Data quality is increasingly being recognized as an important issue [Ballou & Pazer, 1985; Huh et al., 1990; Liepins & Uppuluri, 1990; Madnick & Wang, 1992]. Data quality problems have been studied in different disciplines, either implicitly or explicitly. There are various techniques and tools from these disciplines that appear relevant to data quality management. Older techniques include the use of integrity constraints in the database area [Brodie, 1980; Morey, 1982; Svanks, 1984]. Methods from the TQM (Total Quality Management) literature include statistical sampling and continual process improvement [Imai, 1991; Juran & Gryna, 1988]. Newer techniques like process re-engineering focus on radically streamlining data processing [Hammer, 1990], and as a result improve data quality. In the field of accounting, the development of double-entry bookkeeping and other sophisticated internal control systems is aimed at maintaining good data [Bodnar, 1975; Cushing, 1974; Wand & Weber, 1989]. Thus, knowledge in the area of data validation at present is fragmented over different disciplines.
Data validation in this paper refers to the combination of one or more of the following elements: detection, measurement, correction and prevention of defects. Given our fragmented knowledge of the area, three issues concerning data validation strategies may be raised. First, how do we identify, analyze and categorize these methods in terms of their relevance, strengths and limitations in the context of data validation? Second, are there other avenues pertinent to data validation but are, as yet, relatively unexplored by current research? If there are, then a recognition of unexplored territory will motivate further research in those areas. Third, each method typically focuses on some aspect of data validation. How then do we form a coherent overall data validation strategy, consistent with a given context, by using a combination of these methods? What are the relevant issues that need to be investigated?
In this paper, we develop a framework as an initial response to these questions. Based on a model of information systems and a definition of data quality, we first formalize the concepts of internal, external and process validity. Thereafter, we develop the framework around these concepts. This framework describes and distinguishes three approaches to data validation in terms of their basic assumptions and objectives. The three approaches are referred to as internal validation, external validation and process validation. There are three benefits of this framework. First, it aids both researchers and practitioners in identifying, analyzing and categorizing various methods that may be relevant to data validation. Specifically, it will facilitate the identification and evaluation of the contribution of a particular method to the various elements of data validation. Second, this framework gives guidance to future efforts aimed at developing specific data validation methods by revealing any deficiencies in extant research. We show that process validation methods are very effective in ensuring sustained data quality, but yet there is a relative lack of well developed methods in the process validation category. There would therefore be a need for greater research effort in this area. Third, based on this framework, a catalog of data validation techniques may be developed to aid practitioners in developing a coherent overall data validation strategy. By comparing and contrasting various types of methods in this catalog, an appropriate choice of a set of complementary methods to form data validation strategy can be made. In this paper, we raise several research issues that require further investigation concerning data validation strategies that are heavily based on process validation methods. The purpose of this framework, then, is to provide a conceptual tool that facilitates the development of methods and coherent strategies for data validation, and is not meant to give a comprehensive survey or summary of existing research.
In this section, we first present a model of an information system and a definition of the term 'data quality'. Various characterizations of data quality have been made in previous work. However, these definitions of data quality either tended to be intuitive or were given in terms of data quality dimensions (Ballou & Pazer, 1985; Huh, et al., 1990; Redman, 1992). Identifying the dimensions of data quality is not the same as defining data quality. In this section, we present a definition of the concept of data quality itself, clearly explicating our assumptions and terminology. We then formalize the concepts of internal, external and process validity and show the relationships among these concepts.
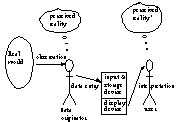
An Information System: Wand and Weber postulated that "information systems are built to provide information that otherwise would have required the effort of observing ... some reality with which we are concerned. From this point of view, an information system is a representation of some perceived reality. It is a human-created representation of a real world system as perceived by someone." [Wand & Weber, 1990]. For our purposes, an information system is taken to be synonymous with a database. Figure 1 below illustrates such a caricature of an information system. Central to our definition of data quality is the notion that an information system is supposed to eliminate the (costly) effort of direct observation of the real world. Informally, the quality of data would be judged on the 'closeness' of its representation of reality. In this model, the data production process refers to the mappings from the real world to the creation of data in the database. We will present a more formal definition of a data production process in Section 2.3.
Objects: The world/reality is made up of objects. People, numbers and bank accounts are examples of objects. For a more detailed account consistent with our definition, see [Bunge, 1974, p26]. We denote the set of all objects that make up the world as Q [Bunge, 1977, p111].
Propositions: The user's perception of the objects in the world, his perceived reality, consists of a set of propositions. These propositions have no existence apart from mental processes of the user [Bunge, 1974, p28]. An example of a proposition is "John is married to Jane".
Data: Propositions are represented by data objects which are part of some symbolic language [Bunge, 1974, p10]. Therefore a data object is a special type of object in that it represents a proposition about some other object in reality. In general, a user is not interested in the characteristics of the data object, e.g. font, size etc. Instead, the user is more concerned with the propositions represented by these data objects. We will also refer to data objects as data. Data reside in a database and the granularity of the data is not important for our analysis and will therefore be left unspecified.
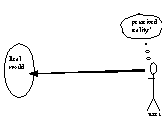
The User: We consider a user (Fig. 2) who can perfectly (no errors) and instantaneously (no delay) observe the world of interest over time and form propositions about the world. The world of interest is defined by a query or view, a formal statement of what the user would like to observe. Furthermore, we assume that this user has limitless recall capability, i.e. he can remember all the events of interest. Also, we assume that the user can instantaneously interpret the data in the information system according the rules of the symbolic language being used.
|
|
We define a predicate
where Ai Õ Q, i OE {1,...,m}, are time-varying sets of objects in which the user is interested. St is the corresponding set of all conceivable propositions that can be made at time t OE T about these objects. T is a set of time instances. Based on the laws of the domain of interest, each proposition in St can either be lawful or unlawful [Bunge, 1977, p134]. Formally, the set of laws is represented by the function L: St Æ {lawful, unlawful}. Thus St can be partitioned into the set of lawful propositions Sl,t and a set of unlawful propositions Su,t such that Sl,t » Su,t = St and Sl,t « Su,t = Æ. Informally, an unlawful proposition is an impossible one while a lawful proposition is a possible one. Each lawful proposition is either a valid (true) proposition or a false (invalid) one. Thus Sl,t can be partitioned into the set of valid propositions Sv,t and a set of invalid propositions Si,t such that Sv,t » Si,t = Sl,t and Sv,t « Si,t = Æ. The user is interested in the set Sq,t Õ Sv,t, where Sq,t constitutes the user's perceived reality at time t in Fig. 1 and Fig. 2. Sq,t is the set of propositions that corresponds to the user's query under ideal conditions of observation.
Furthermore, we define the following mappings:
Pl,t: A1¥A2¥...¥AmÆ Sl,t
Pv,t: A1¥A2¥...¥AmÆ Sv,t
Pq,t: A1¥A2¥...¥AmÆ Sq,t
where Pq,t Õ Pv,t Õ Pl,t. The mapping Pq,t: A1¥A2¥...¥AmÆSq,t corresponds the user's observation of the world (Fig. 2). We define Pq,t as a query or view. For example, Pq,t may be the mapping "is married to". In this case, the domain of the mapping is the cross product of the set Employee and the set Spouse:
Propositions may be represented by data. We therefore define the following mappings:
Il,t: Dl,t:ÆSl,t
Iv,t:Dv,t:ÆSv,t
Iq,t:Dq,tÆSq,t
where Dq,t, Dv,t and Dl,t are data sets representing the sets of propositions Sq,t, Sv,t and Sl,t. Furthermore, Iq,t Õ Iv,t Õ Il,t. These functions correspond to the symbolic language of representation used. Iq,t is a bijective function and is defined as the interpretation map. Also,
Dq,t Õ Dv,t Õ Dl,t (Eqn 1)
To eliminate the effort of direct (and costly) observation, a perfect or ideal information system is built (Fig 1). Thus, instead of directly observing the objects in reality and constructing propositions, the perfect information system enables the user to observe data objects that represent these propositions. We define the mapping
where Dq,t is a set of data delivered to the user at time t. We can think of Fq,t as the process of recording the facts about the world as data. Each data element in Dq,t may be interpreted via Iq,t by the user to form the desired set of propositions Sq,t. Thus we make the following:
Definition 1: Dq,t is defined as the quality data set.
In other words, the data delivered to the user at t in response to his query, Dq,t, are quality data, or Dq,t is said to have attained data quality. By observing this data set, the user can obtain all the knowledge he requires just as if he had observed the world directly. Conceptually speaking, to determine whether or not Dq,t is a quality data set, the user would have to compare it with direct observation of reality. Although database designers intend to build such a perfect information system, defects in design and operation will lead to an actual data set Da,t where Da,t _ Dq,t giving rise to data quality problems.
We now present three notions of validity based on our definition of an information system and data quality.
Definition 2: Da,t is internally valid iff Da,t Õ Dl,t.
Definition 3: Da,t is externally valid iff Da,t = Dq,t.
Definition 3 states that externally valid data is quality data.
Theorem 1 : If the actual data set Da,t is externally valid, then Da,t is internally valid but not vice versa.
Proof: Part (a): If Da,t is externally valid, then Da,t = Dq,t (Definition 3). But Dq,t Õ Dl,t (Eqn 1). Therefore Da,t Õ Dl,t. Thus, by Definition 2, Da,t is internally valid. Part (b): Proof by counter-example. Consider the case where the user is interested in Dq,t, a proper subset of Dv,t, i.e. Dq,t à Dl,t. Also, suppose Dl,t = Da,t. Then Da,t is internally valid by Definition 2. Since Dq,t à Dl,t and Dl,t = Da,t, therefore Dq,t à Da,t. It follows, by Definition 3, that Da,t is not externally valid.
Definition 4: The ideal data production process over the set of time instances T = {t1,t2,...,tn} is defined as the sequence of mappings DPq = · Fq,t1...Fq,tnÒ where t1<t2...<tn.
Definition 5: Let DPa = · Fa,t1...Fa,tnÒ denote the actual data production process over T. DPa is defined as process valid over T iff DPa = DPq over T.
Theorem 2: If a data production process DPa is process valid over T, then data set Da,t , delivered at t, is externally valid for all t OE T.
Proof: If DPa is process valid over T, then DPa = DPq = · Fq,t1...Fq,tn Ò (Definitions 4 and 5). Thus Da,t = Dq,t for all t OE T. Therefore, Da,t , for all t OE T, is externally valid (Definition 3).
This means that process validity sustains the continual delivery of quality data over period T.
Corollary : If a data production process DPa is process valid over T, then the data set Da,t ,delivered at t, is internally valid for all t OE T.
Proof: This follows directly from Theorem 1 and Theorem 2.
Thus, achieving process validity leads to a sustained delivery of externally valid data sets (Theorem 2). External validity leads to internal validity but not vice versa (Theorem 1). Based on the above argument, the most effective means of sustaining the delivery quality data is through a valid process.
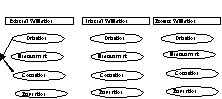
There are four elements in a data validation approach. The first element is prevention. This means not allowing bad data into the database in the first place. If this cannot be done, then the defective data already present in the database needs to be detected. Furthermore, we may want to measure the degree of defectiveness in the data set. Subsequently, we would want to correct these defects by replacing bad data with quality data.
Our conceptualization of a data production process and data quality in Section 2 suggests three approaches to data validation. They are (1) internal validation, (2) external validation and (3) process validation. Each approach is based on knowledge of particular elements of the data production process. Internal validation makes use of the knowledge of the data set Dl,t, since Dq,t Õ Dl,t. This knowledge is embedded in the production system at design time. Therefore, internal validation methods, at best, ensure internal validity of data by eliminating inconsistencies. External validation makes use of specific knowledge about the real world. In terms of our model, the user checks for the external validity of the data by comparing it against the real world and makes corrections to Da,t, the actual data set delivered at time t, without correcting the source of the defects in the production process. External validation approaches may achieve data that is externally valid, but such an approach cannot sustain the continual delivery of quality data. Achieving external validity of a data set leads to internal validity of that data, but not process validity. The process validation approach focuses on process validity by making use of knowledge of the characteristics of DPq, the series of perfect mappings from the real world to the data set. That is, the user knows some of the characteristics of the perfect data production process DPq and seeks to reduce the deviation between DPa and DPq. A valid process can sustain the continual delivery of quality data. We now give a more detailed account of the three approaches and point to examples of existing methods which are based on these approaches.
Internal validation methods attempt to ensure the internal consistency of data based on some knowledge of the characteristics of the data set Dl,t. Since Dq,t Õ Dl,t, data elements not belonging to Dl,t is eliminated from Da,t. This knowledge is embedded in the production system as an integrity constraint [Codd, 1970; Codd, 1986; Elmasri, 1989] at design time. Range checking and logical data edits are some examples of such constraints [Morey, 1982]. Internal control systems, widely used in accounting systems [Bodnar, 1975; Cushing, 1974; Wand & Weber, 1989] are further examples of internal validation methods. Unlike the external validation approach, the internal validation approach does not explicitly perform comparisons with the real world during production time.
The internal validation approach deals with several types of inconsistencies. Contradictory data is an example of an inconsistency. Users expect that the data in Dq,t should not contradict each other. For example, the same person having two different birthdates. Another form of inconsistency has to do with the form and structure of the data in the database. For example, in relational databases, a person's name should not be represented in more than one way and null values are not allowed.
Internal validation methods detect defects by checking for inconsistencies in the data. These checks may be used as a preventive measure to reduce errors and thus act to improve data quality. They can also be used to give a weak estimate of the quality of data, for example, by seeing what percentage of the data records violate these constraints [Morey, 1982]. A weakness in this approach however, is that ensuring internal validity is not sufficient to ensure external validity (Theorem 1).
The external validation approach uses the real world as a reference for validating data. In terms of our model, the user goes and directly observes the world and compares his observations against the data. Taking physical inventory, for example, is a common practice in accounting where a physical count of inventory level is taken to validate data. This method detects any discrepancies between the data and the actual inventory. The degree of the discrepancy can also be measured, and steps can be taken to correct the discrepancy. The external validation approach, however, does not focus on prevention but assumes that bad data already exists in a database.
There are however obvious limitations to excessive use of such methods. It is likely that there will be significant costs associated with external validation. Presumably, the user has invested in an information system in the first place to avoid the costs of direct observation. Instead of checking every piece of data in the database, we can estimate the quality of data by using statistical sampling techniques [Janson, 1988; Juran & Gryna, 1988; Paradice & Fuerst, 1991]. This alternative would be a less costly. However, using a small sample and comparing it against the real world allows only an estimate of the degree of defects. The sampling test itself will not allow the detection or correction of defects in the entire database. However, if the database has failed the sampling test, we could dispose of the existing data and start collecting the data all over again. Again this might be a very costly exercise. Furthermore if the source of the defects is not eliminated, there is no guarantee that the new data will be better.
Another source of weakness is related to the inability to directly observe past and current states of the real world. There may be no way to directly and perfectly observe the current state of the real world except through imperfect instruments or an information system. In some situations, it is also unlikely that we can directly and perfectly observe past states of the world. For example, if the a bank teller gives out money to a customer and recorded a incorrect but smaller amount, it is unlikely that at the end of the day, that particular entry error can be identified.
Finally, the process validation approach focuses on data processing operations. Data defects are taken to be synonymous with process defects. Validation efforts aim at the detection, measurement and correction of process defects. A process validation method to estimate data defects includes information about the data processing steps so that the user can estimate the quality of data and use the data intelligently [Wang et al., 1993a; Wang et al., 1993b; Wang & Madnick, 1990b]. Information about the data processing steps may include for example the source and intermediate sources of the data [Wang & Madnick, 1990a]. Using this additional information, referred to as quality indicators, the user can reason about the quality of data [Jang et al., 1992]. Other examples of quality indicators are data creation time and data collection method. This method, however, does nothing to prevent or correct data defects.
Correction of process defects effectively leads to prevention of future data defects. Process correction efforts stem from the observation that once a piece of defective data is in a database, it will be extremely difficult to fix [Huh et al., 1990]. There are two variants of this process correction method. The first is referred to as re-engineering or redesign [Davenport & Short, 1990; Hammer, 1990]. Such techniques involve radical streamlining of data processing operations. The second variant emphasizes continual and incremental improvements not unlike the traditional TQM approaches [Imai, 1991]. These approaches may call for a redesign of the database system, data processing steps etc. Detecting and correcting process defects promises to be the most effective means of sustaining the continual delivery of quality data (Theorem 2).
This framework has three benefits. First, it facilitates the identification, analysis and categorization of existing research and methods, which originate from a variety of disciplines, that are relevant to the various elements of data validation. An extensive analysis and categorization of existing research based on this framework is not possible in this paper due to space limitations, but such an effort will be undertaken elsewhere. Second, this framework gives guidelines for future research aimed at developing specific data validation methods. This is accomplished by pointing to existing relevant methods and ideas which can then act as a platform from which to further develop other methods. Furthermore, we suspect that a comprehensive survey of data validation techniques, based on this framework, will show that process validation methods for data production are much less developed than the other categories. A recognition of the relative lack of well-developed process validation methods will serve as motivation for further research in the area.
Third, based on this framework, a catalog of data validation methods may be developed to aid practitioners in developing a coherent data validation strategy by choosing an appropriate set of methods from this catalog. Fig. 3 illustrates a strategy employing purely external validation methods. In this strategy, each piece of data is compared with the real world to detect defects. Subsequently defective data is corrected accordingly. This strategy does not, however, prevent future data defects.
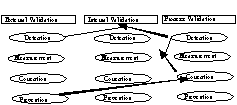
It is also possible to employ a combination of methods based on different approaches, each one focusing on the different elements of data validation. For example, we could employ statistical sampling to detect a sample of defects. The source of these defects can then be traced to a process defect which when corrected will prevent further data defects. This is illustrated in Fig. 4. The detection and correction of process defects is highly effective in preventing data defects. We identify three issues for future research in data validation strategies that are heavily process oriented. The first issue concerns the identification, definition and measurement of key characteristics of the data production process, and the relationship between these process characteristics and the dimensions of data quality. Linking data defects to process defects will provide a means of detecting process defects. The second issue concerns the development of a data production process representation that allows appropriate description and analysis of process attributes and the quality of the data output. Finally, tools for evaluating data production processes in terms of data quality output are needed to support process improvement.
Data quality is increasingly being recognized as an important issue. In this paper, we have presented a model of an information system and definition of data quality, clearly explicating our assumptions. We then formalized the concepts of internal validity, external validity and process validity. A framework which describes and distinguishes three approaches for validating data is then developed based on these concepts. The three approaches are external validation, internal validation and process validation. Methods based on these approaches typically focus on one or more elements of data validation: prevention, detection, measurement and correction of defects.
The benefits of this framework were enumerated. We further identified
several research issues that are relevant to the development of
data validation methods and strategies. In addition, we suspect
that a comprehensive survey of the extant research on data validation
based on this framework will reveal a relative lack of well-developed
process validation methods. The argument that process validation
methods would be the most effective in sustaining the continual
delivery of quality data should serve as motivation for further
research in this area.
[1] Ballou, D. P. & Pazer, H. L. (1985). Modeling Data and Process Quality in Multi-input, Multi-output Information Systems. Management Science, 31(2), 150-162.
[2] Bodnar, G. (1975). Reliability Modeling of Internal Control Systems. The Accounting Review, 50(4), 747-757.
[3] Brodie, M. L. (1980). Data Quality in Information Systems. Information and Management, (3), 245-258.
[4] Bunge, M. (1974). Semantics I: Sense and Reference. Boston: D. Reidel Publishing Company.
[5] Bunge, M. (1977). Ontology I: The Furniture of the World. Boston: D. Reidel Publishing Company.
[6] Codd, E. F. (1970). A relational model of data for large shared data banks. Communications of the ACM, 13(6), 377-387.
[7] Codd, E. F. (1986). An evaluation scheme for database management systems that are claimed to be relational. In The Second International Conference on Data Engineering , (pp. 720-729) Los Angeles, CA.
[8] Cushing, B. E. (1974). A Mathematical Approach to the Analysis and Design of Internal Control Systems. Accounting Review, 49(1), 24-41.
[9] Davenport, T. H. & Short, J. E. (1990). The New INdustrial Engineering: Information Technology and Business Process Redesign. Sloan Management Review, (Summer 1990).
[10] Elmasri, R. (1989). Fundamentals of Database Systems. Reading, Mass: The Benjamin/Cummings Publishing Co., Inc.
[11] Hammer, M. (1990). Reengineering Work: Don't Automate, Obliterate. Harvard Business Review, (Jul-Aug).
[12] Huh, Y. U., Keller, F. R., Redman, T. C., & Watkins, A. R. (1990). Data Quality. Information and Software Technology, 32(8), 559-565.
[13] Imai, M. (1991). KAIZEN: The Key To Japan's Competitive Success. McGraw Hill.
[14] Jang, Y., Kon, H. B., & Wang, R. Y. (1992). A Data Consumer-based Approach to Supporting Data Quality Judgment. Second Annual Workshop on Information Technology and Systems, (December 1992).
[15] Janson, M. (1988). Data Quality: The Achilles Heel of End-User Computing. Omega Journal of Management Science, 16(5), 491-502.
[16] Juran, J. M. & Gryna, F. M. (1988). Quality Control Handbook. New York: McGraw-Hill Book Co.
[17] Liepins, G. E. & Uppuluri, V. R. R. (Ed.). (1990). Data Quality Control: Theory and Pragmatics. New York: Marcel Dekker, Inc.
[18] Madnick, S. E. & Wang, Y. R. (1992). Introduction To The TDQM Research Program. No. TDQM-92-01). Massachusetts Intitute Of Technology.
[19] Morey, R. C. (1982). Estimating and Improving the Quality of Information in the MIS. Communications of the ACM, 25(May), 337-342.
[20] Paradice, D. B. & Fuerst, W. L. (1991). An MIS data quality methodology based on optimal error detection. Journal of Information Systems, 5(1), 48-66.
[21] Svanks, M. I. (1984). Integrity analysis: methods for automating data quality assurance. EDP Auditors Foundation, Inc., 30(10), 595-605.
[22] Wand, Y. & Weber, R. (1989). A Model of Control and Audit Procedure Change in Evolving Data Processing Systems. Accounting Review, LXIV(No. 1).
[23] Wand, Y. & Weber, R. (1990). Mario Bunge's Ontology as a Formal Foundation for Information Systems Concepts. In Studies on Mario Bunge's Treatise. Amsterdam: Rodopi.
[24] Wang, R. Y., Kon, H. B., & Madnick, S. E. (1993a). Data Quality Requirements Analysis and Modeling in Data Engineering. In Ninth International Conference In Data Engineering , Vienna, Austria.
[25] Wang, R. Y., Reddy, M. P., & Kon, H. B. (1993b). Toward Quality Data: An Attribute-Based Approach. Journal of Decision Support Systems (DSS), Special Issue on Information Technologies and Systems,.
[26] Wang, Y. R. & Madnick, S. E. (1990a). A Polygen Model for Heterogeneous Database Systems: The Source Tagging Perspective. In Proceedings of the 16th International Conference on Very Large Data bases (VLDB) , (pp. 519-538) Brisbane, Australia.
[27] Wang, Y. R. & Madnick, S. E. (1990b). A Source Tagging Theory for Heterogeneous Database Systems. In International Conference on Information Systems , (pp. 243-256) Copenhagen, Denmark.