
Similarly to uHumans, we use a photo-realistic Unity-based simulator to test Kimera and its ability to reconstruct a DSG (Rosinol et al., 2021). The simulator provides the 2D semantic segmentation for Kimera. Humans are simulated using standard graphics assets, and in particular the realistic 3D models provided by the SMPL project. A ROS service enables us to spawn objects and agents into the scene on-demand. The simulator provides ground-truth poses of humans and objects, which we use for benchmarking. Using this setup, we create several large visual-inertial datasets which feature scenes with and without dynamic agents, as well as a large variety of environments (indoors and outdoors, small and large).
New scenes
- Office:
- Apartment:
- Subway:
- Neighborhood:
where xx in *_xxh.bag indicates the number of humans in the scene.

Videos
Code
Download all uHumans2 Dataset
We provide a convenient python script to download and decompress the full dataset from google drive:
- Step 1. Download: Python script to download full dataset
- Step 2 (Optional). Decompress rosbags: Python script to decompress dataset’s rosbags
If you encounter any problem, you can always download the rosbags manually by clicking the links above, and you can optionally decompress the rosbag by running rosbag decompress on it.
The reason why we decompress the rosbags is that it will make any subsequent code run faster.
Differences with uHumans (v1.0) dataset
- V1.0: is the dataset we used in our RSS2020 paper: more info here uHumans.
- V2.0: is an improved version:
- We move the reference frame for the humans from the left foot to the torso
- We reproduce the same trajectory on all runs.
- We expand our dataset with more scenes:
Specifications
- Stereo cameras (
/tesse/left_cam,/tesse/right_cam) - Depth camera (
/tesse/depth_cam) - 2D Semantic Segmentation (
/tesse/seg_cam) - IMU (
/tesse/imu) - Ground-Truth Odometry (
/tesse/odom) - 2D Lidar (
/tesse/front_lidar/scan) - TF (ground-truth odometry of robots, and agents) (
/tf) - Static TF (ground-truth poses of static objects) (
/tf_static)
Here we provide a list of the topics in a rosbag:
types: geometry_msgs/Vector3Stamped [7b324c7325e683bf02a9b14b01090ec7]
nav_msgs/Odometry [cd5e73d190d741a2f92e81eda573aca7]
rosgraph_msgs/Clock [a9c97c1d230cfc112e270351a944ee47]
sensor_msgs/CameraInfo [c9a58c1b0b154e0e6da7578cb991d214]
sensor_msgs/Image [060021388200f6f0f447d0fcd9c64743]
sensor_msgs/Imu [6a62c6daae103f4ff57a132d6f95cec2]
sensor_msgs/LaserScan [90c7ef2dc6895d81024acba2ac42f369]
tf2_msgs/TFMessage [94810edda583a504dfda3829e70d7eec]
topics: /clock 10151 msgs : rosgraph_msgs/Clock
/tesse/depth_cam/camera_info 8307 msgs : sensor_msgs/CameraInfo
/tesse/depth_cam/mono/image_raw 8307 msgs : sensor_msgs/Image
/tesse/front_lidar/scan 16962 msgs : sensor_msgs/LaserScan
/tesse/imu/clean/imu 101213 msgs : sensor_msgs/Imu
/tesse/imu/noisy/biases/accel 101150 msgs : geometry_msgs/Vector3Stamped
/tesse/imu/noisy/biases/gyro 101150 msgs : geometry_msgs/Vector3Stamped
/tesse/imu/noisy/imu 101212 msgs : sensor_msgs/Imu
/tesse/left_cam/camera_info 8307 msgs : sensor_msgs/CameraInfo
/tesse/left_cam/mono/image_raw 8307 msgs : sensor_msgs/Image
/tesse/left_cam/rgb/image_raw 8307 msgs : sensor_msgs/Image
/tesse/odom 101213 msgs : nav_msgs/Odometry
/tesse/rear_lidar/scan 16962 msgs : sensor_msgs/LaserScan
/tesse/right_cam/camera_info 8307 msgs : sensor_msgs/CameraInfo
/tesse/right_cam/mono/image_raw 8307 msgs : sensor_msgs/Image
/tesse/right_cam/rgb/image_raw 8307 msgs : sensor_msgs/Image
/tesse/seg_cam/camera_info 8307 msgs : sensor_msgs/CameraInfo
/tesse/seg_cam/rgb/image_raw 8307 msgs : sensor_msgs/Image
/tf 113606 msgs : tf2_msgs/TFMessage
/tf_static 1 msg : tf2_msgs/TFMessage
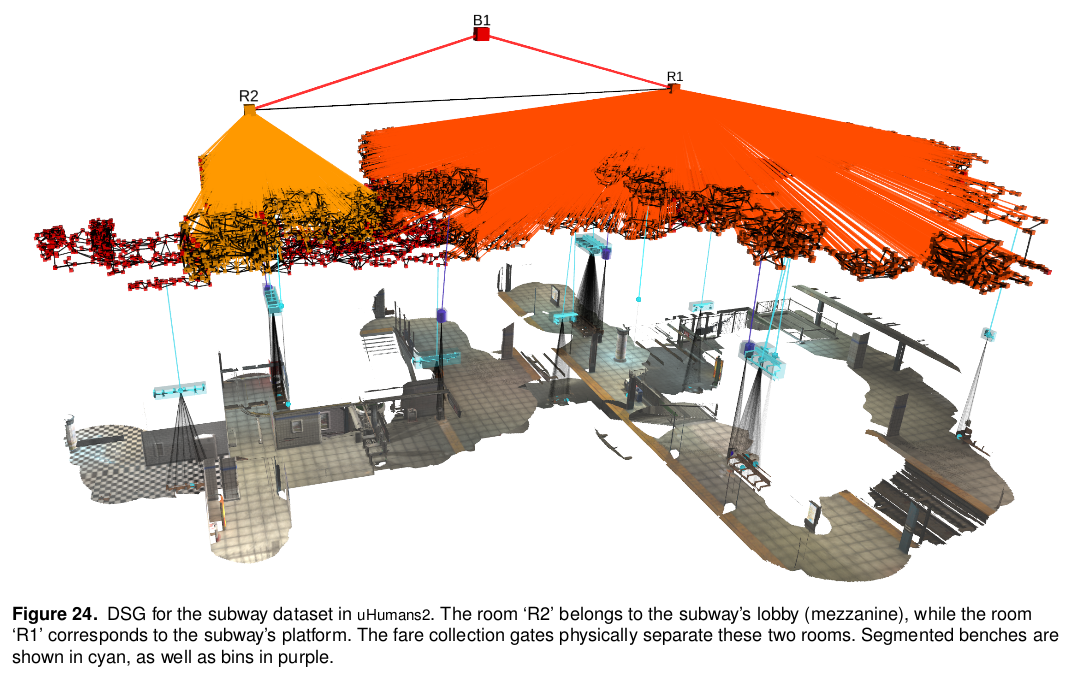
Example DSG and 3D Mesh


How can you use uHumans2?
Localization
VO/VIO/SLAM in static and dynamic scenes: estimate localization errors from your Visual (mono/stereo) inertial odometry, or SLAM system, by using the ground-truth pose information in the /tesse/odom topic.
Mapping
3D geometric and semantic reconstruction: evaluate mapping errors. We cannot provide the ground-truth 3D meshes with semantic annotations, but depending on the number of requests we may provide an automated server for submission and evaluation. Feel free to contact us: arosinol@mit.edu.
Human Pose Estimation
3D Human pose estimation: we provide the pose information of humans in the \tf topic.
Object Pose Estimation
3D Object pose estimation: we provide the pose information of objects in the \tf_static topic.
Contact Us
Feel free to reach out with comments, feedback, or feature requests at: arosinol@mit.edu.