Acknowledgments: Work
reported herein has been supported, in part, by MIT's Total Data
Quality Management (TDQM) Research Program, MIT's International
Financial Services Research Center (IFSRC), Fujitsu Personal Systems,
Inc., Bull-HN, Advanced Research Projects Agency and USAF/Rome
Laboratory under USAF Contract, F30602-93-C-0160, and the Naval
Command, Control and Ocean Surveillance Center under the Tactical
Image Exploitation (TIX) and TActical Decision Making Under Stress
(TADMUS) research programs.
|
|
|
ABSTRACT: During Desert Storm combat operations, it was clearly highlighted that tactical decisions in strike and amphibious warfare rely upon timely and accurate information on the location and condition of enemy targets. However, the U. S. tactical databases stored order-of-battle information and land-based targeting information that were accurate only to within about one mile and as old as 24 hours. To deliver higher quality information, it would be useful to dynamically re-configure a system in such a way that its information output can be customized to meet the user's requirements in an optimal manner.
In this paper, we present such a system, called the Quality Tactical Image Exploitation (QTIX) System, which is being developed as part of the U.S. Navy's primary afloat command and control system. We show how target information can be optimally determined given quality constraints such as image currency and resolution, quality tradeoffs such as that between accuracy and timeliness, and other requirements. In particular, we show how the concept of a dominant quality curve can be exploited to allow the user to select, from thousands of images and scores of image recognition algorithms, the image/algorithm pair that will produce the best target information. Although this research is presented in the context of the QTIX system, it can also be applied to many other situations.
Poor data quality can severely hamper the effectiveness of organizations [Liepens, Garfinkel, & Kunnathur, 1982; Morey, 1982; Laudon, 1986; Oman & Ayers, 1988; Liepins & Uppuluri, 1990; Redman, 1992; Strong, 1992; Strong & Miller, 1994] . During Desert Storm combat operations, it was clearly highlighted that tactical decisions in strike and amphibious warfare rely upon timely and accurate information on the location and condition of enemy targets. However, the U. S. tactical databases stored order-of-battle information and land-based targeting information that were accurate only to within about one mile and as old as 24 hours [Mazarr, Snider, & Blackwell, 1993] . To deliver higher quality information, it would be useful to dynamically re-configure a system in such a way that its information output can be customized to meet the user's requirements in an optimal manner.
In this paper, we present such a system, called the Quality Tactical Image Exploitation (QTIX) System, which is being developed as part of the U.S. Navy's primary afloat command and control system. We show how target information can be optimally determined given quality constraints such as image currency and resolution, quality tradeoffs such as that between accuracy and timeliness, and other requirements. In particular, we show how the concept of a dominant quality curve can be exploited to allow the user to select, from thousands of images and scores of image recognition algorithms, the image/algorithm pair that will produce the best target information. Although this research is presented in the context of the QTIX system, it can also be applied to many other situations.
There is a large body of literature dealing with tradeoffs among multiple decision variables; see, for example, Keeney & Raiffa [1976] . However, little research has been conducted to address issues directly related to tradeoffs between data quality dimensions such and accuracy and timeliness. There are a few exceptions. Jang, Kon, & Wang [1992] proposed a first order data quality calculus to select dominant quality attributes when multiple quality attributes are involved. Ballou & Pazer [1994] analyzed how information systems can be designed to optimize the accuracy-timeliness tradeoff through utilization function and operations research method. Building upon the concept of dominant preference [Keeney & Raiffa, 1976; Jang, Kon, & Wang, 1992] , data quality tradeoff function [Keeney & Raiffa, 1976; Ballou & Pazer, 1985] , and flexible manufacturing systems [Draper-Lab, 1984] , we develop and formalize the concept of a dominant quality curve for data, which is then applied to allow the user to interact with the QTIX system dynamically to determine the optimal information output.
This paper is organized as follows: Section 2 is an overview of the QTIX system. Section 3 is a mathematical treatment of the dominant quality curve. Concluding remarks are presented in Section 4.
Quality, context, and content are three primary aspects of data in the QTIX system. We focus on the quality aspect in this paper. Accuracy and timeliness are two important dimensions of information quality. They are crucial in assisting the user of information to develop sound plans and make sound decisions. Following Ballou & Pazer [1985] , accuracy is referred to, in QTIX, as the degree to which a target can be correctly identified, and timeliness the degree to which data are obtained early enough to be useful in decision making. The longer it takes QTIX to process an image, the less timely it is to the user.
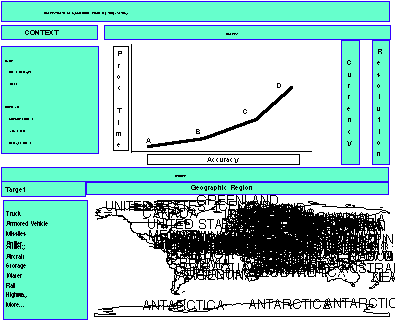
The QTIX user interface provides pull-down menus, zoom-in function, and slide-bar for users to specify the target information context, content, and quality needs. As shown in Figure 1, the context section allows for the specification of the user type (e.g., image analyst, striker planner, pilot, or all-source analyst) and purpose of the query (e.g., damage assessment, strike plan, or image analysis). The content section specifies the target type (e.g., missiles) and the area of interest (e.g., Iraq). The zoom-in function allows the user to specify, at the appropriate level of granularity, the upper left and the lower right latitude and longitude of a rectangle bounding the geographic region of interest.
Note that although conceptually intuitive and practically useful, it is not always easy to differentiate quality, context, and content. In developing the QTIX system, we interacted with the user community to derive quality, context, and content requirements. From the user's perspective, some of the quality requirements are the degree of accuracy and timeliness of the target information; some of the context requirements are the purpose of the target information, the type of user who will use the target information; and the type of target (e.g., scud missiles) is a content requirement.
Quality requirements such as currency, resolution, accuracy, and timeliness are specified through slide bars. The user may specify minimum currency for the raw images upon which the target information is produced. For example, if a user wishes to locate a mobile SCUD missile launcher, then a currency of less than two hours for the raw images may be necessary; whereas if the user needs imagery on a building, then raw images which are one day or even one year old may suffice.
Similarly, a user may use the slide bar for resolution to specify the minimum resolution requirement. For example, if a user is trying to find tanks, then a resolution of 6 ft2/pixel may be necessary. Whereas, if a user is planning a strike path to a runway, then pixels of 30 ft2 might be sufficient.
Based on the context, currency, resolution, target type, image analysis routines, and raw images, a dominant quality curve is dynamically constructed by QTIX and presented to the user. The dominant quality curve allows the user to see graphically the tradeoff between accuracy and timeliness. Each of the segments (A-B , B-C, and C-D in Figure 1) indicates a segment of optimal processing time for the corresponding level of accuracy.
QTIX makes effective use of the contextual information. For example, suppose that an enemy runway was attacked, and strike planners need to assess whether sufficient damage has been done in order to determine if another bombing run is necessary. Under this circumstance, images must not be older than the amount of time elapsed since the bombing run -- thus currency must be high. Furthermore, extremely high resolution imagery is necessary so that camouflets can be distinguished from actual bomb craters on the runway. To meet these quality constraints, QTIX automatically sets currency and resolution slide bars with high level scales whenever Assess Damage is the context. Other context-dependent interface capabilities include the customization of the target menu-tree based on the type of user and purpose.
The QTIX system can be divided into the input, processing, and output components, as shown in Figure 2. In addition to input from the user interface, the input component contains three databases. The first database is a collection of image analysis routines for image warping, histogram normalization, filtering, feature extraction, and classification. They are provided by system developers.
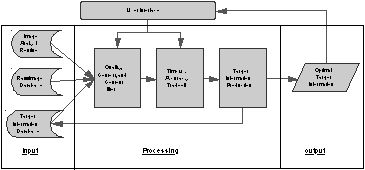
The second database contains raw images such as radar, electro-optical, and infrared images of areas of interest across the world. They are categorized according to the geographic region of coverage, their pixel resolution, and their date of capture.
The third database contains instances of target information that have been produced from previous users' requests. They are also catalogued according to the geographic region of coverage, their pixel resolution, and their production date. Each target information instance is analogous to an off-the-shelf information product, which can be reused without incurring additional processing time.
The processing component contains a set of filters, each is a process that selects a subset of the input to be the output, which in turn feeds the next filter, eventually reducing the input to a subset of image analysis routines and a corresponding image. These routines are applied to process the image and produce an optimal target information for the user. This optimal target information is then presented to the user and stored in the target information database for future use.
For exposition purposes, suppose that a pilot who is developing a strike plan chooses the target type to be SCUD missile and the area of interest to be Southern Iraq. For this mission, only images that have been taken within the last 4 hours are pertinent since the SCUD missile is a mobile target. Using this information, QTIX will produce a dominant quality curve which will be used by the pilot to determine the tradeoff between accuracy and the amount of processing time allowed for producing the target information.
There are a number of automated target recognition (ATR) algorithms available for finding SCUD missiles in images. Each SCUD ATR algorithm operates on image data of a specific type (or types) and resolution (or range of resolutions). There may be as many as 50 SCUD ATR algorithms and 10,000 images available in the area of interest. The challenge is to associate the available algorithms with the available images to find the image/algorithm pair that will produce the best target information.
There are six filters used in the QTIX system to make the number of images and ATR algorithms manageable, and allow for the selection of the best image/algorithm pair from the possible combinations. These are the area of interest filter, currency filter, resolution filter, the processing time and accuracy filters, and the ATR algorithm filter. The first three filters are used to select only those images which are pertinent to the mission. The last filter is used to select pertinent ATR algorithms and the processing time and accuracy filters are used to select the optimal image/algorithm pair using the dominant quality curve based on the users requirements.
The processing time and accuracy filters provide an interactive way for the user to select an image/algorithm pair based on their time or accuracy requirements. The mechanism used in this tradeoff is the dominant quality curve. The dominant quality curve is made up of segments of image/algorithm quality curves. Each image/algorithm quality curve encapsulates the tradeoff between processing time and accuracy level for the algorithm given the image data. When all of the available image/algorithm quality curves are put together, it is not likely that one curve will give the best time/accuracy tradeoff for all processing times or accuracies. Therefore, the dominant quality curve takes the image/algorithm quality curve that dominates for all accuracies and processing times. By selecting a specific processing time, the accuracy that can be achieved in that time can be easily found using the dominant quality curve. Since the dominant quality curve is made up of image/algorithm quality curves, selection of a processing time or accuracy also determines the image/algorithm pair used in processing. In the case where an off-the-shelf target information instance has the optimal time-accuracy tradeoff, this instance will be returned to the pilot, without incurring large amounts of image processing time.
The dominant quality curve is a very effective technique because it enables the user, by setting different currency or resolution values, to explore different kinds of image analysis routines that can be applied to produce target information -- a capability that does not exist in current systems. In addition, it allows the user to revise plans. For example, knowing that the degree of accuracy of the target information will increase from 80% to 98%, a commander may decide to postpone the flight mission by two hours so a different production method can be applied to produce target information with 98% accuracy.
We have described the QTIX system. The next section is a mathematical treatment of the dominant quality curve, which establishes a foundation for further analysis and design of QTIX.
We first present the notation required for the mathematical analysis, and then formalize the concept of a dominant quality curve.
As a convention, we use capital letters to denote a set and small letters for an element of a set, a variable, or a function.
a accuracy (e.g.
0.8 where 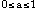 )
)
c the currency of an image (e.g. 1 hour old)
d The dominant quality curve
i an image (e.g. a digital image of Iraq)
l a location of interest (e.g. Iraq)
m a manufacturing configuration
p a production method or process (e.g. a neural network classifier to locate scud missiles in an image)
r the resolution of an image (e.g. 4 ft2/pixel which has a higher resolution than 9 ft2/pixel)
t a tradeoff function
t a target of interest (e.g. scud missile)
Viewing quality of information in the light of what is known about producing high-quality manufactured goods can be very useful [Wang, Storey, & Firth, 1993] . Adapting the concept from the manufacturing literature, we define a production method as a process (including a sequence of related image analysis routines) that can be applied to an image and produce certain target information. Further, we define the space of manufacturing configurations as all the allowable combinations of production methods and images that can be used to produce target information. A production method, however, can only be applied to an image with a resolution that the production method is designed to process.
Let P denote the set of production methods and I the set of images available to the QTIX system. Since each production method can be applied to a range of resolutions, let rlb(p) and rub(p) be functions that map a production method p to its lower and upper bound of resolution. Let r(i) be a function that maps image i to its resolution r.
Let M denote all the legitimate manufacturing configurations in the system, which is the set of combinations of production methods P and images I that shares some resolution r, i.e.,
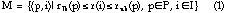
Let 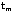 denote the tradeoff function
for manufacturing configuration m, then the set
of tradeoff functions T which is used to formulate
the dominant quality curve can be denoted as:
denote the tradeoff function
for manufacturing configuration m, then the set
of tradeoff functions T which is used to formulate
the dominant quality curve can be denoted as:
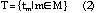
The dominant quality curve can then be formulated as:
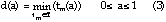
where 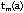 denote the time required
for manufacturing configuration to achieve the accuracy level
a. Equation (3) states that given T, a minimum
processing time can be determined for each value of a
between 0 and 1 (100% accurate) [Ballou & Pazer, 1985] .
denote the time required
for manufacturing configuration to achieve the accuracy level
a. Equation (3) states that given T, a minimum
processing time can be determined for each value of a
between 0 and 1 (100% accurate) [Ballou & Pazer, 1985] .
The number of manufacturing configurations in M
is filtered by target type, resolution, currency, and location.
Let t(p)
be a function that maps process p to target type
t.
Let c(i) and be a function that maps image i
to its currency c and l(i) to location
l. Let 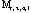 denote the set of
combinations of production methods and images that meet the following
constraints,
denote the set of
combinations of production methods and images that meet the following
constraints,
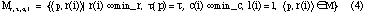
where min_r and min_c
denote the required minimum level of resolution and currency.
The set of tradeoff functions 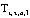 associated
with
associated
with 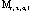 is then defined as:
is then defined as:
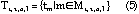
The corresponding dominant quality curve is:
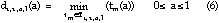
In Equation (6), if a dominant quality curve exists,
then at least one tradeoff function must exist, i.e., 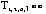 .
It is also easy to see from Equation (5) that given a set of
resolution, currency, location, and target type values, a set
of tradeoff functions is defined. This set, in turn, defines
the shape of a dominant quality curve.
.
It is also easy to see from Equation (5) that given a set of
resolution, currency, location, and target type values, a set
of tradeoff functions is defined. This set, in turn, defines
the shape of a dominant quality curve.
It is less obvious, however, to note that a variation in the resolution, currency, location, or target type value does not necessarily change the composition of the image or production-method set. Furthermore, a change in the composition of the image or production-method set does not necessarily alter the shape of the dominant curve. In other words, as a user moves the slide bars, the dominant quality curve may or may not change its shape, depending on whether different composition of images and production methods are selected, and whether that a different composition affects the shape of the dominant quality curve. We summarize these observations in the following lemma.
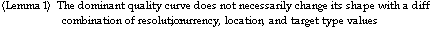
Incorporating quality information explicitly in the development of information systems can be surprisingly useful. In this research, we investigated how image production methods can be associated with quality information in such a way that users could be equipped with the capabilities to select the quality of the target information they need before it is produced. Toward this goal, we developed the concept of a dominant quality curve, which is a set of time-accuracy tradeoffs, computed based on the eligible production methods given a combination of image resolution, currency, location, and target type. The dominant quality curve is shown to be effective for users such as pilots and commanders in making their tactical decisions.
The mathematical treatment of the dominant quality curve helps to establish a foundation for designers to further understand QTIX and improve its performance. For example, a variation in the resolution, currency, location, or target type value would require QTIX to repeat the steps for filtering and producing a dominant quality curve. In an application environment with millions of images and thousands of production methods, repeating these steps may result in poor response time. Under these circumstances, it would be useful to develop techniques that will allow for the reduction of the search space of manufacturing configurations in each step, and thereby optimize the response time. We hypothesize that it would be useful to organize image analysis routines into different stages, much like an assembly line in a manufacturing setting. This is referred to as space sub-setting in flexible information manufacturing. We are actively pursuing research in this area.
A fundamental assumption that underlies this research is the availability of quality attribute values. For example, a point in a dominant quality curve may reflect the degree of accuracy that can be accomplished by a neural network image resolution algorithm within half an hour. In order to make these quality attribute values available at run time, all the relevant quality attributes [Wang & Madnick, 1990; Wang, Kon, & Madnick, 1993] must first be designed into QTIX, and values collected and stored. In some cases, the values may be trivially collected, such as the resolution of an image. In other cases, the task could be formidable. For example, it may not be easy to estimate the degree of accuracy of target information produced by a neural network in 45 minutes, given a radar image taken in a cloudy day. Estimating the quality attribute values for crucial production methods is another research direction that is being pursued.
The research presented in the paper is a first step
toward the design and development of flexible information systems
that treats processes (e.g., image resolution algorithms) analogous
to that of machine tools, and data (e.g., images) to that of raw
input materials, in a manufacturing setting. By tagging these
processes and data with quality attribute values (e.g., degree
of accuracy and timeliness) and computing the corresponding quality
level of the information output dynamically, the system may deliver
the information output that would best conform with the user's
information quality requirements.
[1] Ballou, D. P. & Pazer, H. L. (1985). Modeling Data and Process Quality in Multi-input, Multi-output Information Systems. Management Science, 31(2), 150-162.
[2] Ballou, D. P. & Pazer, H. L. (1994). Designing Information Systems to Optimize the Accuracy-Timeliness Tradeoff. To appear in Information Systems Research (ISR).
[3] Draper-Lab, C. S. (1984). Flexible Manufacturing Systems Handbook. Park Ridge, New Jersey, USA: Noyes Publications.
[4] Jang, Y., Kon, H. B., & Wang, R. Y. (1992). A Data Consumer-Based Approach to Data Quality Judgment. V. S. &. A. Whinston (Ed.), In the Second Annual Workshop on Information Technologies and Systems (WITS-92), (pp. 179-188) Dallas, Texas.
[5] Keeney, R. L. & Raiffa, H. (1976). Decisions with Multiple Objectives: Preferences and Value Tradeoffs. New York: John Wiley & Son.
[6] Laudon, K. C. (1986). Data Quality and Due Process in Large Interorganizational Record Systems. Communications of the ACM, 29(1), 4-11.
[7] Liepens, G. E., Garfinkel, R. S., & Kunnathur, A. S. (1982). Error localization for erroneous data: A survey. TIMS/Studies in the Management Science, 19, 205-219.
[8] Liepins, G. E. & Uppuluri, V. R. R. (Ed.). (1990). Data Quality Control: Theory and Pragmatics. New York: Marcel Dekker, Inc.
[9] Mazarr, M. J., Snider, D. M., & Blackwell, J. (1993). Desert Storm: the Gulf War and what we learned. Washington, D.C.: Published in cooperation with the Center for Strategic and International Studies.
[10] Morey, R. C. (1982). Estimating and Improving the Quality of Information in the MIS. Communications of the ACM, 25(5), 337-342.
[11] Oman, R. C. & Ayers, T. B. (1988). Improving Data Quality. Journal of Systems Management, 39(5), 31-35.
[12] Redman, T. C. (1992). Data Quality: Management and Technology. New York: Bantam Books.
[13] Strong, D. M. (1992). Decision Support for Exception Handling and Quality Control in Office Operations. Decision Support Systems, 9, 217-227.
[14] Strong, D. M. & Miller, S. M. (1994). Exceptions and Exception Handling in Computerized Information Processes. To appear in the ACM Transactions on Information Systems.
[15] Wang, R. Y., Kon, H. B., & Madnick, S. E. (1993). Data Quality Requirements Analysis and Modeling. In the Proceedings of the 9th International Conference on Data Engineering, (pp. 670-677) Vienna: IEEE Computer Society Press.
[16] Wang, R. Y., Storey, V. C., & Firth, C. (1993). Data Quality Research: A Framework, Survey, and Analysis. In Data Quality: A Critical Issue in the 1990's and Beyond. (pp. Orlando, Florida: Data Quality Panel of the third Workshop on Information Technologies and Systems (WITS-93).
[17] Wang, Y. R. & Madnick, S. E. (1990). A Source
Tagging Theory for Heterogeneous Database Systems. In International
Conference on Information Systems, (pp. 243-256) Copenhagen,
Denmark.