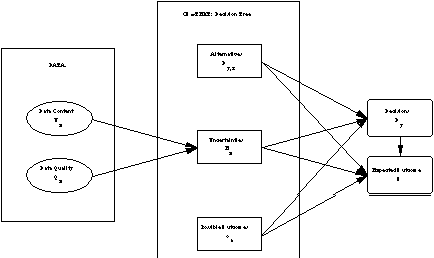
 Figure
3.1 The relation of data context, content, and quality.
Figure
3.1 The relation of data context, content, and quality.
Acknowledgments: Work reported herein has been supported,
in part, by MIT's Total Data Quality Management (TDQM) Research
Program, MIT's International Financial Services Research Center
(IFSRC), Fujitsu Personal Systems, Inc., Bull-HN, Advanced Research
Projects Agency and USAF/Rome Laboratory under USAF Contract,
F30602-93-C-0160, and the Naval Command, Control and Ocean Surveillance
Center under the Tactical Image Exploitation (TIX) and TActical
Decision Making Under Stress (TADMUS) research programs.
The purpose of this research is to develop and demonstrate a model to compute the value of data qualities in a given decision scenario.
The motivation for developing this valuation model is twofold. By comparing the relative values of various data qualities, the analyst can determine which qualities, if any, should be improved in a given system. Furthermore, this analysis can be useful in determining the price that should be paid to make such improvements.
The approach taken toward developing this model is based on the premise that the value of data is a function of its content , context, and quality. Data of a given content only has meaning on the backdrop of a context in which it is used. It is reasonable to expect that data of a better quality is more valuable than data of a worse quality. This study shows how data quality can be valued for a given data content and context.
This document is organized into a discussion of the background, theory, application, and evaluation of a data quality valuation model. Chapter 2 outlines the relevant background literature and illustrates the contribution of this study. Chapter 3 develops a theoretical model to compute the impact of data quality on decision choices and expected outcomes. In Chapter 4, this model is used to illustrate the value of data quality in the decision of the USS Vincennes to shoot down an unknown aircraft in 1988. Chapter 5 concludes the discussion with a summary of the model and its application, as well as an evaluation of its usefulness.
Before data quality can be valued, it must first be defined. Consideration of research to date reveals a wide variety of definitions and even bases for definitions.
Most studies support the notion that high quality data should conform to user requirements [9] The satisfaction of information system users with the information they receive is a reasonable interpretation of this definition. However, this definition cannot be used to analyze or design information systems unless it is operationalized.
Focusing on expressed user perceptions and opinions is one way to operationalize data quality. [5, 11]measure data quality on scales of "perceived usefulness" and "perceived ease of use." Included in such scales are such items as "makes job easier" and "clear and understandable." Other scales are developed in terms of specific technical characteristics of data such as accuracy and timeliness. However, these terms are either left undefined [3] or defined intuitively [1]
This user perception based approach has significant advantages and disadvantages. Perhaps the most significant advantage is the direct focus on user requirements. It takes into account the context in which the data is used. Indeed, it is often the case that users understand, and can express their needs. Some are even able to set aside their personal biases, distinguish objective needs from personal desires, and distinguish the effects due to the quality of data from those of information systems themselves. Among the disadvantages of this approach is that in many cases at least one of these conditions is not satisfied. Furthermore, it is often not possible to tell whether or not, in a particular case, these conditions are satisfied.
Other studies are less sensitive to confounding effects of user, system, and organizational context since they focus more on the data product than the relation of the product to the context [2, 8, 12]. For example, accuracy is defined as "a measure of agreement with an identified source" [8] Completeness is defined as "all values for a certain variable are recorded" [2]. A problem is that these definitions are often intuitively derived and therefore lack theoretical basis. The result is that they are difficult to apply in the general case. More important, it is not clear to which cases or types of cases these definitions are applicable to. [14] take an empirical approach and use factor analysis on surveys across many types of users to ground data quality in terms of user needs without bias toward a particular context. Such studies are useful for exploring and relating the possible dimensions and notions of data quality. However, this basis for analysis still lacks an important theoretical component.
[10] brings data quality research full circle in the sense that it once again grounds data in terms of its context. An important difference is that unlike earlier studies, data qualities are defined in terms of data production processes in an objective model.
The study documented here is similarly an objective and context sensitive model of data quality. The specific contribution of this work, however, is to relate data quality to its effects rather than its causes.
A basic premise of this analysis is that
the value of a unit of data content in reference to a given context
depends on the quality of the data. In this model, data context
is represented in the form of decision trees. Data content, Ux,
concerning an uncertain event, Ex, is shown to be
relevant to the extent that it affects probability estimates of
uncertain events, and therefore can impact optimal decisions,
Dy, and / or the ultimate expected outcome, O,
of the decision scenario (see figure 3.1). Finally, for a given
context and unit of content, the impact of the quality, Qx,
of a unit of data on decisions and expected outcome is shown.
Figure
3.1 The relation of data context, content, and quality.Data value is, at least in part, a function of the context in which it is used. This model of data quality valuation considers explicitly and objectively the interaction between context and data using decision tree analysis. This is not to say that all contexts can or should be modeled as decision trees -- simply that many contexts may be modeled as such. Those methods which do fit the model can be analyzed with the methods discussed here. The need and method for context modeling is discussed below.
Valuation of data requires consideration of the context in which it will be used. This is because context provides background for interpreting and applying data. Consider, for example, a unit of data such as the statement, "it will rain tomorrow afternoon." If the data is presented in a contextual vacuum, then it has no value. If there is no one or nothing to interpret or apply the data, then it does not impact the context, and can be argued not to have value. If, however, the data can be shown to have even an infinitesimal effect on a situation, then the value of the data is at least infinitesimal to the situation. Perhaps someone needs the data to decide whether or not to bring an umbrella to work in the morning. For this person and situation the data is of value.
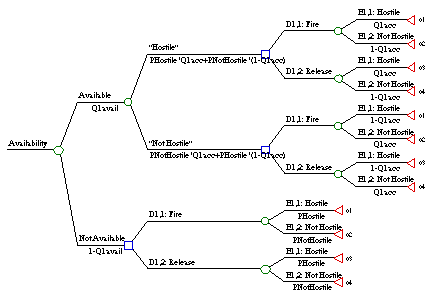
Context can be modeled by a decision tree when the relevant aspects of the context can be captured through the interrelation of decision alternatives under uncertain events where possible outcomes depend on the particular choices made by the decision maker and events of nature.
There are positive and negative aspects of this model for data context. Not all contexts fit this model. However, a significant class of contexts does fit this model. Furthermore, decision trees can specify unambiguously how data concerning uncertainties can be used. After context is properly modeled, decision analysis can be used to compute the precise effect of data on decisions and expected outcome.
An example context decision tree is shown
in figure 3.2. In the example, a decision, D1,
with alternatives D1,1 and D1,2 must
be made under uncertain event E1 with possibilities
E1,1 and E1,2. P(E1,1)
and P(E1,2) are the decision maker's estimates of
the probabilities of events E1,1 and E1,2
respectively. Possible outcomes o1, o2,
and o3 can occur depending on which decisions and
events occur.

The following two sections show how data content and quality can impact the decision maker's estimates of the probabilities P(E1,1) and P(E1,2), and thereby influence the expected outcome of the decision.
In this model only data content units relating to uncertain event nodes in a decision tree are considered. This data is used by the decision maker to set the probabilities of uncertain events in the decision tree. Without any data concerning the events of the world, these probabilities are completely unknown and the likelihood of each alternative would likely be assumed to be random. Data helps to improve these probability estimates.
In this model, data content unit, Ux,
provides information to help the decision maker improve probability
estimates about uncertain event, Ex. Ux
is relevant to Ex if it supports such an improvement
(see figure 3.3).

By affecting probability estimates of uncertain events, data content can affect decision choices and expected outcomes. The maximum value which data content can add is the "Expected Value of Perfect Information" as specified in [4]. This maximum value pertains to a given context and assumes data quality is perfect. The following section shows how data quality can affect expected outcome.
In this model, the quality, Qx,
of a single unit of data, Ux, is composed of data
availability and data accuracy. Availability, (Qx,avail),
is the probability that data is available when it is needed.
Accuracy, (Qx,acc), represents the probability that
the data is correct.
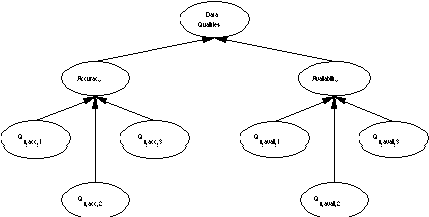
This expression is not intended to capture every data quality possible. Indeed, [14] lists 117 different data qualities. However, it will be useful in evaluating the value of these particular data qualities given that all others are held constant.
Furthermore, as will be shown below, these data uncertainties are in turn composed of uncertainties of data quality factors: Qx, avail, 1...n and Qx, acc,1...n as in figure 3.4. It is important to consider each of these sources of availability and accuracy uncertainty explicitly. This will improve the estimates of data uncertainty [4] and help the analyst to direct resources toward the proper aspect of quality if improvements are found to be necessary. It is possible that a given application might need to customize the components of the accuracy or availability qualities.
Alternate decompositions are acceptable if the data quality factors (1) completely capture the uncertainty of the higher level quality and (2) are independent of one another.
If these conditions are satisfied, then
the data qualities can be computed in terms of the factors as
follows:
The accuracy of a data unit, Ux,
refers to its correctness in predicting an uncertain event.
Accuracy of data is modeled as an uncertain event (see figure
3.5). There is a chance the data will predict any event in the
realm of possibility. Assume, for simplicity, only two alternatives
of event E1 are possible, E1,1 and
E1,2. Therefore, the data can only "say E1,1"
or "say E1,2." The chance that it will
"say E1,1" is the chance that it will
correctly predict E1,1 and the chance that it will
incorrectly predict E1,1. Similarly, the data will
"say E1,2" when it correctly predicts
E1,2 or incorrectly predicts it. Thus, the respective
data event probabilities are:
Accuracy of data for event E1
, is the probability that event E1,1 will occur
given that the data says it will: Q1,acc=P(E1,1|"data
says E1,1"). Similarly, the probability of event
E1,2 given the data says it will occur is Q1,acc=P(E1,2|"data
says E1,2"). This is the accuracy of data unit U1.
Notice that in this case P(E1,1|"data says E1,1")
= P(E1,2|"data says E1,2"). Although this need
not necessarily be the case, it is assumed so here for simplicity.
As shown in figure 3.4, accuracy can be affected by a host of different factors. For example, we could assign Qx,acc,1 = source accuracy, Qx,acc,2= source credibility, and Qx,acc,3= data clarity.
Source accuracy, Qx,acc,sa , refers to the probability that a source of data can provide correct data to the user. Consider that a radar sensor can correctly classify airplanes as either friendly or enemy 90 percent of the time. The source accuracy of data provided by this sensor is 90 percent. In making decisions under uncertainty, consideration of the ability of a source to provide accurate data is an important starting point for an assessment of data accuracy.
Given that a unit of data is source accurate, its ultimate accuracy may also be affected by its clarity, Qx,acc,clar . This affects its assimilation by the user. If, for example, the presentation of the data to the user is ambiguous, its effective accuracy will be degraded.
Credibility, Qx,acc,cred , of data refers to the user's perception that an information system will choose to provide accurate data. This quality captures the belief of the user in the intent of the source separate from the ability of the source.
Overall expected accuracy of a data unit in this context is computed as follows:
Just as with overall expected availability, accuracy estimates may often turn out to be lower than when estimated intuitively.
These factors are independent, but are not necessarily complete for a given scenario. Application of this model to an actual decision scenario would require customization of accuracy factors to the particular case at hand.
The ultimate availability of a unit of data can also be a function of several factors. For example, source availability, recognizability, and completeness can all affect ultimate data availability. Availability of data can be modeled in a decision tree as an event node with two branches -- one representing the chance of data availability and the other representing non-availability. On the branch of the available data, is the decision tree as if perfect information were available. On the other branch, is the decision tree as it appears when no information is available.
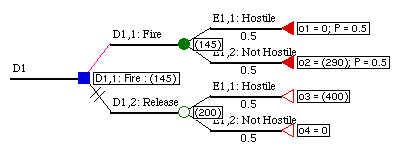
Figure 3.6 shows the effect of data availability
uncertainty on our running example. Data availability is modeled
as uncertain event, Qx,avail. Qx,avail
is the probability that the data will be available. 1-Qx,avail
is the probability that it will not be available. If the data
is available, then the expected outcome is improved -- as long
as the data is somewhat accurate. If, on the other hand, the
data is not available, then the decision must be made without
its benefit.
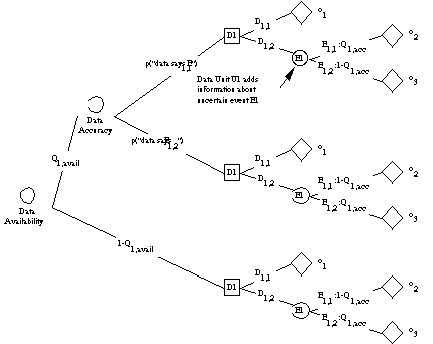 Figure
3.6 This diagram shows the effect of data availability on a sample
data context represented by a decision tree.
Figure
3.6 This diagram shows the effect of data availability on a sample
data context represented by a decision tree.Source availability, Qx,avail, sa , is the probability that a unit of data can be produced by its source. Data source availability is often assumed to be reliable, although sometimes this can be a significant source of uncertainty. It is important to consider whether or not this is a relevant uncertainty for any given decision analysis. Consider the case of a military commander who must decide whether or not to shoot at an unknown incoming target. Perfect information would be visual confirmation of the target at a safe distance. This information would certainly be available if intercept planes were in the area of the target. Availability would decrease if the planes were farther away because they would be less likely to intercept the target. Knowing this relation, a commander could decide whether deploying more intercept planes for reconnaissance would be worthwhile.
Recognizability, Qx,avail, rec , of data is the probability that a data user will be able to assimilate it. Like source availability, this uncertainty is often not considered or underestimated. For example, if the data is in written form, is it in a language the reader can understand? Is a message written large enough for the user to understand? Is a message part of a sea of other messages so that the user cannot in effect recognize it as usable?
Although a data unit is produced and recognizable, it may not be complete. A data unit must be complete enough to refine or verify the probability estimate of an uncertain event. In this model, completeness, Qx,avail,com , is the probability that a message will be complete when the user receives it.
Thus, according to this model, the chance that a data unit is available is:
One of the benefits of factoring availability into its components is to help the user estimate this conjunctive probability -- something which is difficult to do intuitively [4]
The value of data qualities and their factors
can be computed for a given unit of data and a given context by
changing the quality or factor to be valued, and monitoring the
corresponding change in expected outcome. A change in a data
quality factor () can change data qualities (), thereby changing
overall quality. This change in data quality will likely trigger
a change in optimal decisions and / expected outcome for the decision
context. This causal relationship is shown in figure 3.7.
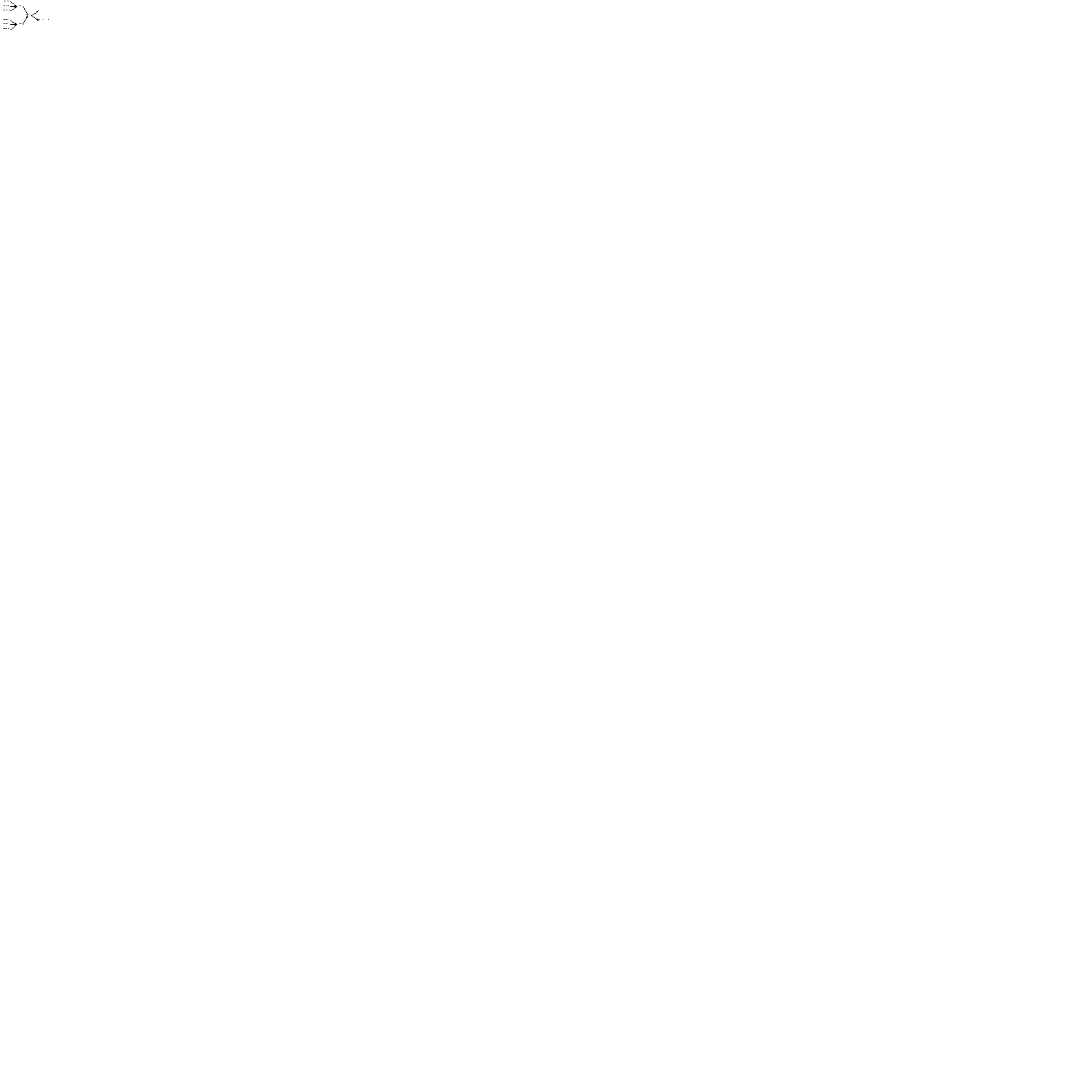
To find the value of a change in a data
quality or data quality factor, we must first establish a baseline
for comparison. This is done by setting all data qualities to
their nominal values and computing the optimal decisions and expected
value of the context tree. The optimal decision choice for each
decision in the tree in figure 3.6 is the largest of each of its
alternatives. The expected outcome for the context in figure
3.6 is:
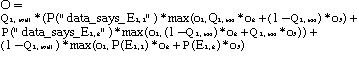
Notice that this expected outcome is a function of accuracy and availability of data unit U1. Changing either can have a significant impact on expected outcome.
This method of data quality valuation will be further demonstrated in the following section.
In order to demonstrate the application of the data quality valuation model, it is tested on a sample problem. First, the decision context is established and represented in a decision tree. Next, data content which can help the decision is outlined. Then, the effect of data quality on the decision is modeled. Last, changes in data quality are valued. It must be emphasized that this analysis is in no way intended to pass judgment on the decisions made in the sample problem. In addition, the representation of the problem is vastly simplified for illustration and is not intended to be a complete and accurate representation.
The sample problem chosen is based on the
case of the USS Vincennes shooting of an Iranian Airbus in 1988
[6, 7, 13]. A commercial aircraft departing Bandar Abbas airfield
on 3 July 1988 was identified by the USS Vincennes crew as a hostile
F-14 and destroyed with a missile. The important context from
the decision maker's standpoint was the decision of whether or
not to fire, the real world event of the incoming aircraft being
hostile or not hostile, and the likely outcomes of each possible
decision / event combination (see figure 4.1).
The decision, D1, has two alternatives, D1,1 and D1,2. Alternative D1,1 is the choice to fire at the incoming airplane. Alternative D1,2 is the choice to release the airplane from targeting.
Uncertain event, E1, also has two possibilities, E1,1 and E1,2. E1,1 is the chance event that the unknown plane is a hostile military aircraft. E1,2 is the event that the plane is not hostile. For now we will assume no information concerning the plane's identity is available, and so the decision maker's probability estimates of the possible outcomes are 0.5.
Given the combinations of decisions and
events, four possible outcomes are possible (see figure 4.2).
This analysis could be done in units of dollars, or some military
point scale, but I have chosen to do this analysis in terms of
lives lost that the commander of the Vincennes (Captain William
Rogers) had to worry about. If he fired at an enemy F-14, one
or two lives would be lost, but this would not be of concern to
Cpt. Rogers since they would be enemy soldiers, and such is the
course of battle. If, however, the Vincennes fired, and the airplane
was a civilian airliner, then up to 300 or so lives could be lost.
Although the decision maker did not know it at the time, 290
passengers were on the plane -- so this number is used as the
outcome of shooting at a non-hostile plane. Releasing a hostile
plane would endanger the crew of the USS Vincennes. Although
it is not expected that an Iraqi fighter could destroy the battleship,
up to 400 lives could have been affected since there were 400
crewmen aboard the Vincennes. Finally, releasing a non-hostile
airplane would result in 0 lives lost.
| Decision | Event | Outcome (lives) |
| Fire | Hostile | 0 |
| Fire | Not Hostile | -290 |
| Release | Hostile | -400 |
| Release | Not Hostile | 0 |
Figure 4.1 shows that the expected outcome, O, of this decision tree is 145 lives lost and the best decision is to fire.
Various units of information content were
available to help reduce the uncertainty of event E1.
U1,1 A "Mode II IFF squawk" was detected and attributed to the aircraft -- indicating it was a military aircraft. (The IFF system is an interrogation transmitter that asks a plane if it is friend or foe. In response, the plane emits a message called an IFF squawk. Mode II means it is a military plane.)
U1,2 The aircraft was off the center line of the commercial air corridor by three or four miles.
U1,3 The aircraft did not respond to radio requests for its identity.
U1,4
The aircraft's altitude was reported to be declining as it approached
-- characteristic of a fighter on an attack run.
For illustrative purposes, we will consider only the effect of the first unit of data, U1,1, on the uncertain event probability estimates. This simplification of the problem will affect the absolute results obtained, but will allow us to better illustrate the use of the model.
In assessing the potential impact of data quality on the decision to shoot at the air liner, we will first add the quality components to the analysis at the levels thought to be present during the actual incident. Then, we will alter the quality and see the impact it has on the optimal decisions and expected outcomes. This analysis will show what changes in expected outcome will occur "on average" given a change in data quality. In order to assess the quality of the data, we must first consider possible degradation of data accuracy and availability.
Accuracy of the IFF system was subject to two sources of degradation -- source accuracy and source credibility. In this case source accuracy refers to the ability of the IFF hardware to deliver an accurate message to the decision makers. The system was highly accurate in this respect -- errors were possible if military and civilian aircraft being interrogated were flying close together, but were rare. Thus, Q1,acc,1 = 0.9. A more likely degradation of accuracy of the IFF data results from the credibility of the users. The Iranians were known to switch the IFF systems in planes so that military planes could read civilian, and civilian planes could read military. Thus, Q1,acc,2 = 0.6. As a result, Q1,acc = Q1,acc,1 * Q1,acc,2 = 0.9 * 0.6 = 0.54.
Availability is affected by the ability of the IFF system to provide a response when necessary, and the probability that the Iraqis might remove or disable the system. In this case, we estimate that Q1,avail,1 = 0.9 and Q1,avail,2 = 0.7. The resulting availability of data is Q1,avail = 0.63.
Using this information, we can modify the
original context decision tree as shown in figure 4.3. It is
a coincidence that with the quality accounted for and set to its
nominal values, there is no change in expected outcome -- a loss
of 145 lives is still expected.
Varying availability and accuracy data
quality factors, we can then assess the value of each. In conducting
this sensitivity analysis, we altered (one at a time) each of
the four data quality factors to perfect 1.0 quality level while
leaving all other levels fixed. Figure 4.4 shows how improving
Q1,acc,2 to a perfect level can cut the expected
loss of life (assuming that decisions similar to this will be
made again) from 145 to 75 .
| Q1,acc,1 | Q1,acc,2 | Q1,acc | O |
| 0.9 | 0.6 | 0.54 | -145 |
| 1.0 | 0.6 | 0.6 | -141 |
| 0.9 | 1.0 | 0.9 | -75 |
It is interesting to note that in this
case changing availability of the data has no effect on the expected
outcome (see figure 4.5). To understand how this can occur consider
the decision tree as shown in figure 4.6. Notice that for the
nominal values of data accuracy, there is no difference in expected
outcome between the case in which data is available and the case
in which it is not. Thus, assuming these nominal values are correct,
there is no point in improving data accuracy without first improving
data accuracy. From this analysis, we can see the value (in terms
of lives) of removing each of the possible sources of data degradation.
| Q1,avail,1 | Q1,avail,2 | Q1,avail | O |
| 0.9 | 0.7 | 0.63 | -145 |
| 1.0 | 0.7 | 0.7 | -145 |
| 0.9 | 1.0 | 0.7 | -145 |

Another way to view the effect of data quality on expected outcome is to vary the qualities of accuracy and availability directly, and to compute the effect on expected outcome. In doing this, we can view the different combinations of data quality levels which can lead to desired levels of expected outcome. Once these are determined, it is possible to compute the combinations of data quality factor levels which can attain the necessary data quality levels.
Figure 4.7 shows the expected outcome for the Vincennes case as a function of accuracy and availability of U1.
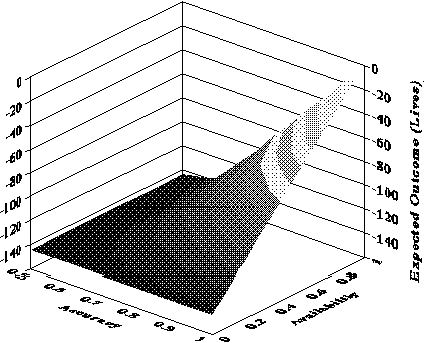
Notice that high accuracy or availability alone will not yield a good expected outcome -- both must be at satisfactory levels.
Thus, data qualities and their factors for the Vincennes case have been valued in terms of the number of lives that might be expected to be affected should similar incident occur in the future.
A model has been developed to compute the value of a change in data quality for a unit of data content in a given context. Furthermore, this model has been demonstrated in the valuation of data in the case of the USS Vincennes.
Important theoretical aspects of the model are that it objectively accounts for data context and content in assessing the value of changes in data quality. Values can now be assigned to changes in data quality without reliance on subjective survey of data customers.
More theoretical work remains, however. The nature of and an example of a list of data qualities and factors has been presented. Further work should focus on expanding the list of qualities considered, and for relating the data quality factors to data production processes.
From an application standpoint, the model has proved quite useful in evaluating data quality changes in the case of the USS Vincennes. It is expected that the model can be extended and improved as it is applied to a wider variety of cases.
[1] Bailey, J. E. and S. W. Pearson, Development of a Tool for Measuring and Analyzing Computer User Satisfaction. Management Science, 29(5) 1983, pp. 530-545.
[2] Ballou, D. P. and H. L. Pazer, Modeling Data and Process Quality in Multi-input, Multi-output Information Systems. Management Science, 31(2) 1985, pp. 150-162.
[3] Baroudi, J. J. and W. J. Orlikowski, A Short-Form Measure of User Information Satisfaction: A Psychometric Evaluation and Notes on Use. Journal of Management Information Systems, 4(4) 1988, .
[4] Clemen, R. T., Making Hard Decisions: An Introduction to Decision Analysis. 1 ed. PWS-KENT Publishing Company, Boston., 1991.
[5] Davis, F. D., Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology. Management Information Systems Quarterly, (September) 1989, pp. 319-340.
[6] Dillard, R. A., Using Data Quality Measures in Decision-Making Algorithms. 1992, pp. 63-72.
[7] Friedman, N. The Vincennes Incident. in Proceedings ofU.S. Naval Institute Proc. Annapolis, Md.: pp. 72-80.
[8] Huh, Y. U., R. W. Pautke and T. C. Redman. Data Quality Control. in Proceedings ofISQE, Juran Institute7A1-27.
[9] Juran, J. M. &. G., F. M., Quality Control Handbook. 4 ed. McGraw-Hill Book Co., New York., 1988.
[10] Kon, H. B., J. Lee and R. Y. Wang (1993). A Process View of Data Quality. (No. TDQM-93-01).
[11] Moore, G. C. and I. Benbasat, Development of an Instrument to Measure the Perceptions of Adopting an Information Technology Innovation. Information Systems Research, 2(3) 1991, pp. 192-222.
[12] Morey, R. C., Estimating and Improving the Quality of Information in the MIS. Communications of the ACM, 25(5) 1982, pp. 337-342.
[13] Rogers, W. C., Storm Center. 1 ed. Naval Institute Press, Annapolis., 1991.
[14] Wang, R. Y., D. M. Strong and L. M. Guarascio (1993). An Empirical Investigation of Data Quality Dimensions: A Data Consumer's Perspective. (No. TDQM-93-12). MIT Sloan School of Management.