Marple
Language-directed hardware design for network performance monitoring
Marple is a language for network operators to query network performance. Modeled on familiar functional constructs like map, filter, groupby, and zip, Marple is backed by a new programmable key-value store primitive on switch hardware. The key-value store performs flexible aggregations at line rate (e.g., a moving average of queueing latencies per flow), and scales to millions of keys. We have built a Marple compiler that targets a P4-programmable software switch and a simulator for high-speed programmable switches. Marple can express switch queries that could previously run only on end hosts, while Marple queries only occupy a modest fraction of a switch’s hardware resources.
Conference paper Compiler source Tech report Try it in mininet!
Network performance monitoring today is restricted by existing switch support for measurement, forcing operators to rely heavily on endpoints with poor visibility into the network core. Switch vendors have added progressively more monitoring features to switches, but the current trajectory of adding specific features is unsustainable given the ever-changing demands of network operators.
Instead, we ask what switch hardware primitives are required to support an expressive language of network performance questions. We believe that the resulting switch hardware design could address a wide variety of current and future performance monitoring needs.
We apply language-directed hardware design to the problem of flexible performance monitoring, inspired by early efforts on designing hardware to support high-level languages. Specifically, we design a language that can express a broad variety of performance monitoring use cases, and then design high-speed switch hardware primitives in service of this language. By designing hardware to support an expressive language, we believe the resulting hardware design can support a wide variety of current and future performance monitoring needs.
The figure below provides an overview of our performance monitoring system. To use the system, an operator writes a query in a domain-specific language called Marple, either to implement a long-running monitor for a statistic (e.g., detecting TCP timeouts), or to troubleshoot a specific problem (e.g., incast) at hand. The query is compiled into a switch program that runs on the network's programmable switches, augmented with new switch hardware primitives that we design in service of Marple. The switches stream results out to collection servers, where the operator can retrieve query results. We now briefly describe the three components of our system: the query language, the switch hardware, and the query compiler.

The Marple query language
Marple uses familiar functional constructs
like map, filter, groupby
and zip for performance monitoring. Marple provides the
abstraction of a stream that contains performance information for
every packet at every queue in the network. Programmers can focus
their attention on traffic experiencing interesting performance
using filter (e.g., packets with high queueing latencies),
aggregate information across packets in flexible ways
using groupby (e.g., compute a moving average over queueing
latency per flow), compute new stateless quantities using map
(e.g., binning a packet's timestamp into an epoch), and detect
simultaneous performance conditions using zip (e.g., when the
queue depth is large and the number of connections in the queue is high).
Switch hardware to support performance queries
A naive implementation of Marple might stream every packet's metadata from the network to a central location and run streaming queries against it. Modern scale-out data-processing systems support ~100K--1M operations per second per core, but processing every single packet (assuming a relatively large packet size of 1 KB) from a single 1 Tbit/s switch would need ~100M operations per second: 2--3 orders of magnitude more than what existing systems support.
Instead, we leverage high-speed programmable switches as first-class citizens in network monitoring, because they can programmatically manipulate multi-Tbit/s packet streams. Early filtering and flexible aggregation on switches drastically reduce the number of records per second streamed out to a standard data-processing system running on the collection server.
While programmable switches support many of Marple's stateless language
constructs that modify packet fields alone (e.g., map and
filter), they do not support aggregation of state across
packets for a large number of flows (i.e., groupby). To
support flexible aggregations over packets, we design a programmable
key-value store in hardware, where the keys represent flow identifiers and
the values represent the state computed by the aggregation function. This
key-value store must update values at the line rate of 1 packet per clock
cycle (at 1 GHz) and support millions of keys (i.e., flows).
Unfortunately, neither SRAM nor DRAM is simultaneously fast and dense
enough to meet both requirements.
We split the key-value store into a small but fast on-chip cache in SRAM and a larger but slower off-chip backing store in DRAM. Traditional caches incur variable write latencies due to cache misses; however, line-rate packet forwarding requires deterministic latency guarantees. Our design accomplishes this by never reading back a value into the cache if it has already been evicted to the backing store. Instead, it treats a cache miss as the arrival of a packet from a new flow. When a flow is evicted, we merge the evicted flow's value in the cache with the flow's old value in the backing store. Because merges occur off the critical packet processing path, the backing store can be implemented in software on a separate collection server.
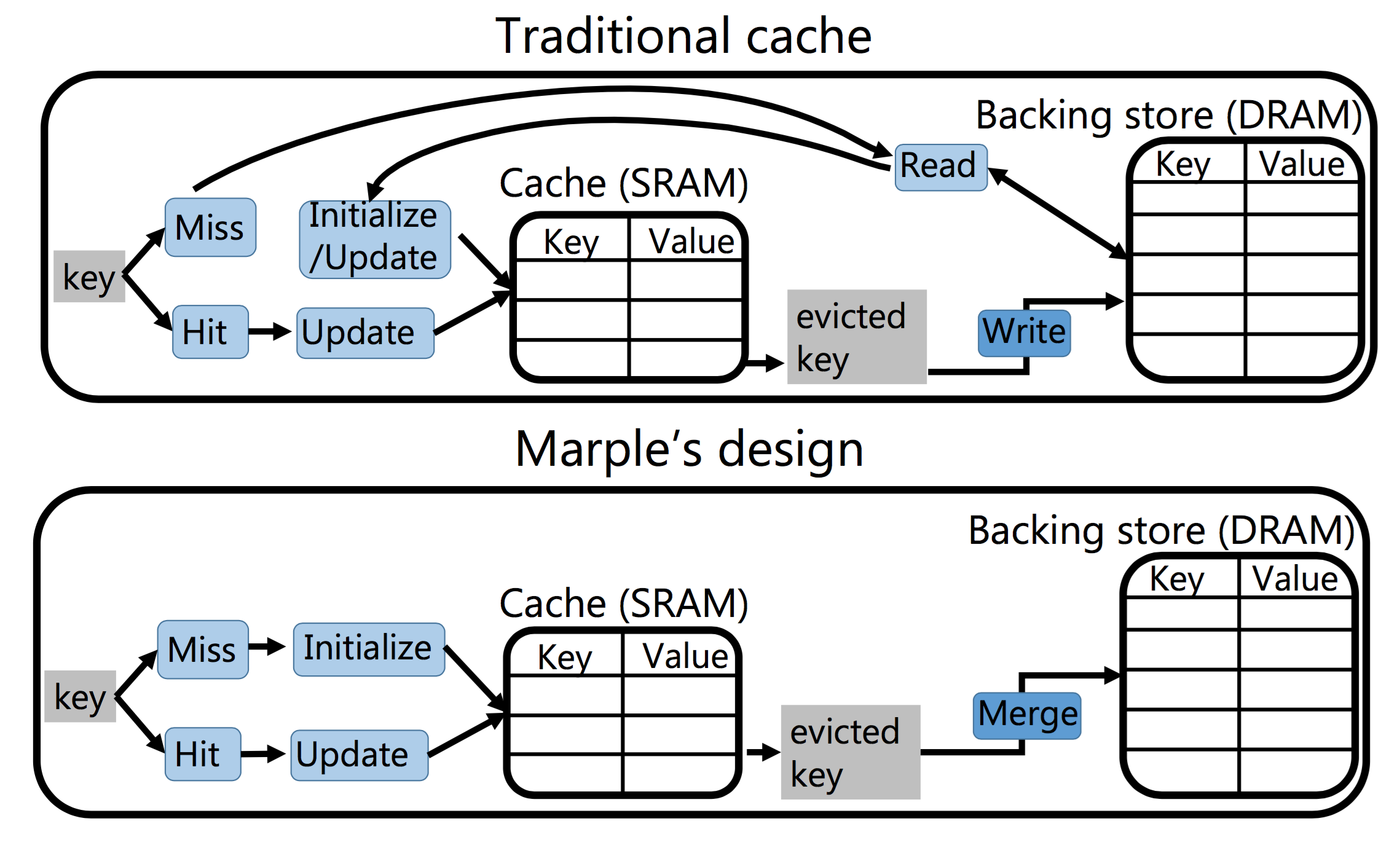
While it is not always possible to merge an aggregation function without losing accuracy, we characterize a class of affine aggregation functions, which we call linear-in-state, for which accurate merging is possible. Many useful aggregation functions are linear-in-state, e.g., counters, predicated counters (e.g., count only TCP packets that saw timeouts), exponentially weighted moving averages, and functions computed over a finite window of packets. We design a switch instruction to support linear-in-state functions, finding that it easily meets timing at 1 GHz, while occupying modest silicon area.
Query compiler
We have built a compiler that takes Marple queries and compiles them into switch configurations for two targets: (1) the P4 behavioral model, an open source programmable software switch that can be used for end-to-end evaluations of Marple on Mininet, and (2) Banzai, a simulator for high-speed programmable switch hardware that can be used to experiment with different instruction sets. The Marple compiler detects linear-in-state aggregations in input queries and successfully targets the linear-in-state switch instruction that we add to Banzai.
Marple can express a variety of useful performance monitoring examples, like detecting and localizing TCP incast and measuring the prevalence of out-of-order TCP packets. Marple queries require between 4 and 11 pipeline stages, which is modest for a 32-stage switch pipeline (e.g., such as RMT). We evaluated our key-value store's performance using trace-driven simulations. For a 64 Mbit on-chip cache, which occupies about 10% of the area of a 64 X 10-Gbit/s switching chip, we estimate that the cache eviction rate from a single top-of-rack switch can be handled by a single 8-core server running Redis. We also evaluated Marple's usability through two Mininet case studies that use Marple to troubleshoot high tail latencies and measure the distribution of flowlet sizes.
Frequently Asked Questions
- Why have a query language once you have the switch primitives?
The query language provides a way to specify the monitoring intent of the network operator. Without it, it would be challenging to program the raw capabilities of the switch primitives, similar to how it is challenging to program in assembly language. A user should think directly about what they want to measure, as opposed to how they should be collecting the necessary measurements. The latter should be the work of a compiler and run-time system. The query specification allows an operator to state complex filtering and aggregation operations on packet data at a high-level of abstraction.
- Can Marple be used to track the performance of a packet as it traverses the network?
Yes. For example, in our paper, we have a query that selects packets that have a high end-to-end latency value by summing the queueing latency for each unique packet along its trajectory through the network.
- How can Marple's key-value store process all packets, while existing technologies like NetFlow/IPFIX must rely on heavy sampling? Are the requirements for Marple on switches realistic?
Marple's key-value store relies on a split design involving a fast cache (in on-chip SRAM) and a slow backing store (in off-chip DRAM, either on the switch CPU or a separate server). The on-chip SRAM can process every single packet owing to its small access latency (~1ns). Software implemenations of NetFlow must sample heavily since they cannot operate at the switch's line rate. While hardware implementations of NetFlow can process every packet, they cannot keep a record of every flow, since the flow lookup table cannot insert new flows at line rate in the presence of hash collisions in their table. Marple solves precisely this problem with its cache design (i.e., inserting the new key on a cache miss) and merging (i.e., maintaining correctness for evicted values).
- Can Marple be used to diagnose root causes for microbursts?
-
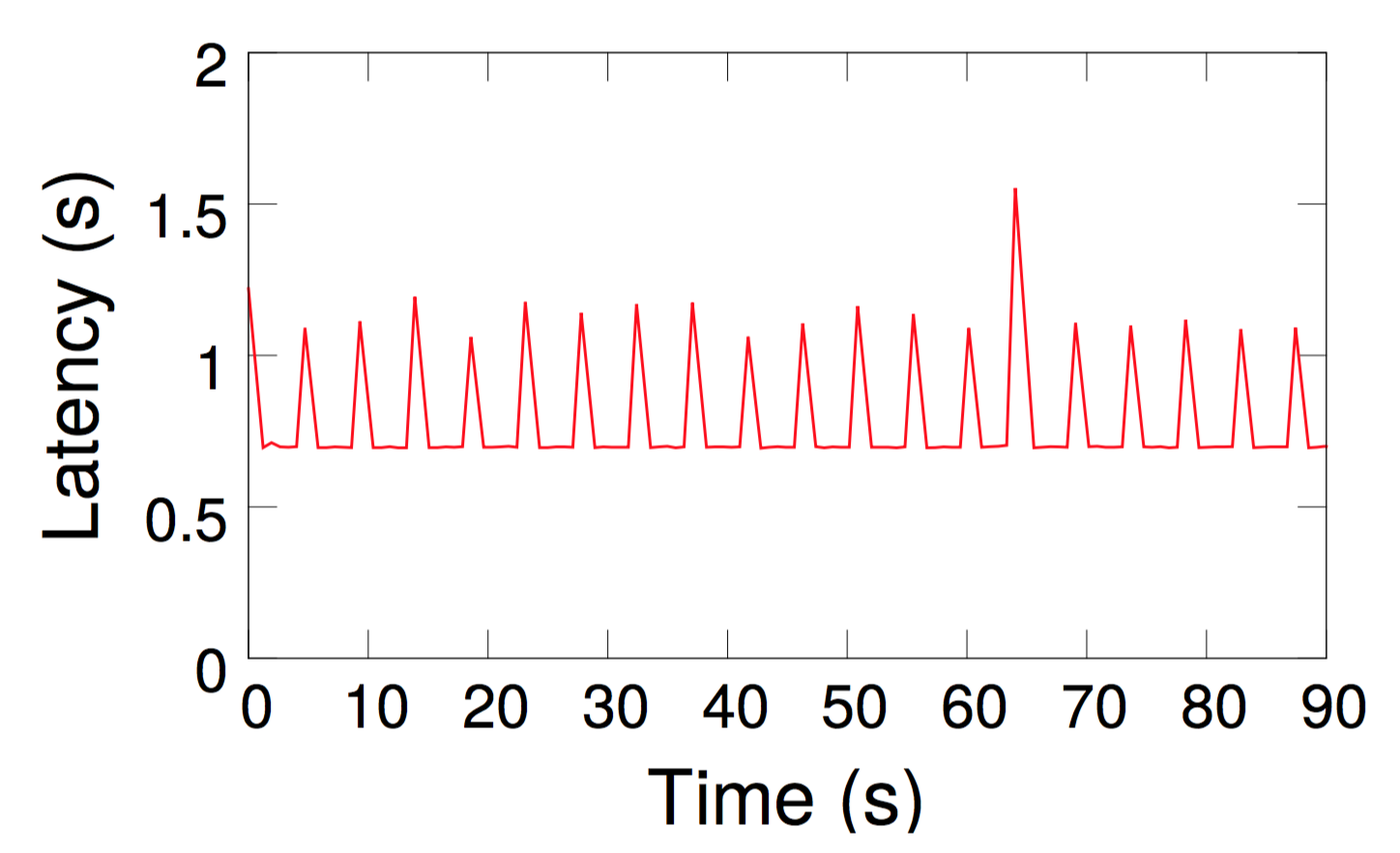
Yes. In the paper, we walk through the process of identifying a contending bursty traffic source using Marple queries running on P4 switches inside Mininet. The experiments can be replicated by following instructions from our testbed repository, but we list the main steps below. When an operator notices spikes in request latencies (e.g., see the graph below on the left ), she can first issue a query that localizes the queue that causes the overall inflation in request latencies (see the graph below on the right).
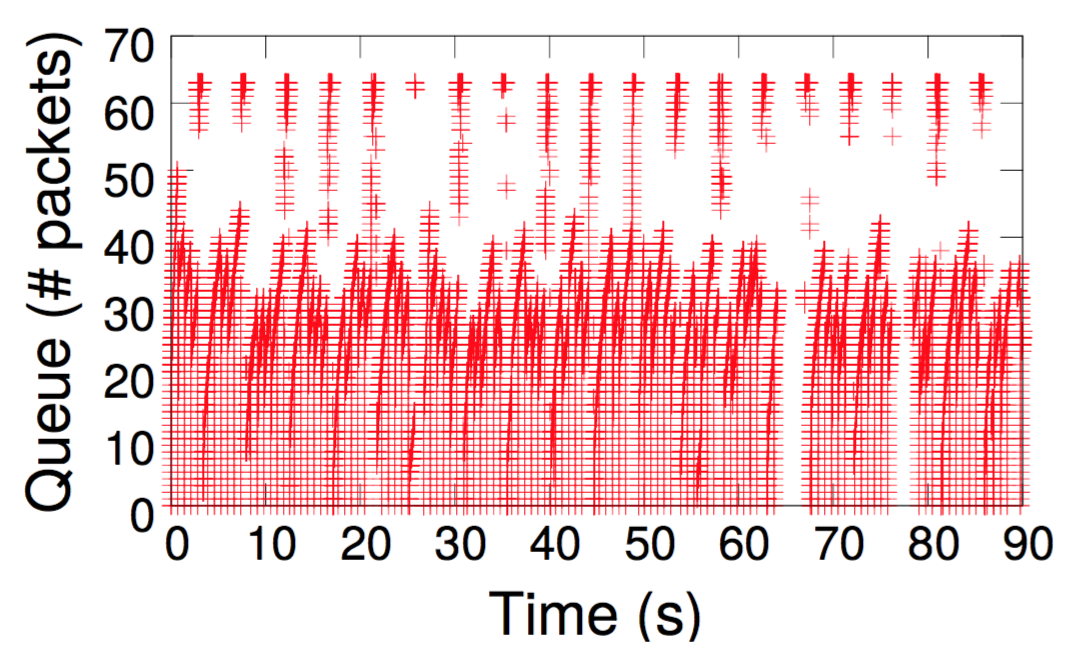
Once the queue is localized, the operator writes another query that tracks the "burstiness" of a traffic source by counting the number of distinct trains of packets separated by a minimum time interval between the trains. The query also tracks the overall time that each flow is active. The result, tabulated below from our setup, clearly shows the presence of a long-lived bursty traffic source contending at one of the network queues.
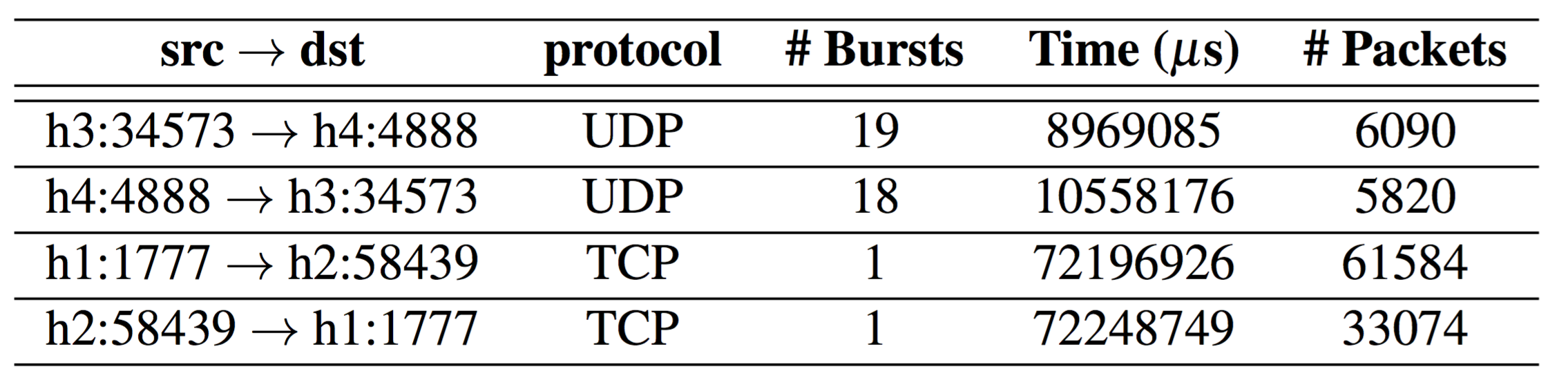
Marple's flexibility makes this diagnosis simple. Aggregating information directly on switches enables the operator to determine contending flows at the problematic queue through a customized query, without prior knowledge of those flows. By contrast, localizing the root cause of microbursts with existing monitoring approaches is challenging. Packet sampling and line-rate packet captures would miss microbursts because of heavy undersampling. Packet counters from switches would have disguised the bursty nature of the offending UDP traffic. Probing from endpoints would not be able to localize the queue with bursty contending flows, let alone identify the bursty flow.
Additionally, in the paper, we show a query that detects the "incast" (fan-in) condition on network queues.
- How is Marple different from industry proposals that provide switch performance telemetry, such as In-band Network Telemetry (INT)?
-
In-band Network Telemetry (INT) exposes queue lengths and other performance metadata from switches by piggybacking them on the packet. Marple uses INT-like performance metadata, but goes beyond INT and allows aggregations over this performance data directly on switches. Marple's on-switch data aggregation provides three advantages relative to INT. First, without aggregation, each INT endpoint needs to process per-packet data at high data rates. Second, on-switch aggregation saves the bandwidth needed to bring together per-packet data distributed over many INT endpoints. Third, on-switch aggregation can handle cases where INT packets are dropped before they reach endpoints.
- What are some things that aren't possible with the Marple query language?
Some aggregations are challenging to implement over a network-wide stream. For example, consider an EWMA over some packet field across all packets seen anywhere in the entire network, while processing packets in the order of their queue departure timestamps. Even with clock synchronization across switches, this aggregation is hard to implement because it requires us to either coordinate between switches or stream all packets to a central location.
Marple’s compiler rejects queries with aggregations that need to process multiple packets at multiple switches in order of global timestamp values. Concretely, we only allow aggregations that relax one of these three conditions, and thus either:
(1) operate independently on each switch, in which case we naturally partition queries by switch (e.g., a per-flow EWMA of queueing latencies on a particular switch), or
(2) operate independently on each packet, in which case we have the packet perform the coordination by carrying the aggregated state to the next switch on its path (e.g., a rolling average link utilization seen by the packet along its path), or
(3) are associative and commutative, in which case independent switch-local results can be combined in any order to produce a correct overall result for the network, e.g., a count of how many times packets from a flow appeared throughout the network. In this case, we rely on the programmer to annotate the aggregation function with the
assocandcommkeywords.Further, Marple is designed to only allow restricted joins of query results using the
zipoperator. Only tuples that originate from the same incoming packet can be merged together: switches never have to wait to join the results from two separate queries. We did not find a need for more general joins in the language akin to joins in streaming query languages like CQL. Streaming joins have semantics that may be quite complex, and may produce large results of size commensurate with the square of the number of packets in the network. Hence, Marple restricts the joins possible in the language to the simplerzip.
Marple is designed and built by Srinivas Narayana, Anirudh Sivaraman, Vikram Nathan, Mohammad Alizadeh, Prateesh Goyal, Venkat Arun, Vimal Jeyakumar, and Changhoon Kim. You can contact the lead author at
alephtwo@csail.mit.edu for any questions about the paper
or the software.
Accessibility