KEY WORDS: Data Quality, Database Systems, Data Administration
Acknowledgments Work reported herein has been supported,
in part, by MIT's Total Data Quality Management (TDQM) Research
Program, MIT's International Financial Service Research Center
(IFSRC), Fujitsu Personal Systems, Inc. and Bull-HN.
Poor data quality can have a severe impact on the overall effectiveness of an organization. In order to design information systems that deliver good quality of data, the notion of data quality has to be well-understood. However, there is still no consensus on what constitutes a good set of data quality dimensions and on appropriate definitions for each dimension.
We propose an ontologically-based approach to define data quality
dimensions based on the role of an information systems as a representation
of a real-world system. The dimensions are derived from possible
failures of the representation. The analysis leads to four intrinsic
dimensions of data quality: completeness, lack of ambiguity, meaningfulness,
and correctness. We discuss the relationships of these dimensions
to those cited in the literature and briefly present some implications
of the analysis to information systems design.
KEY WORDS: Data Quality, Data Administration, Information Systems Design
Technological advances have improved organizations' capabilities to acquire, store, process, and distribute data. Yet, data stored in many organizational databases are often considered to be of poor quality. Poor data quality can have a severe impact on the overall effectiveness of an organization. A leading computer industry information service firm, the Gartner Group, indicated that (April 12, 1993), "A vital prerequisite for business process reengineering is the ability to share data. However, Gartner Group expects most business process reengineering initiatives to fail through lack of attention to data quality." A recent industry executive report (Computerworld, September 28, 1992) noted that more than 60% of the surveyed firms (500 medium size corporations with annual sales of more than $20 million) had problems with data quality. Also, the Wall Street Journal reported that (May 26, 1992), "Thanks to computers, huge databases brimming with information are at our fingertips, just waiting to be tapped. They can be mined to find sales prospects among existing customers; they can be analyzed to unearth costly corporate habits; they can be manipulated to divine future trends. Just one problem: Those huge databases may be full of junk. ... In a world where people are moving to total quality management, one of the critical areas is data."
The quality of a product depends on the process by which the product is designed and produced. Likewise, the quality of data depends on the design and production processes involved in generating the data. To design for better quality, it is necessary to first understand what quality means and how it is measured.
Data quality, as presented in the literature, is a multi-dimensional concept. Frequently mentioned dimensions are accuracy, completeness, consistency, and timeliness. The choice of these dimensions is based on intuitive understanding (e.g., [3] ), industrial experience (e.g., [12] ), empirical studies (e.g., [19] ), or literature review (e.g., [10] ). However, the literature shows that there is no general agreement on a set of data quality dimensions and their exact definitions exists.
Consider accuracy which most data quality studies include as a key dimension. Although the term accuracy has an intuitive appeal, there is no commonly accepted definition of what it means exactly. For example, Svanks [13] notes that "the components of data integrity -- accuracy, consistency, and completeness -- are not widely understood." Kriebel [10] characterizes accuracy as "the correctness of the output information." Paradice and Feurst [11] note that "calculating the error rate of stored MIS records requires determining the probability that a randomly chosen record in an MIS is correct (i.e. that it contains data which is accurate)." Ballou & Pazer [3] describe accuracy as "the recorded value is in conformity with the actual value." Thus, it appears that the term "accuracy" is viewed as equivalent to "correctness." However, using one term to define the other does not serve the purpose of clearly defining either. In short, despite the frequent use of certain terms to indicate data quality, there does not exist a rigorously defined set of data quality dimensions.
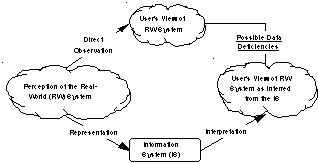
We base our approach on the fundamental notion that the role of an information system is to provide a representation of an application domain (also termed the real-world system) as perceived by the user. Representation deficiencies are defined in terms of the difference between the view of the real-world system as inferred from the information system and the view that is obtained by directly observing the real-world system. From various types of representation deficiencies, we derive a set of data quality dimensions.
Since we base data quality concepts on the role of an information system as a representation, we need to define: (1) what is directly observed in the real-world system, and (2) how an information system acts as a representation of the real-world system. "What is in the world" is the subject of ontology . Hence, we will base our formalization on ontological concepts.
We first make a distinction between the external and internal views of an information system [16] . The external view is concerned with the use and effect of an information system. It addresses the purpose and justification of the system and its deployment in the organization. In the external view, an information system is considered given, that is, a "black box" with the functionality necessary to represent the real-world system.
In contrast, the internal view addresses the construction and operation necessary to attain the required functionality, given a set of requirements which reflect the external view. System construction includes design and implementation. System operation includes activities involved in producing the data such as data capture, data entry, data maintenance, and data delivery. For simplicity, we assume perfect implementation because, for our purposes, a faulty implementation is equivalent to a faulty design with a perfect implementation. Thus, our analysis concentrates on the internal view, and is oriented towards system design and data production. This has two important implications. First, since the internal view is use-independent, it supports a set of definitions of dimensions of data quality that are comparable across applications. Hence, these dimensions can be viewed as being intrinsic to the data. Second, this view can, in principle, be used to guide the design of an information system with certain data quality objectives.
We begin by stating four assumptions. The first assumption establishes the purpose of an information system:
·Assumption 1: the representation assumptionÒ An information system is a representation of a real-world system.
The view of an information system as a representation is not new. For example, Kent [9] states that "an information system ... is a model of a small, finite subset of the real world."
The development and use of an information system involve two transformations: the representation transformation (rep for short) and the interpretation transformation (int) [15] . The representation transformation deals with creating a representation of a view of the real-world system. This includes creating the information system and populating it with data. The interpretation transformation is the use of the information system to infer a view of the represented real-world system.
Information systems users may not be those involved in defining the requirements for the information system. Hence, to assure that the interpretation transformation will able to reproduce the original view of the real-world system we introduce:
·Assumption 2: the interpretation assumptionÒ An information system is built for use by the user whose view of the real-world system is captured in the design of the system.
For the information system to function properly, both the representation and interpretation transformations need to be performed flawlessly. This is the basis for our definition of data deficiency (Figure 1):
·Definition 1Ò A data deficiency is an inconformity between the view of the real-world system that can be inferred from a representing information system and the view that can be obtained by directly observing the real-world system.
The interpretation transformation can be decomposed into two processes. First, the information system creates a perceptible representation (most commonly, but not solely, a visual display). Then, the user should be able to perform the required inference about the real-world system. (A 'user' can, in principle, be a human-being or a machine.) Clearly, the user's ability is beyond the design of a system, and therefore, beyond the scope of our model. Hence, we separate interface-related issues from our model:
·Assumption 3: the inference assumptionÒ The information system can create a perceptible representation from which the user can infer a view of the real-world system as represented in the information system.
Finally, we confine our model to system design and data production aspects by excluding issues related to use and value of the data:
·Assumption 4: the internal view assumptionÒ Issues related to the external view such as why the data are needed and how they are used are not part of the model.
This assumption does not imply that use and value are unimportant, but rather that data quality in our model is specified with respect to a given set of requirements. We assume that the requirements capture the true intentions of the users.
Since models of the world are the domain of ontology, we base our analysis on ontological constructs. The fundamental ontological concepts that we use and their application to information systems have been addressed in detail elsewhere (e.g., [5, 14]) . Here we summarize only the main concepts needed for our analysis.
The world is made of things that possess properties. A thing can be a composite - made of other things. Properties are represented as characteristics assigned to things by humans, depending on purpose and experience. Such characteristics are termed attributes. The values of the attributes at any given time comprise the state of the thing. Hence, the knowledge of a thing is captured in terms of its states. Not all combinations of values of attributes are possible. There are laws that limit the allowed states. The allowed states comprise the lawful state space. An information system is also a thing. To be a good representation of a real-world system, the lawful states of the information system should reflect the lawful states of the real-world system. We formalize these notions below.
·Postulate 1Ò Things are modeled in terms of their states and laws.
·Postulate 2Ò The real-world system is a thing, described in terms of its states and laws.
·Postulate 3Ò An information system is a thing, described in terms of its states and laws.
Usually, a system is not viewed just as a whole, but its components are also of interest, hence:
·Postulate 4Ò A system can be described as a composite made of other things.
Each of the components of a system is a thing, again modeled in terms of its states and laws. There is a connection between the states of components and the states of the whole system:
·Postulate 5Ò Let the components of a system with a state space S be {X1,...,XN} with state spaces {S1,...,SN} respectively. There exists an exhaustive and one to many mapping: S Æ S1x...xSN (every element in S has at least one counterpart in S1x...xSN).
Next we formalize the notion of an information system as a representation of a real-world system:
·Definition 2Ò An information system is said to be a representation of a real-world system if observing the state of the information system at a given time enables the inference of a state of the real-world system (at the same or another time).
Finally, we define the link between data and the ontological view of information systems:
·Postulate 6Ò The data stored in an information system at a certain time represent the state of the information system at that time.
This is consistent with the well-accepted database concepts. For example,
"The data in the database at a particular moment in time is called a database state. In a given database state.... Every time we insert or delete a record, or change the value of a data item, we change one state of the database into another state" [6] .
We begin by identifying the criteria for a real-world system to be properly represented by an information system. Based on this, we identify possible representation deficiencies that can occur during system design and data production. These deficiencies are used to define intrinsic data quality dimensions.
Let RWL denote the lawful state space of a real-world system, and ISL that of an information system representing this real-world system. Recall the representation and interpretation transformations. These transformations imply that two mappings must exist:
(1) a mapping from RWL to ISL, Rep: RWL Æ ISL
(2) a mapping from ISL back to RWL, Int: ISL Æ RWL.
For a real-world system to be properly represented, two conditions must hold (Figure 2). First, every lawful state of the real world system should be mapped to at least one lawful state of the information system (a real-world state can be mapped into multiple information system states). Second, it should be possible, in principle, to map an information system state back to the "correct" real-world state.
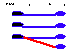
We formalize this in the following definition:
·Definition 3Ò A real-world system is said to be properly represented if: (1) there exists an exhaustive mapping, Rep: RWL Æ ISL, and (2) no two states in RWL are mapped into the same state in ISL (i.e.the inverse mapping is a function).
Our analysis of data deficiencies is based on deviations from the conditions of Definition 3. We distinguish deviations due to system design flaws from those due to data production (system operation) flaws.
Definition 3 treats states in RWL and ISL as a whole, similar to considering the total data in a database at a particular moment as the database state. In practice, it is common to decompose the model of the real-world, i.e., view it as an aggregate of things and to decompose the information system to represent these components. By Postulate 5, RWL can be viewed as a subset of the outer product of the components' state spaces. Correspondingly, a database state can be viewed at the global or at the component (e.g. entity, or object) level. Unless explicitly mentioned, our analysis applies to both the global and the decomposed views. However, it will be shown that the decomposition of RWL and ISL can generate special cases of representation deficiencies.
Based on our proper representation definition, we identify three generic categories of design deficiencies: incomplete representation, ambiguous representation, and meaningless states.
For an information system to properly represent a real-world system, the mapping from RWL to ISL must be exhaustive (i.e., each of the states in RWL is mapped to ISL). If the mapping is not exhaustive, there will be lawful states of the real-world system that cannot be represented by the information system (Figure 3). We term this incompleteness. An example is a customer information system design which does not allow a non-U.S. address (a lawful state of the real-world system) to be recorded.
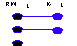
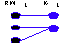
For a proper representation no two states of the real-world should be mapped into the same state of the information system. If several states in RWL are mapped into the same state in ISL, there is insufficient information to infer which state in RWL is represented. We term this situation ambiguity (Figure 4). A typical case of ambiguity is when there is insufficient number of digits to represent some states of the real-world system. This is usually viewed as a precision problem. However, we consider it a special case of ambiguity which is more general as it relates to any type of data, not just to numeric values. For example, a system design may allow only for one phone number, without indicating whether it is the office or home phone.
It is not required that the mapping from RWL to ISL be exhaustive with respect to ISL. However, when this situation exists, there are lawful states in ISL that can not be mapped back to a state in RWL (Figure 5). Such states are termed meaningless states. An information system design with meaningless states can still represent a real-world system properly. However, it is not a good design as it allows, in principle, meaningless data. For such meaningless data to materialize, some operational failure will have to occur.
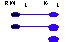
We have identified two main design deficiencies, corresponding to the two conditons of proper representation (Definition 3): 1) the representation mapping (from RWL to ISL) is not exhaustive, and 2) the represntation mapping is many-to-one. We also identified a potential deficiency when the mapping does not exhaust ISL. Consider the fourth case: the representation mapping is one-to many. Whether the existence of several information system states that match a real world state may cause a problem, is a cognitive issue, not subject to designer's decisions. We therefore do not consider this a design defficiency.
At operation time, a state in RWL might be mapped to a wrong state in ISL. We refer to this as garbling, and distinguish between two cases: (1) if there exist meaningless states of the information system, the mapping might be to a meaningless state, and (2) the mapping might be to a meaningful, but incorrect information system state. In the first case the user will not be able to map back to a real-world state (Figure 6). In the second case the user will be able to infer back, but to an incorrect state of the real-world (Figure 7). Typically, garbling occurs due to incorrect human actions during system operation (e.g., erroneous data entry, or failure to record changes in the real-world).
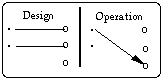
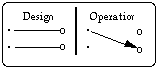
Figure 6: Garbling (map to a meaningless state) Figure 7: Garbling (map to a wrong state)
Note, our analysis of design and operational flaws does not encompass the case where the user perceives a "wrong" state of the real world (either by error or due to malicious intent). This is because the information system is only required to enable mapping into perceived states, not "real" states.
When an information system is decomposed, it is possible that each component of the system will act as a proper representation of a component of the real-world system, yet the joint representation be deficient. We identify three cases: (1) the joint state of the information system represents a lawful but incorrect state of the real world (incorrect data), (2) the joint state of the information system does not represent a lawful state of the real-world (meaningless data), and (3) the information system state corresponds to two or more states of the real-world (ambiguity).
We use an example to demonstrate how these deficiencies can occur. Consider a risk management information system used by an investment firm that operates in several stock markets. The system is made of components (subsystems) each reflecting the firm's position in a market.
First, suppose that transactions occurred in two markets, but that one transaction was not reported by the time the other transaction was reported. Then both components would be in lawful states, and the joint state would be lawful but incorrect (garbling to a wrong state).
Second, assume there exists a supervisory mechanism which prevents traders in all circumstances from exceeding a maximum allowed exposure. Suppose that a trader invested in one market and sold in another without exceeding the total allowed exposure. Assume also that the component for the market in which the trader purchased was updated before the component for the market in which the trader sold. Then, there will be a period in which the global information system state might show a total balance higher than the allowed exposure, namely, an unlawful state of the trading system (garbling to a meaningless state).
Third, assume exchange rates for various countries are stored in all the subsystems. If the exchange rate for a certain currency is updated in one subsystem but not in another subsystem, then different values can be inferred (ambiguity).
The above analysis provides some insight into how these three cases of deficiencies might happen. In particular, it demonstrates that because of the timing of updating the state of an information system, decomposition-related inconsistencies may occur even when all components operates properly.
Based on the analysis of the representation mapping from states of the real-world system to states of the information system (RWL ÆISL) we identified four potential representation deficiencies. As a consequence of these defficiencies, information system states can be incomplete, ambiguous, meaningless, or incorrect. According to our assumptions, data represent the information system state (Postulate 6). Accordingly, we propose a set of four intrinsic data quality dimensions as shown in Table 1.
| D.Q. Dimension | Nature of Associated Deficiency | Source of Deficiency |
| completeness | Improper representation: missing IS states | Design failure (Figure 3) |
| lack of unambiguity | Improper representation: multiple RW states mapped to the same IS state | Design failure (Figure 4) |
| meaningfulness | Meaningless IS state and | Design failure (Figure 5) and |
| Garbling (map to a meaningless state) | Operation failure (Figure 6) | |
| correctness | Garbling (map to a wrong state) | Operation failure (Figure 7) |
We first summarize (Table 2) the most often cited data quality dimensions based on a comprehensive literature review [18] .
| Dimension | # cited | Dimension | # cited | Dimension | # cited |
| Accuracy | 25 | Format | 4 | Comparability | 2 |
| Reliability | 22 | Interpretability | 4 | Conciseness | 2 |
| Timeliness | 19 | Content | 3 | Freedom from Bias | 2 |
| Relevance | 16 | Efficiency | 3 | Informativeness | 2 |
| Completeness | 15 | Importance | 3 | Level of Detail | 2 |
| Currency | 9 | Sufficiency | 3 | Quantitativeness | 2 |
| Consistency | 8 | Usableness | 3 | Scope | 2 |
| Flexibility | 5 | Usefulness | 3 | Understandability | 2 |
| Precision | 5 | Clarity | 2 |
These dimensions can be categorized based on the definitions of internal and external views (Table 3). Since we excluded interface issues from our model, we include them in the external view. Table 3 also indicates whether a dimension is related to the data or to the system. Note, timeliness appears as related to both the internal and external views. Furthermore, timeliness and reliability appear to be both data and system-related. This will be explained below.
| Dimensions | |
| Data Related
accuracy, reliability, timeliness, completeness, currency, consistency, precision System Related reliability |
| Data Related
timeliness, relevance, content, importance, sufficiency, usableness, usefulness, clarity,conciseness, freedom from bias, informativeness, level of detail, quantitativeness, scope, interpretability, understandability System Related timeliness,flexibility, format, efficiency, |
We now analyze those data quality dimensions from the literature that we identified as being in the internal view.
As indicated in the introduction, there is no exact definition for accuracy. In terms of our model we propose that inaccuracy implies the state of the information system represents a real-world state different from the one that should have been represented. Therefore, inaccuracy can be interpreted as a result of garbled mapping into a wrong state of the information system.
Moreover, inaccuracy can be related to other data deficiencies identified in our model. First, ambiguity can lead to inference of the wrong state of the real-world system. Lack of precision is a case which is typically viewed as inaccuracy, but is ambiguity in our model. Second, incompleteness may cause choice of a wrong information system state during data production, resulting in incorrectness.
Note that inaccuracy refers to cases where it is possible to infer a valid state of the real world, but not the correct one. This is different from the case of meaningless states where no valid state of the real world can be inferred.
Reliability has been linked to probability of preventing errors or failures [8] , to consistency and dependability of the output information [10] , and to how well data rank on accepted characteristics [1] . In addition, reliability has been interpreted as a measure of agreement between expectations and capability [4] , and as how data conform with user requirements or reality [1] . It is clear that there is no generally accepted notion of reliability and that it might be related either to characteristics of the data or of the system. However, one interpretation - that reliability indicates whether the data can be counted on to convey the right information, can be viewed as correctness of data in our analysis.
Timeliness has been defined in terms of whether the data are out of date [3] , the response time of the system [7] , and availability of output on time [10] . A closely related concept is currency which is interpreted as the time a data item was stored [17], or how up to date a datum is [12] .
Timeliness is affected by two factors. First, how fast the information system state is updated after the real-world system changes (currency). Second, the rate of change of the real-world system (volatility). While the first aspect is affected by design and operation of the information system, the second is not subject to any design decision.
In our model, timelines refers to the delay between a change of the real-world state and the resulting modification of the information system state. Lack of timeliness may lead to a state of the information system that reflects a past state of the real world. Whether this matters or not, depends on the use of the data and is therefore in the external view. However, there is one effect of timeliness which can lead to data deficiencies independent of the use of the data, and is in the designer's domain. As our analysis of decomposition shows, wrong states, meaningless states, or ambiguous states may occur when the components operate properly, but are not updated at the same time.
Generally, the literature views a set of data as complete if all necessary values are included: "A set of data is complete with respect to a given purpose if the set contains all the relevant data and all mandatory attributes should be non-null" [12] . Also, "All values for a certain variable are recorded" [3] .
In our analysis, completeness is the ability of an information system to represent every meaningful state of the represented real world system. Thus, it is not tied to data-related concepts such as attributes, variables, or values. A state-based definition to completeness provides a more general view than a definition based on data concepts. In particular, it applies to data combinations rather than just to null values . Also, it eneables data items to be mandatory depending on the values of other data items.
In the literature, consistency refers to several aspects of data. In particular, to values of data: "the data value is the same in all cases" [3] ; to the representation of data: "entity types and attributes should have the same basic structure whenever possible (structural consistency)" [12] ; and to physical representation of data: "representation consistency refers to whether physical instances of data are in accord with their formats" [12] .
Details of internal representation or physical appearance of data are not part of our model. Hence, we only relate consistency to the values of data. Clearly, a data value can only be expected to be the same for the same situation. In terms of our model, different values can only occur if there is more than one state of the information system matching a state of the real system. In this sense, inconsistency would mean that the representation mapping is one to many. As indicated above, in our analysis this is not considered a deficiency.
We identified four intrinsic dimensions of data quality. Accordingly, we identify four generic types of data problems that can be observed in using an information system (Table 4): loss of information, insufficient information (ambiguity), meaningless data and incorrect data.
| Completeness | Certain RW states cannot be represented. | Loss of information about the application domain |
| Lack of ambiguity | A certain IS state can be mapped back into several RW states | Insufficient information: the data can be interpreted in more than one way |
| Meaningfulness | It is not possible to map the IS state back to a meaningful RW state | It is not possible to interpret the data in a meaningful way |
| Correctness | The IS state may be mapped back into a meaningful state, but the wrong one | The data derived from the IS do not conform to those used to create these data |
The generic data quality dimensions were derived by analyzing possible failures of the representation transformation: (RWL ÆISL). Based on this analysis, we can identify the types of design actions that can be used to avoid or correct these problems (Table 5).
| Loss of information | Missing lawful states of the information system | Modify ISL to allow for missing cases |
| Insufficient information
(ambiguous data) | Several states of the real world mapped into same state of information system | Change the mapping RWL ÆISL
This may require adding states to ISL |
| Meaningless Data | 1) There are information system states that do not match real-world, and 2) Garbling | Reduce ISL to include only meaningful states
This can be done by adding integrity constraints |
| Incorrect data | Garbling | Design to reduce garbling
This might be done by adding some controls |
The first two deficiencies - loss of information and insufficient information (ambiguous data) - require modifications to the lawful state space of the information system or to the mapping into this space. Such decisions are, in principle, under designer's control. In contrast, meaningless and incorrect data result from operational failures (usually due to human actions). However, meaningless data can only occur when there exist meaningless states of the information system. The designer can reduce such states through the application of information system controls such as integrity constraints [4].
The situation is more complicated for incorrect data, as they result from incorrect mapping into meaningless information system states. However, automated mechanisms may still be used to reduce this problem. Assume the state space of the information system was increased by adding a large number of meaningless states. Then the probability that incorrect operation will result in a meaningless state rather than a meaningful state would increase. Meaningless states can be controlled by integrity constraints. Thus, some garbling might be prevented by artificially increasing the possible state space of the information system and adding controls. This approach is usually implemented by increasing the possible state space of the the information system without increasing the lawful state space. Specific examples are the addition of a check digit to identification codes, and the use of control totals for transaction batches.
Despite extensive discussion in the literature, there is no consensus on what constitutes a good set of data quality dimensions and on an appropriate definition for each dimension. Even a relatively "obvious" dimension, such as accuracy, does not have a well established definition.
We propose that data deficiencies reflect inconformity between two views of the real-world: the view obtained by direct observation and the view inferred from a representing information system. In doing so, we differentiate the external view, concerning the use and effect of an information system, from the internal view dealing with the construction and operation of the system. Since the internal view does not relate to the specific use of the data, it supports the notion of intrinsic (i.e. use-independent) data quality dimension.
The analysis based on the internal view generated four intrinsic dimensions: completeness, lack of unambiguity, meaningfulness, and correctness. A review of data quality dimensions discussed in the literature shows that many often-cited dimensions cannot be affected by design decisions. Those that can, do not always map well into specific design and operational deficiencies. We believe this may confound the development of design guidelines for attaining data quality objectives.
In contrast, the proposed state mapping approach suggests a set
of well-defined data quality dimensions that can be mapped into
design guidelines. The dimensions defined do not depend on the
type of data, and are applicable to numeric and non-numeric values.
Although not pursued in this article, the use of state-related
concepts can also provide clues into attaching quantitative measures
to data quality. Beyond these potential advantages, we believe
that a rigorously-defined set of data quality dimensions has a
value in itself, in providing a common set of terms, and thus
supporting the development of a cumulative body of work in the
data quality area.
Acknowledgments This work was supported in part by grants from The Natural Sciences and Engineering Research Council of Canada, MIT's Total Data Quality Management (TDQM) Research Program, MIT's International Financial Service Research Center (IFSRC), Fujitsu Personal Systems, Inc. and Bull-HN.
[1] Agmon, N. and N. Ahituv. "Assessing Data Reliability in an Information Systems." Journal of Management Information Systems. 4(2), Fall 1987, pp. 34-44.
[2] Angeles, P. A. , Dictionary of Philosophy, Harper Perennial, New York, N.Y., 1981.
[3] Ballou, D. P. and H. L. Pazer. "Modeling Data and Process Quality in Multi-input, Multi-output Information Systems." Management Science, 31 (2), February 1985, pp. 150-162.
[4] Brodie, M. L. "Data Quality in Information Systems." Information and Management. 3, 198, pp. 245-258, 1980.
[5] Bunge, M., Ontology I: The Furniture of the World. D. Reidel Publishing Company. Boston, 1977.
[6] Elmasri, R. and S. Navathe. Fundamentals of Database Systems. The Benjamin/Cummings Publishing Co., Inc. Reading, MA, 1994.
[7] Halloran, D., S. Manchester, J. Moriarty, R. Riley, J. Rohrman and T. Skramstad. "Systems Development Quality Control." MIS Quarterly. 2(4), December 1978, pp. 1-12.
[8] Hansen, J. V. "Audit Considerations in Distributed Processing Systems." Communications of the ACM. 26 (5), August 1983, pp. 562-9.
[9] Kent, W., Data and Reality. North Holland. New York, 1978.
[10] Kriebel, C. H. "Evaluating the Quality of Information Systems." Chapter 2 in: Szysperski and Grochla ed. Design and Implementation of Computer Based Information Systems, 1979 Sijthtoff & Noordhoff. Germantown.
[11] Paradice, D. B. and W. L. Fuerst. "An MIS data quality methodology based on optimal error detection." Journal of Information Systems. 1 (1), Spring 1991, pp. 48-66.
[12] Redman, T. C., Data Quality: Management and Technology. Bantam Books. New York, 1992.
[13] Svanks, M. I. "Integrity analysis: methods for automating data quality assurance." EDP Auditors Foundation, Inc. 30 (10), December 1984, pp. 595-605.
[14] Wand, Y. and R. Weber. "An Ontological Model of an Information System." IEEE Transactions of Software Engineering. 16 (11), November 1990, pp. 1282-1292.
[15] Wand, Y. and R. Weber. "On the Ontological Expressiveness of Information Systems Analysis and Design Grammar." Journal of Information systems. 3( 3), 1993, pp. 217-237.
[16] Wand, Y. and R. Weber. "On the Deep Structure of Information Systems," Working Paper, Faculty of Commerce, The University of British Columbia, and the Department of Commerce, The University of Queensland, May 1994.
[17] Wang, R. Y., M. P. Reddy and H. B. Kon. "Toward Quality Data: An Attribute-based Approach." To appear in the Journal of Decision Support Systems (DSS), 1994.
[18] Wang, R. Y., V. C. Storey and C. Firth. "Data Quality Research: A Framework, Survey, and Analysis." Submitted to Computing Surveys for publication, 1993.
[19] Zmud, R. "Concepts, Theories and Techniques:
An Empirical Investigation of the Dimensionality of the Concept
of Information." Decision Sciences. 9 (2), April
1978, pp. 187-195.