Chairman Smith, members of the subcommittee, thank you for the honor of testifying before you today on the exciting new fields of molecular and quantum computing. This hearing is both appropriate and timely, for these ideas, which have been incubating in the minds of isolated researchers from many different fields for a generation, have now reached the take-off point at which a diverse community of scientists nucleates around a common vision, prepared to devote their careers to it. Within the lifetime of many in this room, these emerging fields will bring forth new ways to store, transmit, search for and even understand information. The benefits to society that follow could equal or exceed what we are learning to expect from the Internet!
I will begin with a few words about the impact which computers have already had on how Science is done. I will then explain briefly what computers (as we now know them) cannot do. This leads naturally into the subject of quantum computers, which are the first machines to be conceived in a long time that can potentially do something really different. It has nevertheless proven extremely challenging to build any sort of a quantum mechanical device that can be reliably and precisely controlled, let alone a quantum computer. My testimony will therefore focus on how, in just the last few years, we’ve begun to use molecular parallelism to help us observe and control the quantum behavior of the atomic nuclei of molecules in ordinary liquids.
 Although computers are now a part of our daily lives, they were initially used mainly to solve scientific problems. They did not employ, and by themselves did not reveal, any new scientific principles, either quantum (the very small) or relativistic (the very large). Instead, they have enabled us to begin to explore what I call the third Frontier of Science: complexity. While Isaac Newton was able to explain how the Earth orbits the Sun, neither he nor anyone since has been able to predict exactly what happens when the Moon is thrown in, even though all are governed by the Law of Gravity. You can imagine then how much worse it gets when, as in Biology and Chemistry, about 100,000,000,000,000,000,000 particles are thrown together, all interacting by many different, and far more complicated, forces.
Although computers are now a part of our daily lives, they were initially used mainly to solve scientific problems. They did not employ, and by themselves did not reveal, any new scientific principles, either quantum (the very small) or relativistic (the very large). Instead, they have enabled us to begin to explore what I call the third Frontier of Science: complexity. While Isaac Newton was able to explain how the Earth orbits the Sun, neither he nor anyone since has been able to predict exactly what happens when the Moon is thrown in, even though all are governed by the Law of Gravity. You can imagine then how much worse it gets when, as in Biology and Chemistry, about 100,000,000,000,000,000,000 particles are thrown together, all interacting by many different, and far more complicated, forces.
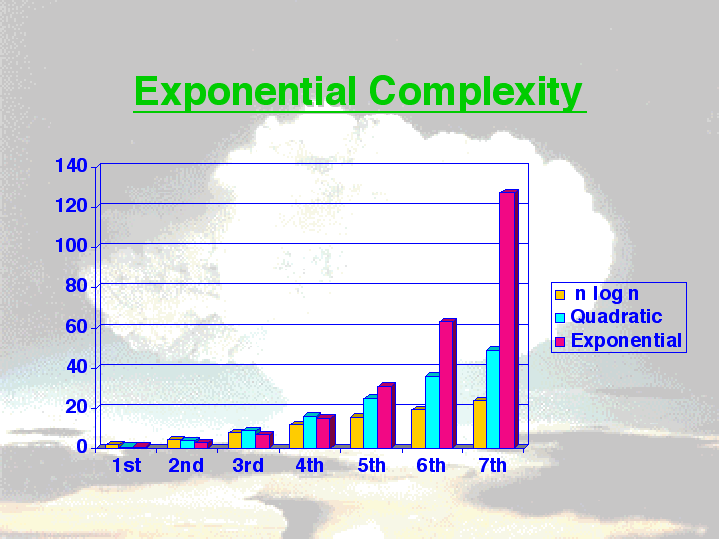 What computers have enabled us to do is to simulate representative systems with up to about a million particles in them, and thereby take the first tentative steps towards developing general methods of dealing with complex systems. They have also enabled us to track and analyze the vast quantities of data needed to characterize them. This has been particularly important in dealing with biological and quantum systems, which are among the most complex in existence. Consider for example how much good the Human Genome Project would do us, if we did not have computers to analyze all that data, or where Quantum Chemistry would be without computers to solve its massive systems of equations. But despite these great advances, there are many things computers have not, and cannot, help us with very much. These are problems that require amounts of computer time which grow exponentially with their complexity.
What computers have enabled us to do is to simulate representative systems with up to about a million particles in them, and thereby take the first tentative steps towards developing general methods of dealing with complex systems. They have also enabled us to track and analyze the vast quantities of data needed to characterize them. This has been particularly important in dealing with biological and quantum systems, which are among the most complex in existence. Consider for example how much good the Human Genome Project would do us, if we did not have computers to analyze all that data, or where Quantum Chemistry would be without computers to solve its massive systems of equations. But despite these great advances, there are many things computers have not, and cannot, help us with very much. These are problems that require amounts of computer time which grow exponentially with their complexity.
The most spectacular example of exponential growth is unfortunately well-known to us all: the atomic bomb. True exponential growth is a mathematical abstraction, which cannot exist in reality (or at least, not for long). Moreover, since 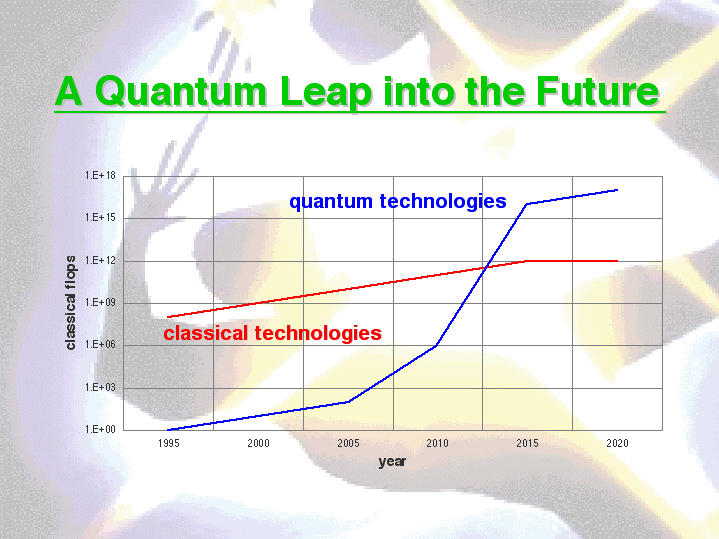 any computer can be programmed to simulate any other (e.g. Soft-PC running on a Mac), it was widely assumed that the exponential complexity of a class of problems must be independent of the computer used to solve them. Thus a single computer that can deal effectively with exponential complexity simply does not exist. The amazing thing, first noted by Gordon Moore of Intel, is that over the last thirty years computers have also been getting exponentially faster. This has enabled us to make steady progress in dealing with complexity --- progress we know cannot be sustained!
any computer can be programmed to simulate any other (e.g. Soft-PC running on a Mac), it was widely assumed that the exponential complexity of a class of problems must be independent of the computer used to solve them. Thus a single computer that can deal effectively with exponential complexity simply does not exist. The amazing thing, first noted by Gordon Moore of Intel, is that over the last thirty years computers have also been getting exponentially faster. This has enabled us to make steady progress in dealing with complexity --- progress we know cannot be sustained!
This progress has been achieved, in large part, through steady decreases in the size of computer circuitry. As things are now going, these circuits will reach atomic dimensions within the next 10 — 15 years, at which point dealing with quantum mechanics becomes simply inevitable. It is well-known that the amount of real time needed to simulate quantum mechanical systems (for a fixed amount of simulated time) grows exponentially with the number of particles in them. Thus such simulations are an archetypical example of exponential complexity. In 1982, Richard Feynman of CalTech predicted that a suitable quantum mechanical system could be manipulated to behave just like any other with a smaller or equal number of particles in it, and that moreover this could be done in subexponential time. In 1993, Seth Lloyd of MIT showed that a quantum computer, although originally conceived as a digital machine by Benioff, Deutsch and Bennett (who is with us today), could also be used as just such a universal quantum simulator.
Over the next few years, several spectacular theoretical advances were made in the field, including the discovery of a quantum algorithm for the exponential problem of integer factorization (on which modern public key cryptography depends), and quantum error correction (which in principle allows the arbitrarily precise control of quantum systems). Both of these achievements, although in retrospect compatible with existing scientific knowledge, profoundly shook many researcher’s beliefs concerning what is and is not physically possible.
Comparable progress on the all-important task of actually building quantum information processors has come rather more slowly, although many ingenious proposals for how it might be done have been put forward, including:

- polarized photons controlled by optical networks
- ion traps holding linear arrays of single atoms
(see figure from Wineland & Monroe at NIST right)
- optical lattices, i.e. optically confined neutral atoms
- quantum dots containing single unpaired electrons
- semiconductors, using both electron and nuclear spins
- superconductors, using both electric and magnetic quanta
- nuclear magnetic resonance on ensembles of molecules
One or more, or perhaps even some combination, of these ideas is likely to bear fruit in due course, but it is impossible for me to even begin to describe them in the space available here. For this reason, I will simply take the last item on this list, in which I personally have been deeply involved, as an example --- which will be shown to also illustrate certain features of molecular computing.
 Nuclear Magnetic Resonance, or NMR, is widely used by chemists to determine the structures of molecules based on the interactions of their atomic nuclei with the electrons in chemical bonds. Each such nucleus can be thought of as a tiny bar magnet. When a sample of identical molecules is placed in a strong magnet (which is shown on the left), quantum mechanics ensures that their nuclei align with the field, pointing either north (N) or south (S). In this sense they behave much like the bits in an ordinary PC, with N = 0 and S = 1, but in fact they are quantum bits, or qubits, that can change from N to S in mysterious ways!
Nuclear Magnetic Resonance, or NMR, is widely used by chemists to determine the structures of molecules based on the interactions of their atomic nuclei with the electrons in chemical bonds. Each such nucleus can be thought of as a tiny bar magnet. When a sample of identical molecules is placed in a strong magnet (which is shown on the left), quantum mechanics ensures that their nuclei align with the field, pointing either north (N) or south (S). In this sense they behave much like the bits in an ordinary PC, with N = 0 and S = 1, but in fact they are quantum bits, or qubits, that can change from N to S in mysterious ways!
When excited by radio-waves, the nuclei vibrate and re-emit new radio-waves at distinct frequencies. This enables each chemically distinct kind of nucleus in all the identical molecules present to be individually addressed, observed and flipped N <---> S. It is even possible to flip one nucleus only if another in the same molecule is S (or N), thereby obtaining the quantum equivalent of the well-known "if --- then" computer program command. The reason no one seriously considered using NMR for quantum computation is that one generally has very little control over which nuclei are N or S. That is, it is very difficult (although possible in principle) to set the bits in such a "computer" to be all zeros (i.e. N’s), so that one knows what the computation is starting with.
This is because the chaotic motions of molecules at ordinary temperatures ensure that the orientations of the nuclei at any point in time are nearly random: on average, there is only about one part in a million more N than S nuclei present in the sample. Nevertheless, when added up over the millions of millions of millions of molecules in the sample, the total magnetism of the nuclei generates a signal that can be detected fairly easily. This (very limited) form of molecular parallelism not only amplifies the signal, it also filters out the noise due to the occasional random flips of the nuclei and our imperfect control over them.
Imperfect though it may be, the control that NMR provides over the quantum states of the nuclei is sufficient for quantum information processing of substantial complexity. Among other things, it allows us to randomly flip the nuclei in every molecule of the sample whose nuclei are not all N’s. This puts the sample in a pseudo-pure state, in which the radio signals from all molecules whose nuclei are not all N’s cancel (sum to zero), so that only molecules that are can be seen. A sample in a such pseudo-pure state is suitable for computation, and in principle permits arbitrary quantum operations to be carried out on up to about 10 qubits (or more, if certain extensions of the basic ideas pan out!).
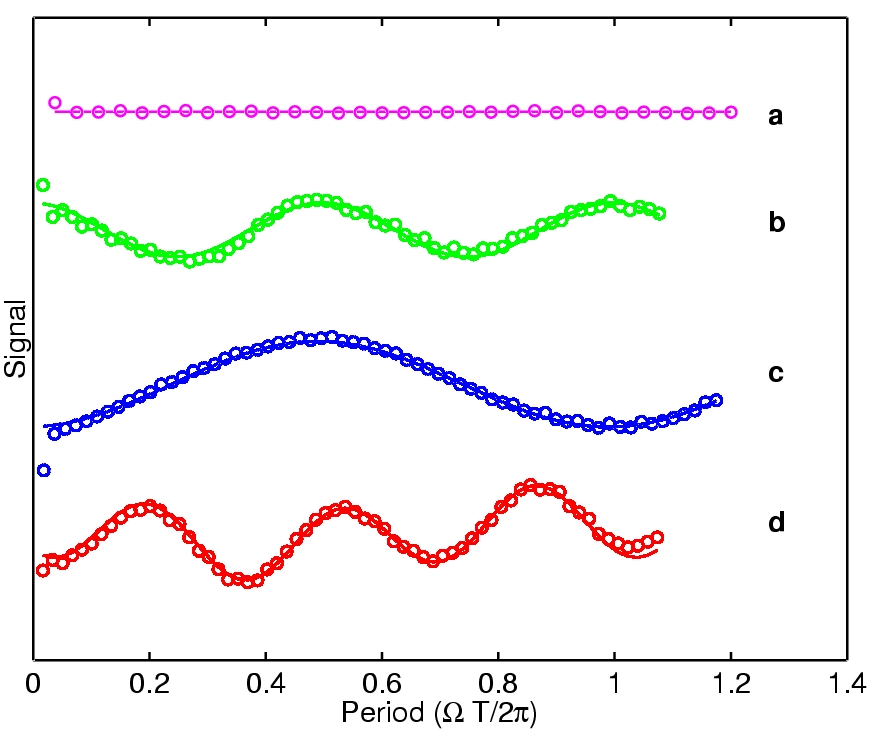 NMR spectroscopy has now enabled the experimental verification of all the basic concepts of quantum information processing, including communication, algorithms and error correction, on up to seven qubits to date. It has also enabled us to validate, for the first time, Feynman’s vision of quantum simulation. The accompanying plots (right) show the vibrations that were observed when two nuclei in a molecule were "fooled" into thinking they were a pair of quantum particles connected by a spring that was stretched, then released. Modest though these NMR prototypes may be, they constitute an excellent start at doing something which some had feared would be impossible only a few years ago, and we are now confident that increasingly more powerful prototypes will be built, both by NMR and by other technologies. It will, nonetheless, be some time before you can buy a quantum laptop!
NMR spectroscopy has now enabled the experimental verification of all the basic concepts of quantum information processing, including communication, algorithms and error correction, on up to seven qubits to date. It has also enabled us to validate, for the first time, Feynman’s vision of quantum simulation. The accompanying plots (right) show the vibrations that were observed when two nuclei in a molecule were "fooled" into thinking they were a pair of quantum particles connected by a spring that was stretched, then released. Modest though these NMR prototypes may be, they constitute an excellent start at doing something which some had feared would be impossible only a few years ago, and we are now confident that increasingly more powerful prototypes will be built, both by NMR and by other technologies. It will, nonetheless, be some time before you can buy a quantum laptop!
 I would like to close my discussion of NMR by considering what it has taught us about the relations between quantum and molecular computing. It should be understood that NMR uses molecular parallelism in only a very limited way (in computer science jargon, one would say it uses Single Instruction / Multiple Data parallelism, rather than Multiple Instruction / Multiple Data as in DNA computing), and moreover, NMR can not use the Polymerase Chain Reaction of DNA computing to selectively amplify single molecule events to the macroscopic level.
I would like to close my discussion of NMR by considering what it has taught us about the relations between quantum and molecular computing. It should be understood that NMR uses molecular parallelism in only a very limited way (in computer science jargon, one would say it uses Single Instruction / Multiple Data parallelism, rather than Multiple Instruction / Multiple Data as in DNA computing), and moreover, NMR can not use the Polymerase Chain Reaction of DNA computing to selectively amplify single molecule events to the macroscopic level.
(As an example of NMR in applied to biological systems, the figure (left) shows a 2-D NMR spectrum for a protein, PTI, which was simulated from its structure by the author.)
At the same time, NMR is not intrinsically limited to problems in which the number of molecules present equals or exceeds the number of possible solutions that must be examined, as molecular computing is. This is because NMR computations take place within the individual molecules, where it is possible to use quantum interference as a form of PCR that can (in problems for which good quantum algorithms are available) amplify the signal due to the desired solution no matter how many other possibilities there may be.
This is what enables quantum computers to break exponential barriers, which molecular computers that do not avail themselves of quantum mechanics simply cannot do. The very large, albeit nonexponential, speedups that are available from molecular computing are nonetheless potentially quite significant, and NMR computing shows conclusively that there are ways to combine the two. As time goes on, I believe that these two fields will find that they have much in common.
 The most important conclusion I would like my audience to take from my testimony is that molecular and quantum computing involve considerably more than just moving beyond the use of silicon in computers. (In fact, silicon is likely to be an important component of quantum and/or molecular computers in the future.) Instead, they are about developing entirely new computer architectures and even paradigms for computation, which lead to machines that differ from today’s computers not merely in degree, but fundamentally in kind. Above all else, they should not be mistaken for a form of nanotechnology that is used to build yet smaller and faster computers like those we now have (although they may, of course, benefit from and contribute to advances in nanotechnology).
The most important conclusion I would like my audience to take from my testimony is that molecular and quantum computing involve considerably more than just moving beyond the use of silicon in computers. (In fact, silicon is likely to be an important component of quantum and/or molecular computers in the future.) Instead, they are about developing entirely new computer architectures and even paradigms for computation, which lead to machines that differ from today’s computers not merely in degree, but fundamentally in kind. Above all else, they should not be mistaken for a form of nanotechnology that is used to build yet smaller and faster computers like those we now have (although they may, of course, benefit from and contribute to advances in nanotechnology).
Because molecular and quantum computers, as currently conceived, have built into them a great deal of information about (bio)chemistry and quantum physics, respectively, I would anticipate that the first applications of these emerging technologies will be to building special purpose devices for solving biological and quantum mechanical problems, respectively. Indeed, one can look at Eigen and Schuster’s "test-tube evolution" experiments, or Cory and Zhang’s recent "spin diffusion" experiments, as just such special purpose computations. In the long run, I think these novel computational paradigms will serve to advance the natural sciences every bit as much as the natural sciences will serve to advance the state of the art in computer science.
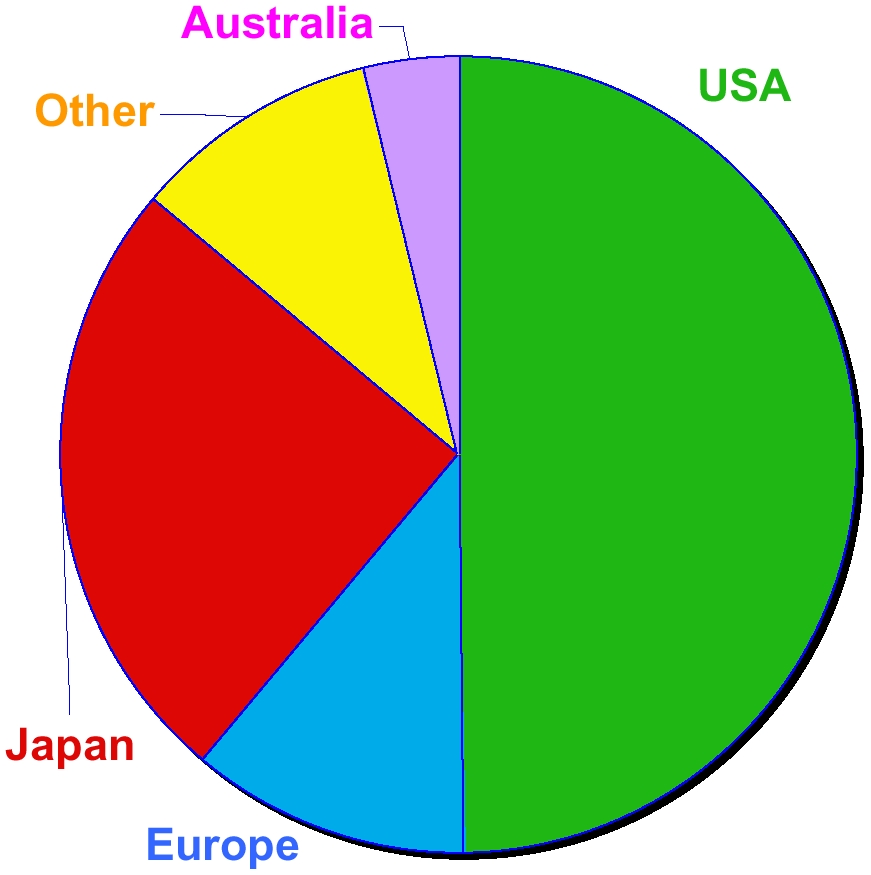 For the information of the committee, I include here a chart showing the amounts of funding (in millions of USD) currently available for research in quantum information processing by region; also, as Exhibit’s A and B, I attach the PowerPoint presentations given by Dr. Henry Everitt of the ARO, and Dr. Lerwen Liu of the Asian Technology Information Program, at the ARDA Quantum Computing Symposium held in Baltimore on August 28, 2000. These cover the US and International efforts in quantum information processing, respectively. The US efforts are funded by the ARO, ONR, AFOSR, BMDO, DARPA, NSA, CIA, NRO, ADRA, DOE, NIST, NASA and the NSF. The are tightly coordinated by the Quantum Information Science Coordination Group, chaired by Dr. Everitt, which meets twice yearly to ensure that the funds spent by these diverse agencies support one another, and are distributed in an equitable and efficient manner, with minimum overlap.
For the information of the committee, I include here a chart showing the amounts of funding (in millions of USD) currently available for research in quantum information processing by region; also, as Exhibit’s A and B, I attach the PowerPoint presentations given by Dr. Henry Everitt of the ARO, and Dr. Lerwen Liu of the Asian Technology Information Program, at the ARDA Quantum Computing Symposium held in Baltimore on August 28, 2000. These cover the US and International efforts in quantum information processing, respectively. The US efforts are funded by the ARO, ONR, AFOSR, BMDO, DARPA, NSA, CIA, NRO, ADRA, DOE, NIST, NASA and the NSF. The are tightly coordinated by the Quantum Information Science Coordination Group, chaired by Dr. Everitt, which meets twice yearly to ensure that the funds spent by these diverse agencies support one another, and are distributed in an equitable and efficient manner, with minimum overlap.