You See What I Mean? Visual Resolution of Linguistic Ambiguities. Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal. [PDF]
Acknowledgment
This material is based upon work supported by the Center for Brains, Minds, and Machines (CBMM), funded by NSF STC award CCF-1231216.