
Click to see entire strip...
Auditory recognition and classification based on changes in attentional state.
Click to see entire strip... |
The team |
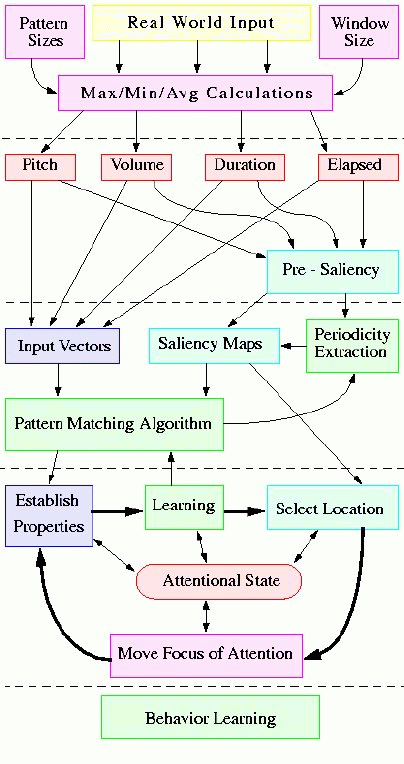 |
Input LayerThe input provided by the MIDI file is preprocessed to calculate Pitch, Volume, and Duration values, as well as a voice index. The voice index need is replaced by the time elapsed value, which makes the use of voices general enough to allow for a dynamic reordering of voices. Maximum, minimum, and average values within a window are calculated for each of them in a pre-processing step. Input Details... Saliency LayerBased on these values and their maximums, minimums and averages, saliency values are calculated for each piece of data and their derivatives. This results in saliency maps which make different vectors stand out, depending on what feature one is paying attention to. Saliency Details... Pattern MatchingThe pattern matching algorithm will be biased in matching the values which are salient on the vectors which are salient. Patterns of varying lengths will be stored for salient vectors, and matched as new inputs come in. Pattern Details... PredictionWhen a pattern is matched partially with the current input, the system will predict future notes as the continuation of the stored pattern. Since more than one patterns will be matched (at least one for each pattern length - one for every pattern table), a weighted average will be calculated, depending on certainty and pattern length. Prediction Details... |