Acknowledgments: Work
reported herein has been supported, in part, by MIT's Total Data
Quality Management (TDQM) Research Program, MIT's International
Financial Services Research Center (IFSRC), Fujitsu Personal Systems,
Inc., Bull-HN, Advanced Research Projects Agency and USAF/Rome
Laboratory under USAF Contract, F30602-93-C-0160, and the Naval
Command, Control and Ocean Surveillance Center under the Tactical
Image Exploitation (TIX) and TActical Decision Making Under Stress
(TADMUS) research programs.
Many databases are not error-free, and some contain a surprisingly large number of errors [Johnson, Leitch, & Neter, 1981; Laudon, 1986; Redman, 1992]. A recent industry report, for example, notes that more than 60 percent of the surveyed firms (500 medium size corporations with annual sales of more than $20 million) have problems with data quality. Poor data quality can have substantial social and economic impacts [Liepins, Garfinkel, & Kunnathur, 1982; Oman & Ayers, 1988; Liepins & Uppuluri, 1990; Strong, 1992; Wang & Kon, 1993; Strong & Miller, 1994].
Practical methods and tools for managing data quality have been developed and applied in industry. For example, AT&T developed a data quality management approach based on their process management and improvement guidelines [AT&T, 1988]. The approach involves seven steps: (1) establishing a process owner, (2) describing the current process and identifying customer requirements, (3) establishing a system of measurement, (4) establishing statistical control, (5) identifying improvement opportunities, (6) selecting improvement opportunities to pursue and setting objectives for doing so, and (7) making changes and sustaining gains. This approach has been successfully applied both within and outside AT&T [Huh, Keller, Redman, & Watkins, 1990; Pautke & Redman, 1990; Redman, 1992]. Another data quality management approach taken in several organizations entails two phases [Hansen, 1990; McGee & Wang, 1993; Wang & Kon, 1993]. In the first phase, the data quality proponent initiates a data quality project by identifying an area in which organizational effectiveness is critically impacted by poor data quality. In the second phase, the proponent strives to become the leader for data quality management in the organization. Other firms have developed variations of the above two approaches.
Software tools for data quality management are also available. For example, QDB Solution, Inc., a Cambridge, Massachusetts firm, offers a zero defect data methodology, statistical and rule-based error checking algorithms, and a tool that creates pareto charts to identify critical data quality problems. Vality Technology Inc., a Boston, Massachusetts firm, offers audit, integration, and parameter-driven approaches to resolve conflicts in multiple applications. Mobius Management Systems, Inc., a New Rochelle, New York firm, offers an automatic balancing system for MVS, cross-application validation checks, and information for management reporting. Finally, Evolutionary Technologies, Inc., an Austin, Texas firm, provides methods to simplify data conversion processes using its EXTRACT Data Conversion Tool [Percy, 1993].
Although firms are improving data quality with these approaches and tools, their improvement efforts tend to focus narrowly on accuracy, an intrinsic aspect of data quality. Based on our review of the product quality literature and our experience with data consumers (people or groups who have experience in using organizational data to make business decisions), we believe that data consumers have a much broader data quality conceptualization than IS professionals realize. However, a clear understanding of what data quality means to data consumers has not been reported in the literature. The purpose of this paper, therefore, is to present a framework that captures the aspects of data quality that are important to data consumers.
Approaches for assessing product quality attributes that are important to consumers are well-established in the marketing discipline [Kotler, 1984; Churchill, 1991]. Following the marketing literature, this research identifies the attributes of data quality that are important to data consumers.
We first developed two surveys that were used to collect data from data consumers (referred to as the two-stage survey later). The first survey produced a list of possible data quality attributes, attributes that came to mind when the data consumer thought about data quality. The second survey assessed the importance of these possible data quality attributes to data consumers. The importance ratings from the second survey were used in an exploratory factor analysis to yield an intermediate set of data quality dimensions that were important to data consumers. (We define a data quality dimension as a set of data quality attributes that most data consumers react to in a fairly consistent way. This treatment of dimension is consistent with previous empirical research, e.g., Zmud, Lind, & Young [1990].)
Because the detailed surveys produced a comprehensive set of data quality attributes for input to factor analysis, a broad spectrum of intermediate data quality dimensions were revealed. We conducted a follow-up empirical study to group these intermediate data quality dimensions for the following reasons. First, it is probably not critical for evaluation purposes to consider so many quality dimensions [Kriebel, 1979]. Second, although these dimensions can be ranked by the importance ratings, the highest ranking dimensions may not capture the essential aspects of data quality. Third, the intermediate dimensions seem to form several families of factors. Grouping these intermediate data quality dimensions into families of factors is consistent with research in the marketing discipline. For example, Deshpande [1982] grouped participation in decision making and hierarchy of authority together as a family, named centralization factors, and job codification and job specificity as a family, named formalization factors.
In grouping these intermediate dimensions into families, we used a preliminary conceptual framework developed from our experience with data consumers. This conceptual framework consisted of four "ideal" or target categories. Our intent was to evaluate the extent to which the intermediate dimensions matched these categories. Thus, our follow-up study moved beyond the purely exploratory nature of the two-stage survey to a more confirmatory study.
This follow-up study consisted of two phases (referred to as the two-phase study later). For the first phase, subjects were instructed to sort these dimensions into categories, and then label the categories. For the second phase, a different set of subjects were instructed to sort these dimensions into the categories revealed from the first phase to confirm these findings.
The key result of this research is a comprehensive framework of data quality from data consumers' perspectives. Such a framework serves as a foundation for improving the data quality dimensions that are important to data consumers. Our analysis is oriented toward the characteristics of the quality of data in use, in addition to the characteristics of the quality of data in production and storage; therefore, it extends the concept of data quality beyond the traditional development view. Our results have been used effectively in industry and government. Several Fortune 100 companies (and the U.S. Navy) have used our framework to identify potential areas of data deficiencies, operationalize the measurements of these data deficiencies, and improve data quality along these measures.
The concept of "fitness for use" is now widely adopted in the quality literature. It emphasizes the importance of taking a consumer viewpoint of quality because ultimately it is the consumer who will judge whether a product is fit for use or not [Juran & Gryna, 1980; Deming, 1986; Juran, 1989; Dobyns & Crawford-Mason, 1991]. In this research, we also take the consumer viewpoint of "fitness for use" in conceptualizing the underlying aspects of data quality.
Three approaches are used in the literature to study data quality: (1) intuitive, (2) theoretical, and (3) empirical. An intuitive approach is taken when the selection of data quality attributes for any particular study is based on the researchers' experience or intuitive understanding about what attributes are "important." Most data quality studies fall into this category. The cumulative effect of these studies is a small set of data quality attributes that are commonly selected. For example, many data quality studies include accuracy as either the only or one of several key dimensions [Morey, 1982; Ballou & Pazer, 1985; Laudon, 1986; Ballou & Tayi, 1989; Ballou & Pazer, 1994]. In the accounting and auditing literature, reliability is a key attribute used in studying data quality [Yu & Neter, 1973; Cushing, 1974; Bodnar, 1975; Johnson, Leitch, & Neter, 1981; Knechel, 1983; Knechel, 1985]. In the information systems literature, information quality and user satisfaction are two major dimensions for evaluating the success of information systems [Delone & McLean, 1992]. These two dimensions generally include some data quality attributes, such as accuracy, timeliness, precision, reliability, currency, completeness, and relevancy [Kriebel, 1979; Bailey & Pearson, 1983; Ives, Olson, & Baroudi, 1983]. Other attributes such as accessibility and interpretability are also used in the data quality literature [Wang, Reddy, & Kon, 1992; Wang, Kon, & Madnick, 1993].
A theoretical approach to data quality focuses on how data may become deficient during the data manufacturing process. Although theoretical approaches are often recommended, there are few research examples. One such study uses an ontological approach in which attributes of data quality are derived based on data deficiencies, which are defined as the inconsistencies between the view of a real-world system that can be inferred from a representing information system and the view that can be obtained by directly observing the real-world system [Wand & Wang, 1994].
The advantage of using an intuitive approach is that each study can select the attributes most relevant to the particular goals of that study. The advantage of a theoretical approach is the potential to provide a comprehensive set of data quality attributes that are intrinsic to a data product. The problem with both of these approaches is that they focus on the product in terms of development characteristics instead of use characteristics. They fail to capture the voice of the consumer. Evaluations of theoretical approaches to defining product attributes as a basis for improving quality find that they are not an adequate basis for improving quality and are significantly worse than empirical approaches [Griffin & Hauser, 1993]. To capture the data quality attributes that are important to data consumers, therefore, we took an empirical approach and collect data from data consumers.
Three tasks were suggested in identifying quality attributes of a product: (1) identifying consumer needs, (2) identifying the hierarchical structure of consumer needs, and (3) measuring the importance of each consumer need [Hauser & Clausing, 1988; Griffin & Hauser, 1993]. Some, but not all, of these tasks were performed in data quality research. Based on Gallagher's earlier research [Gallagher, 1974] and their personal communications, Zmud [1978] produced 25 attributes, which were used by 35 students to rate three graphical and tabular reports. A factor analysis of the ratings produced eight dimensions, which Zmud grouped into four families of dimensions: (1) quality of information, (2) relevancy components, (3) quality of format, and (4) quality of meaning. Bailey & Pearson [1983] collected importance ratings to compute the weighted average of the satisfaction ratings. Davis [1989] also collected importance ratings from information systems users. Most of these studies identified multiple dimensions of data consumers' quality needs. Furthermore, although a hierarchical view of data quality was less common, it was reported in several studies [Zmud, 1978; Kriebel, 1979; Redman, 1992; Wang, Reddy, & Gupta, 1993]. None of these studies, however, empirically collected data quality attributes from data consumers.
In this research, we followed the general recommendations of Griffin & Hauser [1993] and first collected data quality attributes from data consumers. We then collected importance ratings for these attributes and structured them into a hierarchical representation of data consumers' data quality needs. Our goal was to develop a comprehensive, hierarchical framework of data quality attributes that were important to data consumers.
Some researchers may doubt the validity of asking consumers about important quality attributes because of the well-known difficulties with evaluating users' satisfaction with information systems [Melone, 1990]. We reject this out of hand because importance ratings and user satisfaction are two different constructs [Griffin & Hauser, 1993]. Hauser & Griffin [1993], for example, demonstrate that determining attributes of importance to consumers, collecting importance ratings of these attributes, and measuring attribute values are valid characterizations of consumers' actions such as purchasing the product, but satisfaction ratings of these attributes are uncorrelated with consumer actions.
Based on the limited relevant literature, the concept of fitness for use from the quality literature, and our experiences with data consumers, we propose a preliminary conceptual framework for data quality that includes the following aspects:
The data must be accessible to the data consumer. For example, the consumer knows how to retrieve the data.
The consumer must be able to interpret the data. For example, the data are not represented in a foreign language.
The data must be relevant to the consumer. For example, data are relevant and timely for use by the data consumer in the decision making process.
The consumer must find the data accurate. For example, the data are correct, objective and come from reputable sources.
Although we hypothesize that any data quality framework that captures data consumers' perspectives of data quality will include the above aspects, we do not bias our initial data collection in the direction of our conceptualization. To be unbiased, we start with an exploratory approach that includes not only the attributes in our preliminary framework, but also the attributes mentioned in the literature. For example, our first questionnaire starts with some attributes (timeliness and availability) which are not part of this preliminary framework.
The method for the two-stage survey was as follows. For Stage one, we conducted a survey to generate a list of data quality attributes that capture data consumers' perspectives of data quality. For Stage two, we first conducted a survey to collect data on the importance of each of these attributes to data consumers, and then performed an exploratory factor analysis on the importance data to develop an intermediate set of data quality dimensions.
The purpose of the first survey was to generate an extensive list of potential data quality attributes. Since the data quality dimensions resulting from factor analysis depend, to a large extent, on the list of attributes generated from the first survey, we decided that: (1) the subjects should be data consumers who have used data to make decisions in diverse contexts within organizations; and (2) we should be able to probe and question the subjects in order to fully understand their answers.
Subjects Two pools of subjects were selected. The first consisted of 25 data consumers currently working in industry. The second was MBA students at a large eastern U.S. university. We selected 112 students that had work experience as data consumers. The average age of these students was over 30.
Survey Instrument The first survey instrument (see Appendix A) included two sections for eliciting data quality attributes. The first section elicited respondents' first reaction to data quality by asking them to list those attributes which first came to mind when they thought of data quality (beyond the common attributes of timeliness, accuracy, availability, and interpretability). The second section provided further cues by listing 32 attributes beyond the four common ones to "spark" any additional attributes. These 32 attributes were obtained from data quality literature and discussions among data quality researchers.
Procedure For the selected MBA students, the first survey was self-administered. For the subjects working in industry, the administration of the survey was followed by a discussion of the meanings of the attributes the subjects generated.
Results This process resulted in 179 attributes as shown in Figure 2.
The purpose of the second survey was to collect data about the importance of quality attributes as perceived by data consumers. The results of the second survey were ratings of the importance of the data quality attributes. These importance ratings were the input for a factor analysis.
Subjects Since a sample consisting of a wide range of data consumers with different perspectives was necessary, we selected the alumni of the MBA program of a large eastern university who reside in the U.S. These alumni consisted of individuals in a variety of industries, departments, and management levels who regularly used data to make decisions, thus satisfying the requirement for data consumers with diverse perspectives. From over 3200 alumni, we randomly selected 1500 subjects.
Survey Instrument The list of attributes shown in Figure 2 was used to develop the second survey questionnaire (see Appendix B). The questionnaire asked the respondent to rate the importance of each data quality attribute for their data on a scale from 1 to 9, where 1 was extremely important and 9 not important. The questionnaire was divided into four sections depending on the appropriate wording of the attributes, e.g., as stand-alone adjectives or as complete sentences.
A pre-test of the questionnaire was administered
to fifteen respondents: five industry executives, six professionals,
two professors, and two MBA students. The purpose of the pre-test
was to eliminate those attributes which a majority of respondents
did not understand or did not see any relation between them and
data quality. Changes were made in the format of the survey as
a result of the pre-test. Based on the results from the pre-test,
the final second survey questionnaire included 118 data quality
attributes (i.e., 118 items for factor analysis) to be rated for
their importance, as shown in Appendix B.
| Ability to be Joined With | Ability to Download | Ability to Identify Errors | Ability to Upload |
| Acceptability | Access by Competition | Accessibility | Accuracy |
| Adaptability | Adequate Detail | Adequate Volume | Aestheticism |
| Age | Aggregatability | Alterability | Amount of Data |
| Auditable | Authority | Availability | Believability |
| Breadth of Data | Brevity | Certified Data | Clarity |
| Clarity of Origin | Clear Data Responsibility | Compactness | Compatibility |
| Competitive Edge | Completeness | Comprehensiveness | Compressibility |
| Concise | Conciseness | Confidentiality | Conformity |
| Consistency | Content | Context | Continuity |
| Convenience | Correctness | Corruption | Cost |
| Cost of Accuracy | Cost of Collection | Creativity | Critical |
| Current | Customizability | Data Hierarchy | Data Improves Efficiency |
| Data Overload | Definability | Dependability | Depth of Data |
| Detail | Detailed Source | Dispersed | Distinguishable Updated Files |
| Dynamic | Ease of Access | Ease of Comparison | Ease of Correlation |
| Ease of Data Exchange | Ease of Maintenance | Ease of Retrieval | Ease of Understanding |
| Ease of Update | Ease of Use | Easy to Change | Easy to Question |
| Efficiency | Endurance | Enlightening | Ergonomic |
| Error-Free | Expandability | Expense | Extendibility |
| Extensibility | Extent | Finalization | Flawlessness |
| Flexibility | Form of Presentation | Format | Integrity |
| Friendliness | Generality | Habit | Historical Compatibility |
| Importance | Inconsistencies | Integration | Integrity |
| Interactive | Interesting | Level of Abstraction | Level of Standardization |
| Localized | Logically Connected | Manageability | Manipulable |
| Measurable | Medium | Meets Requirements | Minimality |
| Modularity | Narrowly Defined | No lost information | Normality |
| Novelty | Objectivity | Optimality | Orderliness |
| Origin | Parsimony | Partitionability | Past Experience |
| Pedigree | Personalized | Pertinent | Portability |
| Preciseness | Precision | Proprietary Nature | Purpose |
| Quantity | Rationality | Redundancy | Regularity of Format |
| Relevance | Reliability | Repetitive | Reproducibility |
| Reputation | Resolution of Graphics | Responsibility | Retrievability |
| Revealing | Reviewability | Rigidity | Robustness |
| Scope of Info | Secrecy | Security | Self-Correcting |
| Semantic Interpretation | Semantics | Size | Source |
| Specificity | Speed | Stability | Storage |
| Synchronization | Time-independence | Timeliness | Traceable |
| Translatable | Transportability | Unambiguity | Unbiased |
| Understandable | Uniqueness | Unorganized | Up-to-Date |
| Usable | Usefulness | User Friendly | Valid |
| Value | Variability | Variety | Verifiable |
| Volatility | Well-Documented | Well-Presented |
Procedure This survey was mailed along with a cover letter explaining the nature of the study, the time to complete the survey (less than twenty minutes), and its criticality. Most of the alumni addresses were their home address. To assure a successful survey, we sent the survey questionnaires via first-class mail. We gave respondents a six week cut-off period to respond to the survey.
Response Rate Of the 1500 surveys mailed, sixteen were returned because they were undeliverable. Of the remaining 1484, 355 viable surveys (an effective response rate of 24 percent) were returned by the six week cut-off response date. Thus we had a response-to-variable ratio of 3, which is less than the recommended minimum ratio of 5.
As a result, the factor structure may be unstable. This is a limitation of this study in the sense that future confirmatory studies will be needed.
Missing Responses While none of the 118 attributes (items) had 355 responses, none had less than 329 responses. There did not appear to be any significant pattern to the missing responses.
The data quality dimensions were uncovered using factor analysis of the importance ratings collected from the 355 survey respondents. Exploratory factor analysis was appropriate for this study because its primary application is to uncover an underlying data structure [Kim & Mueller, 1978; Cureton & D'Agostino, 1983].
The factor analyses were performed using SYSTAT Version 5.1 for the Macintosh. We used the principal components method with the number of components limited using the "eigenvalue greater than 1" rule, followed by VARIMAX rotation to clarify the grouping pattern represented by the original principal component dimensions. We chose principal component analysis because the results are reproducible, less susceptible to misinterpretation, and factor scores will be uncorrelated across factors [Green & Welsh, 1988]. As specified by SYSTAT, the convergence criteria for stopping the analysis was either 25 iterations or a tolerance level, which was defined as "the amount of variance an original item shares with all other items," of .001. In our case, we reached the tolerance level before 25 iterations. The resulting components consisted of those items whose rotated component loadings were greater than .5; that is, an item was assigned to a particular component if the correlation between the component and the item was at least .5. Although this approach might appear simplistic, it is quite rigorous [Hair, Anderson, & Tatham, 1987].
The initial principal component analysis generated 29 components which explained 73.9 percent of the total variance in the data. Components were eliminated based on the following standard criteria; see, for example, Swanson [1987]: (1) all items loaded on the component at less than .5; (2) the mean importance of the component, as computed from the underlying item importance ratings, was greater than 5, the mid-point of our scale; and (3) the component could not be interpreted because the two or three items loading on the component were too dissimilar. This process identified ten components for elimination. We chose to eliminate all but the flexibility component. Although it had a mean importance rating of 5.34, flexibility was clearly interpretable, and therefore, was included for further analysis. The remaining twenty dimensions explained 59.3% of the total variance.
Respondent Characteristics The responses were spread fairly evenly across industries (Table 1). Specifically, there was about 28% from service, 33% from manufacturing, 19% from finance, and the remaining 20% cited "Others." Members of functional departments: finance, marketing/sales, and operations, evenly made up 44% of the respondents. There were a relatively large number of respondents who circled "Other." Frequently, these respondents were upper level managers, such as presidents or CEO's, or consultants (Table 2).
Attribute Characteristics Descriptive statistics of the 118 items (attributes) are presented in Appendix C. Most of the 118 items had a full range of values from 1 to 9, where 1 means extremely important and 9 not important. The exceptions were accuracy, reliability, level of detail, and easy identification of errors. Accuracy and reliability had the smallest range with values ranging from 1 to 7; level of detail and easy identification of errors ranged from 1 to 8. 99 of the 118 items (85%) had means less than or equal to 5; that is, most of the items surveyed were considered to be important data attributes. Two items had means less than 2 and thus were overall the most important data quality attributes: accuracy and correct, with means of 1.771 and 1.816 respectively.
Dimension Characteristics The twenty dimensions from the factor analysis of the 355 viable surveys, shown in Table 3, explained 59.3% of the total variance. Table 3 shows the items forming each dimension with their component loadings and the percentage of variance explained by each dimension. It is a condensed factor loading table showing only those items and dimensions retained from our analysis. The full factor loading table is shown in Appendix D.
A name was assigned to each dimension, as shown in Table 4. An interpretation of the dimensions is found in Appendix E. A dimension mean was computed as the average of the responses to all of the items with a loading of .5 or greater on the dimension. For example, the dimension ease of understanding consisted of the three items: easily understood, readable, and clear. The mean importance for ease of understanding was the average of the importance ratings for easily understood, readable, and clear. (See Table 4 for the means, standard deviations, and confidence intervals.)
Cronbach's alpha was computed for each dimension to assess the reliability of the set of items forming that dimension. As shown in the rightmost column of Table 4, these alpha coefficients ranged from 0.69 to 0.98.
| Believable | Reputation of Source | ||||||
| Data Reputation | |||||||
| Competitive Edge | |||||||
| Adds Value | Same Format | ||||||
| Consistently Represented | |||||||
| Applicable | Consistently Formatted | ||||||
| Relevant | Compatible w/Previous Data | ||||||
| Interesting | |||||||
| Usable | Cost of Collection | ||||||
| Cost of Accuracy | |||||||
| Certified Error Free | Cost Effectiveness | ||||||
| Error Free | |||||||
| Accurate | Easily Joined | ||||||
| Correct | Easily Integrated | ||||||
| Flawless | Easily Download/Upload | ||||||
| Reliable | Easily Aggregated | ||||||
| Easy Identification of Errors | Easily Customized | ||||||
| Integrity | Easily Updated | ||||||
| Precise | Easily Changed | ||||||
| Manipulable | |||||||
| Interpretable | Used for Multiple Purposes | ||||||
| Easily Reproduced | |||||||
| Easily Understood | |||||||
| Clear | Variety of Data and Sources | ||||||
| Readable | |||||||
| Well-Presented | |||||||
| Retrievable | Form of Presentation | ||||||
| Accessible | Concise | ||||||
| Speed of Access | Well-Organized | ||||||
| Available | Format of Data | ||||||
| Up-To-Date | Well-Formatted | ||||||
| Compactly Represented | |||||||
| Unbiased | Aesthetically Pleasing | ||||||
| Objective | |||||||
| No Access to Competitors | |||||||
| Age of Data | Proprietary | ||||||
| Access Can Be Restricted | |||||||
| Breadth of Information | Secure | ||||||
| Depth of Information | |||||||
| Scope of Information | Amount of Data | ||||||
| Well Documented | Adaptable | ||||||
| Verifiable | Flexible | ||||||
| Easily Traced | Extendable | ||||||
| Expandable | |||||||
| Name of Dimension (Attribute List) | |||||
| Believability | |||||
| (Believable) | |||||
| Value-added | |||||
| (Data Give You a Competitive Edge, Data Add Value to Your Operations) | |||||
| Relevancy | |||||
| (Applicable, Relevant, Interesting, Usable) | |||||
| Accuracy | |||||
| (Data Are Certified Error-Free, Error Free, Accurate, Correct, Flawless, Reliable, Errors Can Be Easily Identified, The Integrity of the Data, Precise) | |||||
| Interpretability | |||||
| (Interpretable) | |||||
| Ease of Understanding | |||||
| (Easily Understood, Clear, Readable) | |||||
| Accessibility | |||||
| (Accessible, Retrievable, Speed of Access, Available, UpToDate) | |||||
| Objectivity | |||||
| (Unbiased, Objective) | |||||
| Timeliness | |||||
| (Age of Data) | |||||
| Completeness | |||||
| (The Breadth, Depth, and Scope of Information
Contained in the Data) | |||||
| Traceability | |||||
| (Well-Documented, Easily Traced, Verifiable) | |||||
| Reputation | |||||
| (The Reputation of the Data Source, The Reputation of the Data) | |||||
| Representational Consistency | |||||
| (Data Are Continuously Presented In Same Format, Consistently Represented, Consistently Formatted, Data Are Compatible with Previous Data) | |||||
| Cost Effectiveness | |||||
| (Cost of Data Accuracy, Cost of Data Collection, Cost Effective) | |||||
| Ease of Operation | |||||
| (Easily Joined, Easily Changed, Easily Updated, Easily Downloaded/Uploaded, Data Can be Used for Multiple Purposes, Manipulable, Easily Aggregated, Easily Reproduced, Data Can Be Easily Integrated, EasilyCustomized) | |||||
| Variety of Data & Data Sources | |||||
| (You Have a Variety of Data and Data Sources) | |||||
| Concise | |||||
| (Well-Presented, Concise, Compactly Represented, WellOrganized, Aesthetically Pleasing, Form of Presentation, WellFormatted, Format of the Data) | |||||
| Access Security | |||||
| (Data Cannot be Accessed by Competitors, Data Are of a Proprietary Nature, Access To Data Can Be Restricted, Secure) | |||||
| Appropriate Amount of Data | |||||
| (The Amount of Data) | |||||
| Flexibility | |||||
| (Adaptable, Flexible, Extendable, Expandable) |
Twenty dimensions were too many for practical evaluation purposes. In addition, although these dimensions were ranked by the importance ratings, the highest ranking dimensions might not capture the essential aspects of data quality. Finally, a grouping of these dimensions was consistent with research in the marketing discipline, and substantiated a hierarchical structure of data quality dimensions.
Using our preliminary conceptual framework, we conducted a two-phase sorting study. The first phase of the study was to sort these intermediate dimensions into a small set of categories. The second phase was to confirm that these dimensions indeed belonged to the categories in our preliminary conceptual framework.
We first created four categories (see Column 1 of Table 5) based on our preliminary conceptual framework, following Moore & Benbasat [1991]. We then grouped the 20 intermediate dimensions into these four categories (see Column 2 of Table 5). Our initial grouping was based on our understanding of these categories and dimensions. The sorting study provided the data to test this initial grouping and to make adjustments in the assignment of dimensions to target categories (see Column 3 of Table 5), which will be further discussed.
Subjects A pool of 30 subjects from industry were selected to participate in the overall sorting procedure. These subjects were enrolled in an evening MBA class in another large eastern university. Eighteen of these 30 subjects were randomly selected to participate in the first phase.
Design Each of the 20 dimensions, along with a description, was printed on a 3x5-inch card, as shown in Appendix F1. These cards were used by each of the subjects in the study to group the 20 dimensions into a small set of categories. In contrast to Phase two, the subjects for Phase one were not given a pre-specified set of categories each with a name and description. Instead, they were asked to restrict the number of categories to three, four, or five. The study was pre-tested by two graduate-level MIS students to clarify any ambiguity in the design or instruction.
Procedure The study was run by a third party who was not aware of the goal of this research in order to avoid any bias by the authors. Before performing the actual sorting task, subjects were asked to perform a trial sort using dimensions other than these 20 dimensions to ensure that they understood the procedure. In the actual sorting task, subjects were given instructions to group the 20 cards into three to five piles. The subjects were then asked to label each of their piles.
| Target Category | Dimension | Adjustment |
| accuracy of data | believability | none |
| accuracy | none | |
| objectivity | none | |
| completeness | moved to category 2 | |
| traceability | eliminated | |
| reputation | none | |
| variety of data sources | eliminated | |
| relevancy of data | value-added | none |
| relevancy | none | |
| timeliness | none | |
| ease of operation | eliminated | |
| appropriate amount of data | none | |
| flexibility | eliminated | |
| representation of data | interpretability | none |
| ease of understanding | none | |
| representational consistency | none | |
| concise representation | none | |
| accessibility of data | accessibility | none |
| cost-effectiveness | eliminated | |
| access security | none |
The original assignment of dimensions to categories was adjusted based on the results from the phase-one study. For example, as shown in Column 3 of Table 5, completeness is moved from the accuracy category to the relevancy category because only four subjects assigned this dimension to the former category whereas twelve assigned it to the later. This was a reasonable adjustment because completeness could be interpreted within the context of the data consumer's task instead of our initial interpretation that completeness was part of the accuracy category.
In addition, five dimensions were eliminated: traceability, variety of data sources, ease of operation, flexibility, and cost-effectiveness. These dimensions were eliminated because of both of the following two reasons. First, subjects did not consistently assign the dimension to any category. For example, seven subjects assigned cost-effectiveness to the relevancy category, three assigned it to the other three categories, and eight assigned it to a self-defined category. Second, the dimension was not ranked highly in terms of importance. For example, cost-effectiveness was ranked 14 out of 20.
The purpose of the second phase of the sorting study was to confirm that the dimensions indeed belonged to these adjusted categories.
Subjects The remaining 12 subjects from our subject pool participated in this phase of study.
Design For each category of dimensions revealed from Phase one, the authors provided a label, as shown in Appendix F2, based on the underlying dimensions. Descriptive phrases rather than single words were used as labels to avoid confounding category labels with any of the dimension labels.
Procedure The third party that ran the phase-one study also ran the phase-two study. The procedure for Phase two was similar to that of Phase one, with the exception that subjects were instructed to place each of the dimension cards into the category that best represents that dimension.
In this section, we present the results from the two-phase study. Using the adjusted target categories, we tabulated the results from the phase-one study. As shown in Table 6, the overall placement ratio of dimensions within target categories was 70%. This indicated that these 15 dimensions were generally being placed in the appropriate categories.
|
| ||||||
| Total Item Placements: 270 | |||||||
These results, together with the adjustment of dimensions within the target categories, led us to refine the four target categories as follows:
(1) the extent to which data values are in conformance with the actual or true values.
(2) the extent to which data are applicable (pertinent) to the task of the data user.
(3) the extent to which data are presented in an intelligible and clear manner, and
(4) the extent to which data are available or obtainable.
These four descriptions were used as the category labels for the phase-two study. The results from the phase-two study (Table 7) showed that the overall placement ratio of dimensions within target categories was 81%.
|
| |||||
| Total Item Placements: 180 | ||||||
In our sorting study, we labeled each category based on our preliminary conceptual framework and our initial grouping of the dimensions. For example, we labeled as accuracy the category that includes believability, accuracy, objectivity, and reputation. Similarly, we labeled the three other categories as relevancy, representation, and accessibility. We used such a labeling so that we would not introduce any additional interpretations or biases into the sorting tasks.
However, such representative labels did not necessarily capture the essence of the underlying dimensions as a group. For example, as a whole, the group of dimensions labeled accuracy was richer than that conveyed by the label accuracy. Thus, we re-examined the underlying dimensions confirmed for each of the four categories, and picked a label that captured the essence of the entire category. For example, we re-labeled accuracy as intrinsic DQ because the underlying dimensions captured the intrinsic aspect of data quality.
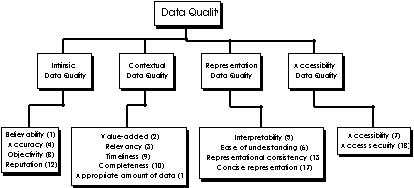
As a result of this re-examination, we re-labeled two of the four categories. The resulting categories, therefore, are: intrinsic DQ, contextual DQ, representation DQ, and accessibility DQ (see Figure 3). Intrinsic DQ denotes that data have quality in their own right. Accuracy is merely one of the four dimensions underlying this category. Contextual DQ highlights the requirement that data quality must be considered within the context of the task at hand; i.e., data must be relevant, timely, complete, and appropriate in terms of amount so as to add value. Representation DQ and accessibility DQ emphasize the importance of the role of systems; i.e., the system must be accessible but secure, and the system must present data in such a way that they are interpretable, easy to understand, and represented concisely and consistently.
This hierarchical framework confirms and substantiates the preliminary framework that we proposed. Below we elaborate on these four categories, relate them to the literature, and discuss some future research directions.
Intrinsic DQ includes not only accuracy and objectivity which are evident to IS professionals, but also believability and reputation. This suggests that, contrary to the traditional development view, data consumers also view believability and reputation as an integral part of intrinsic DQ; accuracy and objectivity alone are not sufficient for data to be considered high quality. This has an analogy to some aspects of product quality. In the product quality area, dimensions of quality emphasized by consumers are broader than those emphasized by product manufacturers. Similarly, intrinsic DQ encompasses more than the accuracy and objectivity dimensions that IS professionals strive to deliver. This finding implies that IS professionals should also ensure the believability and reputation of data. Research on data source tagging [Wang & Madnick, 1990; Wang, Reddy, & Kon, 1992] is a step in this direction.
The individual dimensions underlying contextual DQ were reported previously. For example, completeness and timeliness were reported [Ballou & Pazer, 1985]. However, contextual DQ was not explicitly recognized in the data quality literature. Our grouping of dimensions for contextual DQ revealed that data quality must be considered within the context of the task at hand. This was consistent with the literature on graphical data representation, which concluded that the quality of a graphical representation must be assessed within the context of the data consumer's task [Tan & Benbasat, 1990].
Since tasks and their contexts vary across time and data consumers, attaining high contextual data quality is a research challenge. One approach is to parameterize contextual dimensions for each task so that a data consumer can specify what type of task is being performed and the appropriate contextual parameters for that task. Below we illustrate such a research prototype.
During Desert Storm combat operations, naval researchers recognized the need to explicitly incorporate contextual DQ into information systems in order to deliver more timely and accurate information. As a result, a prototype is being developed which will be deployed to the U.S. aircraft carriers as stand-alone image exploitation tools [Page & Kaomea, 1994]. This prototype parameterizes contextual dimensions for each task so that a pilot or a strike planner can specify what type of task (e.g., strike plan or damage assessment) is being performed and the appropriate contextual parameters (relevant images in terms of location, currency, resolution, and target type) for that task.
Representation DQ includes aspects related to the format of the data (concise and consistent representation) and meaning of data (interpretability and ease of understanding). The existence of these two aspects is identified by Zmud [1978]. These two aspects suggest that for data consumers to conclude that data are well-represented, they must not only be concise and consistently represented, but also interpretable and easy to understand.
Issues related to meaning and format arise in database systems research [Sheth & Larson, 1990; Storey & Goldstein, 1993]. There, format is addressed as part of syntax, and meaning as part of semantic reconciliation. One focus of current research in that area is context interchange among heterogeneous database systems [Siegel, Sciore, & Rosenthal, 1994]. For example, currency figures in the context of a U.S. database are typically in dollars, whereas those in a Japanese database are likely to be in yens. This type of context belongs to the representation DQ, instead of contextual DQ that deals with the data consumer's task.
IS professionals understand accessibility DQ well. Our research findings show that data consumers also recognize its importance. Our findings appear to differ from the literature which treats accessibility distinctly from information quality; see, for example, [Culnan, 1984; Swanson, 1987; Zmud, Lind, & Young, 1990]. A closer examination reveals that information quality as defined in this body of literature is rooted in a study by Zmud [1978] in which subjects are given the information content of three report formats. As such, accessibility is presumed (i.e., perfect accessibility DQ). In contrast, data consumers in our research access computers for their information needs, and therefore, view this as an important data quality aspect. However, there is little difference between treating accessibility DQ as a category of overall data quality, or separating it from other categories of data quality. In either case, accessibility needs to be taken into account.
We have presented a two-stage survey and a two-phase sorting study to develop a hierarchical framework for organizing data quality dimensions. This framework has four data quality (DQ) categories: (1) intrinsic DQ consists of believability, accuracy, objectivity, and reputation; (2) contextual DQ consists of value-added, relevancy, timeliness, completeness, and appropriate amount of data; (3) representation DQ consists of interpretability, ease of understanding, representational consistency, and concise representation; and (4) accessibility DQ consists of accessibility and access security.
This framework captures dimensions of data quality that are important to data consumers. Intrinsic DQ denotes that data have quality in their own right. Contextual DQ highlights the requirement that data quality must be considered within the context of the task at hand. Representation DQ and accessibility DQ emphasize the importance of the role of systems. These findings are consistent with our understanding that high quality data should be intrinsically good, contextually appropriate for the task, clearly represented, and accessible to the data consumer.
Our framework has been used effectively in industry and government. For example, IS managers in one investment firm thought they had perfect data quality (in terms of accuracy) in their organizational databases. However, in their discussion with data consumers using this framework, they found several deficiencies including: (1) additional information about data sources was needed so that data consumers could assess the reputation and believability of data, (2) data downloaded to servers from the mainframe were not sufficiently timely for some data consumers' tasks, and (3) the currency ($, £, or ¥) and unit (thousands or millions) of financial data from different servers were implicit so data consumers could not always interpret and understand these data correctly. Using this framework, these IS managers were able to better understand and meet their data consumers' data quality needs.
The salient feature of this research study is that quality attributes of data are collected from data consumers instead of defined theoretically or based on researchers' experience. Furthermore, this study provides additional evidence for a hierarchical structure of data quality dimensions. A major limitation of this study is the sample size for the factor analysis. Because of the less than minimum response-to-variable ratio, the underlying factor structure may not be stable. Although the resulting factors have high face validity, additional confirmatory studies are needed to validate these research findings. Another limitation of this study is that we constrain the subjects to use three to five categories in the sorting study.
Our research is exploratory, not only because of
the sample size, but also because no data quality model existed
on which to base our study. Although exploratory, this research
provides a basis for future confirmatory studies, and for studies
that measure data quality along the dimensions of this framework.
Our long term research agenda includes data quality definition,
measurement, analysis, and improvement. Currently, we are working
on how data quality should be measured, how organizations are
redefining their data quality beyond accuracy, and how organizations
learn to improve their data quality.
AT&T (1988). Process Management & Improvement Guidelines, Issue 1.1. (No. Select Code 500-049). AT&T.
Bailey, J. E. & Pearson, S. W. (1983). Development of a Tool for Measuring and Analyzing Computer User Satisfaction. Management Science, 29(5), 530-545.
Ballou, D. P. & Pazer, H. L. (1985). Modeling Data and Process Quality in Multi-input, Multi-output Information Systems. Management Science, 31(2), 150-162.
Ballou, D. P. & Pazer, H. L. (1994). Designing Information Systems to Optimize the Accuracy-Timeliness Tradeoff. To appear in Information Systems Research (ISR).
Ballou, D. P. & Tayi, K. G. (1989). Methodology for Allocating Resources for Data Quality Enhancement. Communications of the ACM, 32(3), 320-329.
Bodnar, G. (1975). Reliability Modeling of Internal Control Systems. The Accounting Review, 50(4), 747-757.
Churchill, G. A. (1991). Marketing Research: Methodological Foundations. Dryden Press.
Culnan, M. (1984). The Dimensions of Accessibility to Online Information: Implications for Implementing Office Information Systems. ACM Transactions on Office Information Systems, 2(2), 141-150.
Cureton, E. E. & D'Agostino, R. B. (1983). Factor Analysis: An Applied Approach. Hillsdale, N.J.: Lawerence Erlbaum.
Cushing, B. E. (1974). A Mathematical Approach to the Analysis and Design of Internal Control Systems. Accounting Review, 49(1), 24-41.
Davis, F. D. (1989). Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology. Management Information Systems Quarterly(September), 319-340.
Delone, W. H. & McLean, E. R. (1992). Information Systems Success: The Quest for the Dependent Variable. Information Systems Research, 3(1), 60-95.
Deming, E. W. (1986). Out of the Crisis. Cambridge: Center for Advanced Engineering Study, Massachusetts Institute of Technology.
Deshpande, R. (1982). The Organizational Context of Marketing Research Use. Journal of Marketing, 46(4), 91-101.
Dobyns, L. & Crawford-Mason, C. (1991). Quality or Else: The Revolution in World Business. Boston, MA: Houghton Mifflin.
Gallagher, C. A. (1974). Perceptions of the Value of a Management Information System. Academy of Management Journal, 17(1), 47-55.
Green, S. G. & Welsh, M. A. (1988). Cybernetics and dependence: reframing the control concept. Academy of Management Review, 13(2), 287-301.
Griffin, A. & Hauser, J. R. (1993). The Voice of the Customer. Marketing Science, 12(1), 1-27.
Hair, J. F. J., Anderson, R. E., & Tatham, R. L. (1987). Multivariate Data Analysis with Readings. New York: Macmillan.
Hansen, M. D. (1990). Zero Defect Data: Tackling the Corporate Data Quality Problem. Masters Thesis, MIT Sloan School of Management.
Hauser, J. R. & Clausing, D. (1988). The House of Quality. Harvard Business Review, 66(3), 63-73.
Huh, Y. U., Keller, F. R., Redman, T. C., & Watkins, A. R. (1990). Data Quality. Information and Software Technology, 32(8), 559-565.
Ives, B., Olson, M. H., & Baroudi, J. J. (1983). The Measurement of User Information Satisfaction. Communications of the ACM, 26(10), 785-793.
Johnson, J. R., Leitch, R. A., & Neter, J. (1981). Characteristics of Errors in Accounts Receivable and Inventory Audits. Accounting Review, 56(2), 270-293.
Juran, J. M. (1989). Juran on Leadership for Quality: An Executive Handbook. New York: The Free Press.
Juran, J. M. & Gryna, F. M. (1980). Quality Planning and Analysis. New York: McGraw Hill.
Kim, J. & Mueller, C. (1978). Factor Analysis: Statistical Methods and Practical Issues. Newbury Park: SAGE Publications.
Knechel, W. R. (1983). The Use of Quantitative Models in the Review and Evaluation of Internal Control: A Survey and Review. Journal of Accounting Literature, 2, 205-219.
Knechel, W. R. (1985). A Simulation Model for Evaluating Accounting Systems Reliability. Auditing: A Journal of Theory and Practice, 4(2), 38-62.
Kotler, P. (1984). Marketing Management: Analysis, Planning, and Control. Englewood Cliffs, New Jersey, 07632: Prentice-Hall, Inc.
Kriebel, C. H. (1979). Evaluating the Quality of Information Systems. In Design and Implementation of Computer Based Information Systems. (pp. 29-43). Germantown: Sijthtoff & Noordhoff.
Laudon, K. C. (1986). Data Quality and Due Process in Large Interorganizational Record Systems. Communications of the ACM, 29(1), 4-11.
Liepins, G. E., Garfinkel, R. S., & Kunnathur, A. S. (1982). Error localization for erroneous data: A survey. TIMS/Studies in the Management Science, 19, 205-219.
Liepins, G. E. & Uppuluri, V. R. R. (Ed.). (1990). Data Quality Control: Theory and Pragmatics. New York: Marcel Dekker, Inc.
McGee, A. M. & Wang, R. Y. (1993). Total Data Quality Management (TDQM): Zero Defect Data Capture. In The Chief Information Officer (CIO) Perspectives Conference, Tucson, Arizona: The CIO Publication.
Melone, N. (1990). A Theoretical Assessment of the User-Satisfaction Construct in Information Systems Research. Management Science, 36(1), 598-613.
Moore, G. C. & Benbasat, I. (1991). Development of an Instrument to Measure the Perceptions of Adopting an Information Technology Innovation. Information Systems Research, 2(3), 192-222.
Morey, R. C. (1982). Estimating and Improving the Quality of Information in the MIS. Communications of the ACM, 25(5), 337-342.
Oman, R. C. & Ayers, T. B. (1988). Improving Data Quality. Journal of Systems Management, 39(5), 31-35.
Page, W. & Kaomea, P. (1994). Using Quality Attributes to Produce Optimal Tactical Information. In The Fourth Workshop on Information Technologies and Systems (WITS), Vancouver, British Columbia, Canada.
Pautke, R. W. & Redman, T. C. (1990). Techniques to control and improve quality of data in large databases. In the Proceedings of Statistics Canada Symposium 90, (pp. 319-333) Canada.
Percy, T. (1993). Business Re-engineering: Does Data Quality Matter? Software Management Strategies, Gartner Group, 1.
Redman, T. C. (1992). Data Quality: Management and Technology. New York: Bantam Books.
Sheth, A. & Larson, J. (1990). Federated Database Systems for Managing Distributed, Heterogeneous, and Autonomous Databases. ACM Computing Surveys, 22(3).
Siegel, M., Sciore, E., & Rosenthal, A. (1994). Using Semantic Values to Facilitate Interoperability Among Heterogeneous Information Systems. To appear in the Transaction on Database Systems (TODS).
Storey, V. & Goldstein, R. (1993). Knowledge-Based Approaches to Database Design. Management Information Systems Quarterly (MISQ), 17(1), 25-46.
Strong, D. M. (1992). Decision Support for Exception Handling and Quality Control in Office Operations. Decision Support Systems, 9, 217-227.
Strong, D. M. & Miller, S. M. (1994). Exceptions and Exception Handling in Computerized Information Processes. To appear in the ACM Transactions on Information Systems.
Swanson, E. B. (1987). Information Channel Disposition and Use. Decision Sciences, 18, 131-145.
Tan, J. K. H. & Benbasat, I. (1990). Processing of Graphical Information: A Decomposition Taxonomy to Match Data Extraction Tasks and Graphical Representations. Information Systems Research, 1(4), 416-439.
Wand, Y. & Wang, R. Y. (1994). Anchoring Data Quality Dimensions in Ontological Foundations. Submitted for publication.
Wang, R. Y. & Kon, H. B. (1993). Towards Total Data Quality Management (TDQM). In Information Technology in Action: Trends and Perspectives. (pp. 179-197). Englewood Cliffs, NJ: Prentice Hall.
Wang, R. Y., Kon, H. B., & Madnick, S. E. (1993). Data Quality Requirements Analysis and Modeling. In the Proceedings of the 9th International Conference on Data Engineering, (pp. 670-677) Vienna: IEEE Computer Society Press.
Wang, R. Y., Reddy, M. P., & Gupta, A. (1993). An Object-Oriented Implementation of Quality Data Products. A. Hevner & N. Kamel (Ed.), In Third Annual Workshop on Information Technologies and Systems (WITS-93), (pp. 48-56) Orlando, Florida.
Wang, R. Y., Reddy, M. P., & Kon, H. B. (1992). Toward Quality Data: An Attribute-based Approach. To appear in the Journal of Decision Support Systems (DSS).
Wang, Y. R. & Madnick, S. E. (1990). A Polygen Model for Heterogeneous Database Systems: The Source Tagging Perspective. In the Proceedings of the 16th International Conference on Very Large Data bases (VLDB), (pp. 519-538) Brisbane, Australia.
Yu, S. & Neter, J. (1973). A Stochastic Model of the Internal Control System. Journal of Accounting Research, 1(3), 273-295.
Zmud, R. (1978). Concepts, Theories and Techniques: An Empirical Investigation of the Dimensionality of the Concept of Information. Decision Sciences, 9(2), 187-195.
Zmud, R., Lind, M., & Young, F. (1990). An Attribute Space for Organizational Communication Channels. Information Systems Research, 1(4), 440-457.
Position Prior to Attending the university: Finance Marketing
(Circle One) Operations Personnel
IT Other______________
Industry you worked in the previous job : ______________________
When you think of data quality, what attributes other
than timeliness, accuracy, availability, and interpretability
come to mind? Please list as many as possible!
_________________ _________________ _________________
_________________ _________________ _________________
_________________ _________________ _________________
_________________ _________________ _________________
_________________ _________________ _________________
_________________ _________________ _________________
_________________ _________________ _________________
(Side Two)
The following is a list of attributes developed for
data quality:
Completeness Flexibility Adaptability Reliability
Relevance Reputation Compatibility Ease of Use
Ease of Update Ease of Maintenance Format Cost
Integrity Breadth Depth Correctness
Well-documented Habit Variety Content
Dependability Manipulability Preciseness Redundancy
Ease of Access Convenience Accessibility Data Exchange
Understandable Credibility Importance Critical
After reviewing this list, do any other attributes come to mind?
_________________ _________________ _________________
_________________ _________________ _________________
_________________ _________________ _________________
_________________ _________________ _________________
Thank you for participating in this study. All responses will be held in strictest confidence.
Industry: _________________________ Job Title: _____________________________
Department: Finance Marketing/Sales Operations Human Resources
Accounting Information Systems Planning Other ________________
The following is a list of adjectives
and phrases which describes corporate data. When answering the
questions, please think about the internal data such as sales,
production, financial, and employee data that you work with or
use to make decisions in your job.
We apologize for the tedious nature
of the survey. Although the questions may seem repetitive, your
response to each question is critical to the success of the study.
Please give us the first response that comes to mind and try
to use the FULL scale range available.
Section I: How important is it to
you that your data are:
Extremely Not Important Important Important At All
Accurate 1 2 3 4 5 6 7 8 9
Believable 1 2 3 4 5 6 7 8 9
Complete 1 2 3 4 5 6 7 8 9
Concise 1 2 3 4 5 6 7 8 9
Verifiable 1 2 3 4 5 6 7 8 9
Well-Documented 1 2 3 4 5 6 7 8 9
Understandable 1 2 3 4 5 6 7 8 9
Well-Presented 1 2 3 4 5 6 7 8 9
Up-To-Date 1 2 3 4 5 6 7 8 9
Accessible 1 2 3 4 5 6 7 8 9
Adaptable 1 2 3 4 5 6 7 8 9
Aesthetically Pleasing 1 2 3 4 5 6 7 8 9
Compactly Represented 1 2 3 4 5 6 7 8 9
Important 1 2 3 4 5 6 7 8 9
Consistently Formatted 1 2 3 4 5 6 7 8 9
Dependable 1 2 3 4 5 6 7 8 9
Retrievable 1 2 3 4 5 6 7 8 9
Manipulable 1 2 3 4 5 6 7 8 9
Objective 1 2 3 4 5 6 7 8 9
Usable 1 2 3 4 5 6 7 8 9
Well-Organized 1 2 3 4 5 6 7 8 9
Transportable/Portable 1 2 3 4 5 6 7 8 9
Unambiguous 1 2 3 4 5 6 7 8 9
Correct 1 2 3 4 5 6 7 8 9
Section I (continued): How important
is it to you that your data are:
Extremely Not Important
Important Important At All
Relevant 1 2 3 4 5 6 7 8 9
Flexible 1 2 3 4 5 6 7 8 9
Flawless 1 2 3 4 5 6 7 8 9
Comprehensive 1 2 3 4 5 6 7 8 9
Consistently Represented 1 2 3 4 5 6 7 8 9
Interesting 1 2 3 4 5 6 7 8 9
Unbiased 1 2 3 4 5 6 7 8 9
Familiar 1 2 3 4 5 6 7 8 9
Interpretable 1 2 3 4 5 6 7 8 9
Applicable 1 2 3 4 5 6 7 8 9
Robust 1 2 3 4 5 6 7 8 9
Available 1 2 3 4 5 6 7 8 9
Revealing 1 2 3 4 5 6 7 8 9
Reviewable 1 2 3 4 5 6 7 8 9
Expandable 1 2 3 4 5 6 7 8 9
Time Independent 1 2 3 4 5 6 7 8 9
Error-Free 1 2 3 4 5 6 7 8 9
Efficient 1 2 3 4 5 6 7 8 9
User-Friendly 1 2 3 4 5 6 7 8 9
Specific 1 2 3 4 5 6 7 8 9
Well-Formatted 1 2 3 4 5 6 7 8 9
Reliable 1 2 3 4 5 6 7 8 9
Convenient 1 2 3 4 5 6 7 8 9
Extendable 1 2 3 4 5 6 7 8 9
Critical 1 2 3 4 5 6 7 8 9
Well-Defined 1 2 3 4 5 6 7 8 9
Reusable 1 2 3 4 5 6 7 8 9
Clear 1 2 3 4 5 6 7 8 9
Cost Effective 1 2 3 4 5 6 7 8 9
Auditable 1 2 3 4 5 6 7 8 9
Precise 1 2 3 4 5 6 7 8 9
Readable 1 2 3 4 5 6 7 8 9
Section II: How important is it to you that your data can be:
Extremely Not Important Important Important At All
Easily Aggregated 1 2 3 4 5 6 7 8 9
Easily Accessed 1 2 3 4 5 6 7 8 9
Easily Compared to Past Data 1 2 3 4 5 6 7 8 9
Easily Changed 1 2 3 4 5 6 7 8 9
Easily Questioned 1 2 3 4 5 6 7 8 9
Easily Downloaded/Uploaded 1 2 3 4 5 6 7 8 9
Easily Joined With Other Data 1 2 3 4 5 6 7 8 9
Easily Updated 1 2 3 4 5 6 7 8 9
Easily Understood 1 2 3 4 5 6 7 8 9
Easily Maintained 1 2 3 4 5 6 7 8 9
Easily Retrieved 1 2 3 4 5 6 7 8 9
Easily Customized 1 2 3 4 5 6 7 8 9
Easily Reproduced 1 2 3 4 5 6 7 8 9
Easily Traced 1 2 3 4 5 6 7 8 9
Easily Sorted 1 2 3 4 5 6 7 8 9
Section III: How important are the following to you?
Extremely Not Important Important Important At All
Data are certified error-free. 1 2 3 4 5 6 7 8 9
Data improves efficiency. 1 2 3 4 5 6 7 8 9
Data gives you a competitive edge. 1 2 3 4 5 6 7 8 9
Data cannot be accessed by competitors. 1 2 3 4 5 6 7 8 9
Data contains adequate detail 1 2 3 4 5 6 7 8 9
Data are in finalized form. 1 2 3 4 5 6 7 8 9
Data contains no redundancy. 1 2 3 4 5 6 7 8 9
Data are of proprietary nature 1 2 3 4 5 6 7 8 9
Data can be personalized. 1 2 3 4 5 6 7 8 9
Data are not easily corrupted. 1 2 3 4 5 6 7 8 9
Data meets all of your requirements. 1 2 3 4 5 6 7 8 9
Data adds value to your operations. 1 2 3 4 5 6 7 8 9
Data are continuously collected. 1 2 3 4 5 6 7 8 9
Data continuously presented in same format. 1 2 3 4 5 6 7 8 9
Data are compatible with previous data. 1 2 3 4 5 6 7 8 9
Data are not overwhelming. 1
2 3 4 5 6 7 8 9
Section III (Continued): How important are the following to you?
Extremely Not Important Important Important At All
Data can be easily integrated. 1 2 3 4 5 6 7 8 9
Data can be used for multiple purposes. 1 2 3 4 5 6 7 8 9
Data are secure. 1 2 3 4 5 6 7 8 9
Section IV: How important are the following to you?
Extremely Not Important Important Important At All
The source of the data is clear. 1 2 3 4 5 6 7 8 9
Errors can be easily identified. 1 2 3 4 5 6 7 8 9
The cost of data collection. 1 2 3 4 5 6 7 8 9
The cost of data accuracy. 1 2 3 4 5 6 7 8 9
The form of presentation. 1 2 3 4 5 6 7 8 9
The format of the data. 1 2 3 4 5 6 7 8 9
The scope of information contained in data. 1 2 3 4 5 6 7 8 9
The depth of information contained in data. 1 2 3 4 5 6 7 8 9
The breadth of information contained in data. 1 2 3 4 5 6 7 8 9
Quality of resolution. 1 2 3 4 5 6 7 8 9
The storage medium. 1 2 3 4 5 6 7 8 9
The reputation of the data source. 1 2 3 4 5 6 7 8 9
The reputation of the data. 1 2 3 4 5 6 7 8 9
The age of the data. 1 2 3 4 5 6 7 8 9
The amount of data. 1 2 3 4 5 6 7 8 9
You have used the data before. 1 2 3 4 5 6 7 8 9
Someone has clear responsibility for data. 1 2 3 4 5 6 7 8 9
The data entry process is self-correcting. 1 2 3 4 5 6 7 8 9
The speed of access to data. 1 2 3 4 5 6 7 8 9
The speed of operations performed on data. 1 2 3 4 5 6 7 8 9
The amount and type of storage required. 1 2 3 4 5 6 7 8 9
You have little extraneous data present. 1 2 3 4 5 6 7 8 9
You have a variety of data and data sources. 1 2 3 4 5 6 7 8 9
You have optimal data for your purpose. 1 2 3 4 5 6 7 8 9
The integrity of the data. 1 2 3 4 5 6 7 8 9
It is easy to tell if the data are updated. 1 2 3 4 5 6 7 8 9
Easy to exchange data with others. 1 2 3 4 5 6 7 8 9
Access to data can be restricted. 1 2 3 4 5 6 7 8 9
Thank you for your time and effort in completing this survey.
| Attribute | |||||
| Accurate | |||||
| Believable | |||||
| Complete | |||||
| Concise | |||||
| Verifiable | |||||
| Well-Documented | |||||
| Understandable | |||||
| Well-Presented | |||||
| Up-To-Date | |||||
| Accessible | |||||
| Adaptable | |||||
| Aesthetically Pleasing | |||||
| Compactly Represented | |||||
| Important | |||||
| Consistently Formatted | |||||
| Dependable | |||||
| Retrievable | |||||
| Manipulable | |||||
| Objective | |||||
| Usable | |||||
| Well-Organized | |||||
| Transportable/Portable | |||||
| Unambiguous | |||||
| Correct | |||||
| Relevant | |||||
| Flexible | |||||
| Flawless | |||||
| Comprehensive | |||||
| Consistently Represented | |||||
| Interesting | |||||
| Unbiased | |||||
| Familiar | |||||
| Interpretable | |||||
| Applicable | |||||
| Robust | |||||
| Available | |||||
| Revealing | |||||
| Reviewable | |||||
| Expandable | |||||
| Time Independent | |||||
| Error-Free | |||||
| Efficient | |||||
| User-Friendly | |||||
| Specific | |||||
| Well-Formatted | |||||
| Reliable | |||||
| Convenient | |||||
| Extendable | |||||
| Critical | |||||
| Well-Defined | |||||
| Reusable | |||||
| Clear | |||||
| Cost Effective | |||||
| Auditable | |||||
| Precise | |||||
| Readable | |||||
| Easily Aggregated | |||||
| Easily Accessed | |||||
| Easily Compared to Past Data | |||||
| Attribute | |||||
| Easily Changed | |||||
| Easily Questioned | |||||
| Easily Downloaded/Uploaded | |||||
| Easily Joined With Other Data | |||||
| Easily Updated | |||||
| Easily Understood | |||||
| Easily Maintained | |||||
| Easily Retrieved | |||||
| Easily Customized | |||||
| Easily Reproduced | |||||
| Easily Traced | |||||
| Easily Sorted | |||||
| Data are certified error-free. | |||||
| Data improves efficiency. | |||||
| Data gives you a competitive edge. | |||||
| Data cannot be accessed by competitors. | |||||
| Data contains adequate detail | |||||
| Data are in finalized form. | |||||
| Data contains no redundancy. | |||||
| Data are of proprietary nature | |||||
| Data can be personalized. | |||||
| Data are not easily corrupted. | |||||
| Data meets all of your requirements. | |||||
| Data adds value to your operations. | |||||
| Data are continuously collected. | |||||
| Data continuously presented in same format. | |||||
| Data are compatible with previous data. | |||||
| Data are not overwhelming. | |||||
| Data can be easily integrated. | |||||
| Data can be used for multiple purposes | |||||
| Data are secure | |||||
| The source of the data is clear | |||||
| Errors can be easily identified. | |||||
| The cost of data collection. | |||||
| The cost of data accuracy. | |||||
| The form of presentation. | |||||
| The format of the data. | |||||
| The scope of information contained in data. | |||||
| The depth of information contained in data. | |||||
| The breadth of information contained in data. | |||||
| Quality of resolution. | |||||
| The storage medium. | |||||
| The reputation of the data source. | |||||
| The reputation of the data. | |||||
| The age of the data. | |||||
| The amount of data. | |||||
| You have used the data before. | |||||
| Someone has clear responsibility for data. | |||||
| The data entry process is self-correcting. | |||||
| The speed of access to data. | |||||
| The speed of operations performed on data. | |||||
| The amount and type of storage required. | |||||
| You have little extraneous data present. | |||||
| You have a variety of data and data sources. | |||||
| You have optimal data for your purpose. | |||||
| The integrity of the data. | |||||
| It is easy to tell if the data are updated. | |||||
| Easy to exchange data with others. | |||||
| Access to data can be restricted. |
(Factor loadings < 0.3 are not shown; factor loadings < 0.5 are not retained for further analysis)
| Item | ||||||||||||||||||
| Easily Joined With Other Data | ||||||||||||||||||
| Data can be easily integrated | ||||||||||||||||||
| Easily Downloaded/Uploaded | ||||||||||||||||||
| Easily Aggregated | ||||||||||||||||||
| Easily Customized | ||||||||||||||||||
| Easily Updated | ||||||||||||||||||
| Easily Changed | ||||||||||||||||||
| Manipulable | ||||||||||||||||||
| Data can be used for multiple purposes | ||||||||||||||||||
| Easily Reproduced | ||||||||||||||||||
| Easily Accessed+2 | ||||||||||||||||||
| Easily Retrieved+2 | ||||||||||||||||||
| Data are certified error-free | ||||||||||||||||||
| Error-Free | ||||||||||||||||||
| Accurate | ||||||||||||||||||
| Correct | ||||||||||||||||||
| Flawless | ||||||||||||||||||
| Reliable | ||||||||||||||||||
| Errors can be easily identified | ||||||||||||||||||
| The integrity of the data | ||||||||||||||||||
| Precise | ||||||||||||||||||
| Well-Presented | ||||||||||||||||||
| The form of presentation | ||||||||||||||||||
| Concise | ||||||||||||||||||
| Well-Organized | ||||||||||||||||||
| The format of the data | ||||||||||||||||||
| Well-Formatted | ||||||||||||||||||
| Compactly Represented | ||||||||||||||||||
| Aesthetically Pleasing | ||||||||||||||||||
| The breadth of info. contained in data | ||||||||||||||||||
| The depth of info. contained in data | ||||||||||||||||||
| The scope of info. contained in data | ||||||||||||||||||
| The amount and type of storage required+3 | ||||||||||||||||||
| The storage medium+3 | ||||||||||||||||||
| Data cannot be accessed by competitors | ||||||||||||||||||
| Data are of proprietary nature | ||||||||||||||||||
| Access to data can be restricted | ||||||||||||||||||
| Data are secure | ||||||||||||||||||
| Retrievable | ||||||||||||||||||
| Accessible | ||||||||||||||||||
| The speed of access to data | ||||||||||||||||||
| Available | ||||||||||||||||||
| Up-To-Date | ||||||||||||||||||
| The cost of data collection | ||||||||||||||||||
| The cost of data accuracy | ||||||||||||||||||
| Cost Effective | ||||||||||||||||||
| Someone has clear responsibility for data+3 | ||||||||||||||||||
| The data entry process is self-correcting+3 | ||||||||||||||||||
| Easy to exchange data with others+3 | ||||||||||||||||||
| Well-Documented | ||||||||||||||||||
| Verifiable | ||||||||||||||||||
| Easily Traced | ||||||||||||||||||
| Data continuously presented in same format | ||||||||||||||||||
| Consistently Represented | ||||||||||||||||||
| Consistently Formatted | ||||||||||||||||||
| Data are compatible with previous data | ||||||||||||||||||
| Unbiased | ||||||||||||||||||
| Objective | ||||||||||||||||||
| Applicable | ||||||||||||||||||
| Relevant | ||||||||||||||||||
| Interesting | ||||||||||||||||||
| Usable | ||||||||||||||||||
| Item | ||||||||||||||||||
| Believable | ||||||||||||||||||
| Easily Understood | ||||||||||||||||||
| Clear | ||||||||||||||||||
| Readable | ||||||||||||||||||
| Time Independent | ||||||||||||||||||
| You have a variety of data and data sources | ||||||||||||||||||
| The amount of data | ||||||||||||||||||
| Critical | ||||||||||||||||||
| Comprehensive | ||||||||||||||||||
| Data gives you a competitive edge | ||||||||||||||||||
| Data adds value to your operations | ||||||||||||||||||
| The age of the data | ||||||||||||||||||
| Robust | ||||||||||||||||||
| Reviewable | ||||||||||||||||||
| The reputation of the data source | ||||||||||||||||||
| The reputation of the data | ||||||||||||||||||
| Interpretable | ||||||||||||||||||
| Adaptable | ||||||||||||||||||
| Flexible | ||||||||||||||||||
| Extendable | ||||||||||||||||||
| Expandable | ||||||||||||||||||
| Reusable+1 | ||||||||||||||||||
| Dependable+1 | ||||||||||||||||||
| Data can be personalized+1 | ||||||||||||||||||
| Easily Questioned+1 | ||||||||||||||||||
| Convenient+1 | ||||||||||||||||||
| Familiar+1 | ||||||||||||||||||
| Efficient+1 | ||||||||||||||||||
| Data are not easily corrupted+1 | ||||||||||||||||||
| Well-Defined+1 | ||||||||||||||||||
| Unambiguous+1 | ||||||||||||||||||
| It is easy to tell if the data are updated+1 | ||||||||||||||||||
| User-Friendly+1 | ||||||||||||||||||
| Transportable/Portable+1 | ||||||||||||||||||
| Important+1 | ||||||||||||||||||
| Data improves efficiency+1 | ||||||||||||||||||
| Quality of resolution+1 | ||||||||||||||||||
| You have used the data before+1 | ||||||||||||||||||
| The source of the data is clear+1 | ||||||||||||||||||
| Easily Compared to Past Data+1 | ||||||||||||||||||
| Data contains adequate detail+1 | ||||||||||||||||||
| Auditable+1 | ||||||||||||||||||
| Easily Maintained+1 | ||||||||||||||||||
| Complete+1 | ||||||||||||||||||
| Data are not overwhelming+1 | ||||||||||||||||||
| Understandable+1 | ||||||||||||||||||
| Specific+1 | ||||||||||||||||||
| You have optimal data for your purpose+1 | ||||||||||||||||||
| Data are in finalized form+1 | ||||||||||||||||||
| Data meets all of your requirements+1 | ||||||||||||||||||
| Data contains no redundancy+1 | ||||||||||||||||||
| You have little extraneous data present+1 | ||||||||||||||||||
| Revealing+1 | ||||||||||||||||||
| The speed of operations performed on data+1 | ||||||||||||||||||
| Easily Sorted+1 | ||||||||||||||||||
| Data are continuously collected+1 | ||||||||||||||||||
| *1 | Dimension dropped due to low importance (i.e., rating > 5) | +1 | Item dropped due to no loading > 0.5 on any dimension | |||||||||||||||
| *2 | Dimension dropped due to un-interpretability | +2 | Item dropped due to equal loading on two dimensions | |||||||||||||||
| *3 | Dimension dropped due to no item loading > 0.5 | +3 | Item dropped due to the elimination of the associated dimension | |||||||||||||||
| *4 | Dimension dropped due to having a singleton item and overlapping meaning with other dimensions | |||||||||||||||||
Appendix D: Full Factor Loadings (Continued)
(Factor loadings < 0.3 are not shown; factor loadings < 0.5 are not retained for further analysis)
| Item | |||||||||||||||||
| Easily Joined With Other Data | |||||||||||||||||
| Data can be easily integrated | |||||||||||||||||
| Easily Downloaded/Uploaded | |||||||||||||||||
| Easily Aggregated | |||||||||||||||||
| Easily Customized | |||||||||||||||||
| Easily Updated | |||||||||||||||||
| Easily Changed | |||||||||||||||||
| Manipulable | |||||||||||||||||
| Data can be used for multiple purposes | |||||||||||||||||
| Easily Reproduced | |||||||||||||||||
| Easily Accessed+2 | |||||||||||||||||
| Easily Retrieved+2 | |||||||||||||||||
| Data are certified error-free | |||||||||||||||||
| Error-Free | |||||||||||||||||
| Accurate | |||||||||||||||||
| Correct | |||||||||||||||||
| Flawless | |||||||||||||||||
| Reliable | |||||||||||||||||
| Errors can be easily identified | |||||||||||||||||
| The integrity of the data | |||||||||||||||||
| Precise | |||||||||||||||||
| Well-Presented | |||||||||||||||||
| The form of presentation | |||||||||||||||||
| Concise | |||||||||||||||||
| Well-Organized | |||||||||||||||||
| The format of the data | |||||||||||||||||
| Well-Formatted | |||||||||||||||||
| Compactly Represented | |||||||||||||||||
| Aesthetically Pleasing | |||||||||||||||||
| The breadth of info. contained in data | |||||||||||||||||
| The depth of info. contained in data | |||||||||||||||||
| The scope of info. contained in data | |||||||||||||||||
| The amount and type of storage required+3 | |||||||||||||||||
| The storage medium+3 | |||||||||||||||||
| Data cannot be accessed by competitors | |||||||||||||||||
| Data are of proprietary nature | |||||||||||||||||
| Access to data can be restricted | |||||||||||||||||
| Data are secure | |||||||||||||||||
| Retrievable | |||||||||||||||||
| Accessible | |||||||||||||||||
| The speed of access to data | |||||||||||||||||
| Available | |||||||||||||||||
| Up-To-Date | |||||||||||||||||
| The cost of data collection | |||||||||||||||||
| The cost of data accuracy | |||||||||||||||||
| Cost Effective | |||||||||||||||||
| Someone has clear responsibility for data+3 | |||||||||||||||||
| The data entry process is self-correcting+3 | |||||||||||||||||
| Easy to exchange data with others+3 | |||||||||||||||||
| Well-Documented | |||||||||||||||||
| Verifiable | |||||||||||||||||
| Easily Traced | |||||||||||||||||
| Data continuously presented in same format | |||||||||||||||||
| Consistently Represented | |||||||||||||||||
| Consistently Formatted | |||||||||||||||||
| Data are compatible with previous data | |||||||||||||||||
| Unbiased | |||||||||||||||||
| Objective | |||||||||||||||||
| Applicable | |||||||||||||||||
| Relevant | |||||||||||||||||
| Interesting | |||||||||||||||||
| Usable | |||||||||||||||||
| Believable | |||||||||||||||||
| Easily Understood | |||||||||||||||||
| Clear | |||||||||||||||||
| Readable | |||||||||||||||||
| Time Independent | |||||||||||||||||
| You have a variety of data and data sources | |||||||||||||||||
| The amount of data | |||||||||||||||||
| Critical | |||||||||||||||||
| Comprehensive | |||||||||||||||||
| Data gives you a competitive edge | |||||||||||||||||
| Data adds value to your operations | |||||||||||||||||
| The age of the data | |||||||||||||||||
| Robust | |||||||||||||||||
| Reviewable | |||||||||||||||||
| The reputation of the data source | |||||||||||||||||
| The reputation of the data | |||||||||||||||||
| Interpretable | |||||||||||||||||
| Adaptable | |||||||||||||||||
| Flexible | |||||||||||||||||
| Extendable | |||||||||||||||||
| Expandable | |||||||||||||||||
| Reusable+1 | |||||||||||||||||
| Dependable+1 | |||||||||||||||||
| Data can be personalized+1 | |||||||||||||||||
| Easily Questioned+1 | |||||||||||||||||
| Convenient+1 | |||||||||||||||||
| Familiar+1 | |||||||||||||||||
| Efficient+1 | |||||||||||||||||
| Data are not easily corrupted+1 | |||||||||||||||||
| Well-Defined+1 | |||||||||||||||||
| Unambiguous+1 | |||||||||||||||||
| It is easy to tell if the data are updated+1 | |||||||||||||||||
| User-Friendly+1 | |||||||||||||||||
| Transportable/Portable+1 | |||||||||||||||||
| Important+1 | |||||||||||||||||
| Data improves efficiency+1 | |||||||||||||||||
| Quality of resolution+1 | |||||||||||||||||
| You have used the data before+1 | |||||||||||||||||
| The source of the data is clear+1 | |||||||||||||||||
| Easily Compared to Past Data+1 | |||||||||||||||||
| Data contains adequate detail+1 | |||||||||||||||||
| Auditable+1 | |||||||||||||||||
| Easily Maintained+1 | |||||||||||||||||
| Complete+1 | |||||||||||||||||
| Data are not overwhelming+1 | |||||||||||||||||
| Understandable+1 | |||||||||||||||||
| Specific+1 | |||||||||||||||||
| You have optimal data for your purpose+1 | |||||||||||||||||
| Data are in finalized form+1 | |||||||||||||||||
| Data meets all of your requirements+1 | |||||||||||||||||
| Data contains no redundancy+1 | |||||||||||||||||
| You have little extraneous data present+1 | |||||||||||||||||
| Revealing+1 | |||||||||||||||||
| The speed of operations performed on data+1 | |||||||||||||||||
| Easily Sorted+1 | |||||||||||||||||
| Data are continuously collected+1 | |||||||||||||||||
| *1 | Dimension dropped due to low importance (i.e., rating > 5) | +1 | Item dropped due to no loading > 0.5 on any dimension | ||||||||||||||
| *2 | Dimension dropped due to un-interpretability | +2 | Item dropped due to equal loading on two dimensions | ||||||||||||||
| *3 | Dimension dropped due to no item loading > 0.5 | +3 | Item dropped due to the elimination of the associated dimension | ||||||||||||||
| *4 | Dimension dropped due to having a singleton item and overlapping meaning with other dimensions | ||||||||||||||||
We now discuss these twenty dimensions in more detail in order of their importance as dictated by their corresponding dimensional means (which is the order of Table 4). In this discussion, we describe the statistical properties of the dimensions and interpret the dimensions in terms of their importance and their possible relationships to other dimensions and to previous literature.
1. Believability This dimension was represented by a single item. This dimension had a 95% confidence interval which excluded 3, thus we can say that the mean is statistically less than 3. We cannot, however, conclude that believability is the most important dimension, since its confidence interval overlapped with the next three dimensions. Believable had a component loading of .76 on this dimension as shown in Table 3, and near zero loadings on the remaining dimensions. No other items loaded clearly on this dimension. Thus, it is arguable that believability stands on its own and can be interpreted solely by the meaning of the word itself.
2. Value-added This dimension consists of two items: data give you a competitive edge and data add value to your operations. It addresses the benefits that the consumer obtains from the data. As the items in this dimension suggest, the overall value of the data is very important to data consumers. While the mean for this dimension is not statistically less than 3, value-added is also one of the most important data quality dimensions since it has a relatively high mean.
3. Relevancy The four items listed in Table 4 (applicable, relevant, interesting, and usable) loaded on this dimension. Thus, this dimension, similar to value-added, deals with whether the data consumer feels that the data are applicable and helpful to the problem or situation at hand. However, value-added is value oriented whereas relevancy is task oriented, as their corresponding items suggest.
4. Accuracy This dimension confirms the existence of the dimension accuracy. All of the items clearly loaded on this dimension since they had near zero loadings on all other components. The particular grouping of these items shows that the concepts of accuracy and error knowledge are closely intertwined. That is, the existence of items such as errors can be easily identified and data are certified error free combined with items such as accurate and correct reinforces the point that data consumers need confirmation that the data are indeed accurate.
The mean of this dimension was also relatively high, and was not statistically different from either of the means for believability, valuable, and relevancy. Thus these four dimensions can all be considered to be the most important to data consumers.
5. Interpretability This dimension also contained a single item which clearly loaded only on it with a value of .64.
6. Ease of Understanding Easily Understood loaded higher on this dimension than clear or readable. The loadings were .70, .65, and .56 respectively, but all three had low loadings on all other dimensions. These items reinforce the interpretation of this dimension as ease of understanding instead of simply understandability. It appears that understandable as defined by these items may have less to do with an in-depth understanding of the data, and more to do with a first glance or more cursory inspection of the data.
7. Accessibility This dimension was less concrete than the previous ones, mainly due to the loading of up-to-date on the dimension. It should be noted, however, that up-to-date had the smallest loading, .56, and had a few relatively high loadings on other dimensions, thus making its association with this dimension less concrete. We chose to interpret this dimension as the accessibility of the data to the data consumer. The dimensional mean of accessibility is statistically higher than 3. Thus, it did not rank in the extreme end of importance to data consumers. However, it is still relatively high both on the dimension list and in terms of its mean.
8. Objectivity No items, other than unbiased and objective, loaded on this dimension. The mean was statistically smaller than 4, but also greater than 3. From these results, objectivity was fairly important to data consumers.
9. Timeliness This dimension was also a single item dimension, with a relatively low loading value of .58. The only second tier item which clearly loaded on this dimension was "it is easy to tell if the data are updated", with a loading of .42. We name this dimension as timeliness because the second-tier item can be interpreted as currency or up-to-dateness which support the choice of this name.
10. Completeness We chose to name this dimension completeness because the three phrases were related to the importance of the overall content of the data as the consumer sees it.
11. Traceability We chose to name the dimension traceability since it deals with whether the data trail can be traced, followed, or verified by data consumers.
12. Reputation This dimension evidently concerns the trust or regard the data consumer has in the actual data source and data content. Both phrases loaded highly on this dimension, with near zero loadings on all other dimensions. No other items loaded clearly on the reputation dimension. This dimension may represent a way to easily assure data consumers of the trustworthiness of the data, and hence increase perceived data quality, without expensive or extensive overhauls of current Information Systems.
13. Representational Consistency Consistency of the format or representation is a construct that consumers use to think about or evaluate quality data. Consistency has possibly two benefits: (1) the data are compatible with previous data and (2) the data and their formats are familiar. In addition, this dimension had a mean statistically less than 5; thus it is relatively important to data consumers.
14. Cost Effectiveness This dimension is the only dimension that addresses the cost aspect of data quality. Further support for this dimension is found by looking at the mean of 4.246, whose 95 percent confidence interval had a low end statistically less than 5. In looking at the component loadings, cost of collection (.83), cost of accuracy (.78), and cost effectiveness (.71), we see that they were rather high, and each item had near zero loadings on all other dimensions. Again this supports cost effectiveness as being a unique dimension.
15. Ease of Operation Many of the items associated with ease "loaded" on a single dimension which we named ease of operation. However, this dimension is not just a result of the position in the questionnaire or expression of the items. This is because those items which did not relate to the manipulability of the data per se, did not load on this dimension, even though they appeared in the same section. In addition, manipulable and multiple purposes both did load on this dimension. Ease of operation highlights the operational data quality issues. The mean of this dimension is statistically less than 5 which indicates that it is an important dimension in the eyes of the data consumer.
16. Variety of Data and Data Sources Variety of Data & Data Sources is also an isolated item, which has low loadings on all other dimensions. Thus this dimension represents the existence of a choice of data sources available to data consumers.
17. Concise The items that loaded high on this dimension deal with the cursory inspection of the data. The items reinforce the interpretation of this dimension as concise and not merely the presentability of the data.
18. Access Security All of the items loaded high on this dimension while loading low on the other dimensions. Since they all were in relation to security of the system/applications from others, it became obvious to name it access security. This also reinforces the claim that data quality is more than just the content of the data itself. Data quality includes how one interacts with the systems and applications.
19. Appropriate Amount of Data Amount of data was another dimension represented by a single item, yet the loading was very high on this dimension (.75), and the item had near zero loadings on all other dimensions. This can be interpreted as a desire for the appropriate amount of data to effectively address the data consumer's needs. This represents conciseness, not in presentation form, but in actual data content. It is interesting to note, however, that the mean of this dimension was statistically less important than that of concise.
20. Flexibility This dimension has a 95% confidence interval which excludes 5. It is on the low end of importance of the dimensions presented. Based on the items (Table 4), the dimension was named flexibility.
Instruction 1
Group the 20 data quality dimensions into several
categories (between 3 and 5) where the dimensions within each
category, in your opinion, represent similar attributes of high-quality
data. (Note: A data quality dimension may also be isolated into
its own category, if you see fit to do so.)
Example 3 X 5 Card
(1)
Content of the remaining nineteen 3 X 5 dimension cards
(2) VALUE-ADDED: The extent to which data are beneficial and provide advantages from their use.
(3) RELEVANCY: The extent to which data are applicable and helpful for the task at hand.
(4) ACCURACY: The extent to which data are correct, reliable, and certified free of error.
(5) INTERPRETABILITY: The extent to which data are in appropriate language and units, and the data definitions are clear.
(6) EASE OF UNDERSTANDING: The extent to which data are clear, without ambiguity, and easily comprehended.
(7) ACCESSIBILITY: The extent to which data are available or easily and quickly retrievable.
(8) OBJECTIVITY: The extent to which data are unbiased (unprejudiced) and impartial.
(9) TIMELINESS: The extent to which the age of the data is appropriate for the task at hand.
(10) COMPLETENESS: The extent to which data are of sufficient breadth, depth, and scope for the task at hand.
(11) TRACEABILITY: The extent to which data are well-documented, verifiable, and easily attributed to a source.
(12) REPUTATION: The extent to which data are trusted or highly regarded in terms of their source or content.
(13) REPRESENTATIONAL CONSISTENCY: The extent to which data are always presented in the same format and are compatible with previous data.
(14) COST EFFECTIVENESS: The extent to which the cost of collecting appropriate data is reasonable.
(15) EASE OF OPERATION: The extent to which data are easily managed and manipulated (i.e., updated, moved, aggregated, reproduced, customized).
(16) VARIETY OF DATA & DATA SOURCES: The extent to which data are available from several, differing data sources.
(17) CONCISE: The extent to which data are compactly represented without being overwhelming (i.e., brief in presentation, yet complete and to the point).
(18) ACCESS SECURITY: The extent to which access to data can be restricted, and hence, kept secure.
(19) APPROPRIATE AMOUNT OF DATA: The extent to which the quantity or volume of available data is appropriate.
(20) FLEXIBILITY: The
extent to which data are expandable, adaptable, and easily applied
to other needs.
Instruction 2
Label the categories that you have created with an overall definition (word or two/three word phrase) that best describes/summarizes the data quality dimensions within each category
Instruction
Group each of the data quality dimensions into one
of the following four categories. In case of conflict, choose
the best fitting category for the dimension. All dimensions must
be categorized.
Content of the four 3 X 5 category cards
Category 1:
The extent to which data values are in
conformance with the actual or true values.
Category 2:
The extent to which data are applicable
to, or pertain to, the task of the data user.
Category 3:
The extent to which data are presented
in an intelligible and clear manner.
Category 4:
The extent to which data are available
or obtainable.