
SECTION 3 - Assumptions and Foundation
This section concerns the Thesis foundations through the literature review and discussion of the bodies of knowledge it builds upon, and includes the chapters:
1. Assumptions
2. Public Participation Review
3. Information Technology Review
|
1. Thesis Introduction 2. Hypothesis and Method 3. Assumptions and Foundation 4. Designing an Experiment |
5. The Experiment 6. Discussing the Experiment 7. The Qualitative Jump 8. Thesis Conclusions |
3.1. Assumptions
To build upon and test my hypothesis, it is important to review the state-of-the-art for both the public participation and information technology domains (body of knowledge, current research and approaches, available technology, role of information systems in decision making), through literature review and experimentation with technology.
In particular, this review and experimentation provides the foundation for the few assumptions in the formulation of the hypothesis and the choice of methodology, what I called "argued assumptions":
A-1) Is better public participation consequential to better decision making ?
In planning, public participation (PP) is not viewed as an abstraction, some kind of philosophical object or ethical purpose in itself, but rather a component of a planning process, usually a decision-making process. When I propose to test whether (and how) the introduction of new IT in public participation will improve public participation, from a planner's point of view, I am therefore assuming that public participation is, at least in general, an essential part of the decision making (affecting the same public) and that improving one improves the other in some significant way.
In order to provide a reasonable foundation to this argument, I use comprehensive literature survey, discussing several models of public participation and its assigned or expected role, using analytical reasoning to argue in favor of the models that emphasize public participation in decision-making (costs of non-participation, incremental gains model). I also consider the decision-making border cases, when it is questionable the positive role of public participation, to better set the limits of this assumption ("PP Review" chapter).
A-2) Is there such a thing as "commonly used" decision-making procedures within democracies, at least in some specific domain, good enough to constitute a meaningful working basis?
A Thesis in Planning must contribute to extend the domain's theory, in such a way that planners can extract something useful from it for their practice. There is not much use for something that only applies to a single, extraordinary event, in esoteric circumstances, non-replicable in any part or facet, with conclusions that bring no insight for anything else.
It follows that my hypothesis assumes that there is a testing ground where research conclusions can apply, at least in some extent, to at least a whole class of processes in related situations.
In order to provide a reasonable foundation to this assumption, I set the boundaries of my thesis experiment to a specific domain, such as decision making in Environmental Impact Assessment (EIA) Reviews, where at least in European Union (EU) and the USA it clearly is possible to identify a set of "commonly used" procedures, including in what concerns mandatory public participation, notwithstanding obvious differences in detail. That boundary is also consistent with the choice of case study (EIA review for the Urban Solid Waste Incinerator in S. João da Talha).
Selecting EIA processes has the added advantage of consistency with the previous assumption, since it is already institutionally recognized in many countries the importance of public participation in the EIA review process; therefore we are far from the mentioned border cases where the merit of this participation is questionable.
For that purpose, I review briefly the general decision-making model for EIA according to EU directives (Chapter "The Experiment"), and the set of common tools/techniques used in public participation, both in EU and USA ("PP Review" chapter).
A-3) Is the use of information systems a useful component of decision-making?
Finally, when I propose to focus my experiment on whether (and how) the introduction of new IT in public participation (PP) will improve public participation, as well as assume that PP is critical for better decision-making, I am therefore also assuming that planning information systems (e.g. decision support systems), are an important factor in decision-making, at least in EIA reviews.
While this is the most widely accepted assumption (nowadays, not so much years ago), it is nevertheless important to a establish a reasonable foundation through the identification of the new information technologies considered in this thesis, together with a brief review and discussion of the different information systems used in planning and their role in decision-making ("IT review" chapter). This provides also the foundation for the choice of IT used for the thesis experiment - Intelligent Multimedia and Internet.
3.2. Public Participation Review
Introduction; Objectives of public participation in decision-making; Critique of public participation; Techniques of public participation; The privileged status of public participation in EIA
3
.2.1. IntroductionWhy is public participation important in planning? While it became more or less "politically correct" to assume the goodness and relevance of public participation for decision making in modern democracy, a researcher cannot indulge in "PC" trends and evade the question.
In my view, one of the major factors that emphasize the role of public participation is the political nature of most decisions. Even decisions on supposedly strictly technical options are very often not made solely on the basis of rational and objective analysis of technical data, multicriteria equations, etc. They are frequently the result of political expediency, a matter of political timing and circumstances, a bargain element in the negotiation of other goods and agreements, a market opportunity, a rapport of forces between vested interests, etc. In such cases, one of the last elements (if not the sole) bringing some balance into the decision process, to avoid decisions that will harm community interests (the "common good" concept) is the active participation of the community itself in the planning process.
Decision making processes on technical matters are therefore interesting scenarios to study the public participation phenomenon. In particular they raise inevitably the issue of the role of the expert. Usually seen as the basis for an independent, objective, interest-neuter, rational planning by some, and as the voice of the interests that hire them by other, experts are nevertheless at the center of the decision process, because expertise and technical knowledge is required, and because expertise will be called to defend each side. So the question of public participation becomes in great measure the question of how can a "lay" public give a meaningful, valid input, with real weight in a final decision that is based on technical arguments and evidence? This brings the corresponding question on the importance of new IT: can IT contribute in a significant way to "level the field", decrease the gap between lay citizens and experts, and thus facilitate a more informed and knowledgeable input from lay citizens?
Finally, it is interesting in itself to ask why it became more and more "politically correct" to laud public participation (PP) in today's society. If nothing else, it is an indication of a trend that makes it hard to dismiss public involvement in decision processes, and shifts the gravity center of decision making (DM) research questions from the kind "should we have PP in DM?" to "how should PP be handled in DM?".
Naturally, there are many views on the objectives and role of public participation. In this chapter I briefly review and discuss the state-of-the-art of the research in this domain, particularly by the time of the thesis experiment. The discussion on current trends towards public participation and its relationship with IT developments, is left for subsequent chapters.
3.2.2. Objectives of public participation in decision-making
To assess the impact of a technology in public participation in decision-making, it is crucial to identify what is the rationale for this public participation.
Philip Selznick identifies two views: administrative and substantive participation. "Administrative participation" tries to transform the citizen into a reliable instrument for the achievement of administrative goals. "Substantive participation" tries to provide citizens with an actual role in the determination of policy. While I agree with Selznick that there are radically different agendas behind different ways to promote public participation, and that understanding these agendas are essential to understand the tactics and techniques adopted for public participation, I think that this formulation of dual views tends itself to weaken the argument, because it is reasonable to expect circumstances where both strategies are not contradictory. Instead, I favor a formulation in terms of an elitist assumption (decision control only for the "qualified") vs. incremental gains (public education through empowerment). The reason for this formulation is that, even in the cases Wriston is wrong (i.e., when government decision makers are clearly better informed and better qualified than anyone else), whether one likes it or not, "common" people will increasingly "meddle" in, right or wrong (Brown 1990).
Many cases, including those I reviewed, show that in most circumstances an 'elitist' model of decision is bound sooner or later to lead to a confrontation; the alternative is to accept the challenge of a long-term view. An 'incremental gains' model of decision will accept the added burden of giving voice to non-informed, non-qualified people, even at the risk of added overhead costs (efforts towards education and debate), potentially less optimal solutions or lower-quality decisions in the short-term, in exchange for the advantages in the long-run of a better informed, better educated, and more cooperative public. One "must develop not only knowledge of society but knowledge in society (Torgerson 1986)".
Evan Vlachos proposes a model that focus on levels of participation, instead of objectives of participation. The distinction is subtle, but this formulation is more flexible, since it doesn't imply 'a priori' judgments on intentions (even adopting the 'incremental gains' view, there will always exist cases requiring different levels of citizen involvement). He makes a distinction between public awareness, public involvement and public participation. "Public awareness implies one-way information and alerting to community issues. Public involvement implies two-way communication and a means of engaging community members in the exchange of information (dialog). Finally, public participation is the most intense form of interaction between authorities, experts and citizens and implies more than anything else truly joint planning and democratic delegation of power and shared leadership (Vlachos 1993)"
A related issue is the already mentioned "Public vs. Expert" dichotomy. Frederick Frankena documents "the emergent social role and political impact of the voluntary technical expert" (Frankena 1984). In fact, there are many cases where this distinction becomes irrelevant. Kennard points that "when it comes to values, we are all experts" (Kennard 1982), therefore if the issue is essentially dependent of value judgments, everyone is qualified.
Besides Frankena's and Kennard's arguments, citizens and NGOs can hire their own experts; and the exponential mass access to education and science increased the likelihood of finding qualified experts among individual citizens in the targeted (physical or virtual) neighborhood. However, this remains an open issue, because of the inequalities in the distribution of human and institutional resources, and in the scope of the projects being assessed. Vlachos, for instance, differs from Frankena on the relevance of the voluntary expert. "Within the last decade or so", writes Vlachos, "society has tended to advocate the simultaneous growth of participatory democracy and of expertise in decision making. It becomes difficult to maximize both of these value preferences and strains appear between the idealized conceptions of citizen participation and the harsh demands of public policy making and implementation (Vlachos 1993)". If both Frankena and Vlachos have a point, what is the dominant trend? It is important and relevant to collect evidence of the level of expertise reached in public participation processes.
Finally, James Glass proposes a model focusing on the function of each kind of public participation. He enumerates five objectives of citizen participation: information exchange, education, support building, decision-making supplement, and representational input (Glass 1979). Considering Glass approach, I suggest that one good way to evaluate the scope of each objective, is to assess the way it relates to the potential problems resulting of not having public participation:
• Weak legitimacy of some decisions (interests of majority may be neglected, interests of minorities may be ignored);
• Weak accountability, easier corruption;
• Weak constituency to support development effort and costs;
• No public help and cooperation in development tasks;
• Project plan and its review may miss aspects dependent on local knowledge that otherwise would have been an improvement;
• Later antagonism may block project, with added costs;
• No public education gains.
The identification of the objectives of public participation, and respective current problems associated with each, is important also because it provides the base for an useful "criteria of success", when considering possible steps towards improving the process facet of public participation. Similarly, it can help to identify the specific requirements that information technology should satisfy, to corroborate this improvements. Current ITs are not necessarily tuned to the best forms of participatory democracy.
3.2.3. Critique of public participation
Many decision makers are skeptical, to say the least, towards public participation. Among others, they point to typical problems found in current public consultation:
• The foundation for a decision being of technical nature, it is best left for qualified experts;
• Scope of the projects being assessed is vast, therefore it needs an expert multidisciplinary "corp." not available to citizens (particularly in some areas), or even to most NGO, sometimes not even to government agencies;
• Credibility in the process is low: people do not believe that their input will make a difference, regarding the final decision;
• Citizen perspective is often limited. There is sometimes lack of interest whatsoever. Local or individual bias leads to a limited view of the impact of a development decision (no "common good" perspective); or the discussion turns to generic or ideological debate, "off the mark" of the relevant issue (which may also reflect a deficit on forums for another level of debate);
• Time consumed in public consultation is expensive, particularly from the point of view of developers.
Is the current rationale of many decision makers against more public participation - particularly one with more weight over the final decision - obsolete? Better decision making processes and better use of available technology may not only allow the commendable goal of improving democracy, but there may also exist many cases where there is a larger space of dialog and compromise leading to satisfactory solutions that is not being explored. On the other hand, it is a fact that there has been many decisions, serving the public interest reasonably well, without any public participation; and it is questionable, at least in some cases, whether the conflict of multiple parochial interests would have blocked any decision at all, had the public been called to participate. It is therefore useful to briefly characterize classes of problems, from both the point of view of decision-makers and citizens.
Most decision making processes fall within one of the following cases:
a) When more public participation is mandatory for a more legitimate decision (for instance, in high-risk projects). There are clear cut cases where there is a well defined population whose lives will be deeply affected by the decision. Therefore a better informed population and improved public participation will be a better guaranty of the adequacy of the decision, at least from the perspective of the ones affected by it. Decision makers may or not welcome participation, but in cases like these they are increasingly aware of the potentially high costs (including political costs) of alienating the population.
b) When too much information (to the public) is feared because it will generate stronger opposition from people that will suddenly realize that some of their interests will be put in question; it is possible that these fears are well founded, meaning, more access to information and more diluted decision powers will paralyze some developments needed for the common good, or at least increase difficulty and costs.
c) When people's interests won't be put in question by a decision (or will be even favored by it), but people may fear it anyway, because of fear of change and the always present degree of uncertainty of outcome. In these cases, decision makers also tend to avoid too much public participation, too much spread of information, at least beforehand, or in the least they try to control the process limiting the boundaries for the public participation (like one month of access to a non-technical summary in some hard-to-reach place, and where there is little room for changes).
Except for the a) type cases, where decision makers will probably welcome better technology, and better use of technology (meaning institutional processes more suitable for this technology), the challenge is to show that in any event people today have already a wide access to information, and given the competition between political forces and/or economic interests, it is likely that at least one of them will use and spread the information; and precisely because it will be used with a narrow political/economic motivation, it may very well be filtered out in a less favorable and more hostile fashion (Vasconcelos 1993) than the original data would have been. Evan Vlachos reminds us that "the communication revolution is making more central the observation that public officials and public decision makers are now existing in a fishbowl compared to earlier times (Vlachos 1993)".
In the first class of cases (a), if there is an irreducible conflict of interests, that becomes essentially a matter of democracy, and the interests of the majority should prevail over less legitimate interests. The other cases are more interesting by the bigger challenge they represent. When there is a fear of conflicting interests (well founded or not), there is a space of contradiction, of conflict; but the use of new IT and adequate public participation processes may also uncover a previously unknown and unexplored space of solutions that could be more satisfactory or at least increase the legitimacy of the decision. This could happen by increasing in a significant way the number of people positively affected, as well of the spread of different communities (minorities, for instance) that will be favored by a better decision emerging from this larger space of solutions.
3.2.4. Techniques of Public Participation
I defined the process facet of public participation as including the choice of techniques of participation. If there is room for improvement, it has to translate into some developments in these techniques: therefore it is necessary to study its current limitations. In table 3.2.4.-1, I present a summary of a compilation of current techniques of participation, with some of their known problems, as presented in published work, in particular by the USA Environmental Protection Agency (EPA).
Table 3.2.4.-1 - Current Techniques of Public Participation
(EPA 1990) (Innes 1992) (Joanaz de Melo 1993) (Sapienza 1993).
|
Technique |
Description |
Problems |
|
Advisory Committee (Comissão de Acompanhamento) |
A group of invited experts representing interested parts |
It requires full-time dedication from members, for a long period of time Controversy may arise if the Committee recommendations are not accepted by decision makers |
|
Focus groups |
Small discussion groups that help to estimate public reactions. There has to be several of them, and led by professionals |
If it allows to estimate emotional responses, it does not provide any indication about how long they will last. It may be regarded as part of a process of public opinion manipulation. |
|
Dedicated phone line |
Experts (or trained operators) answering questions from callers and providing information over the phone |
It requires availability of well prepared personnel on a regular schedule base. Its success depends on public willingness to call... |
|
Interviews |
Interviews with people representing public agencies, NGOs, interest groups, or well known personalities |
It requires a lot of time and well prepared staff |
|
Talks |
Meetings where experts or politicians present formal communications or give formal speeches |
It doesn't facilitate dialog; it allows exarcebation of differences of opinion. It requires plenty of time to organize |
|
Conferences |
Less formal meetings where people present their views, ask questions, etc. |
Dialog is still limited. It may require even more time (and people) to organize |
|
Workshops |
Working sessions of small groups dedicated to complete the analysis of a certain topic |
It is not adequate for large audiences. It is frequently necessary to organize them in several places and on several topics. It requires plenty of people and time |
|
Surveys |
Carefully prepared questions are asked to a sample population |
It provides a still image of public opinion, but it does not provide any sense of how it may change with time, and other factors. It requires professionals, and is usually a very expensive technique |
|
Referendum or Plebiscites |
Counting votes within a community |
It requires an usually long and expensive phase of information and debate. Public may be more susceptible to emotional assertions than to reasoned opinions |
This table puts in evidence some obvious key factors for improvement through better use of IT: to help minimizing time and personnel requirements. But it also points to other important element: how can new IT help to facilitate reasoned and in-depth debate, and to enlarge the space of solutions vs. the space of conflicts?
3.2.5. The privileged status of public participation in EIA
An interesting aspect of the recent public participation research is the absolute predominance of cases related one way or another with environmental impact assessments (EIA). The discussion on the possible reasons for this phenomenon is left for the chapter concerning the analysis of the qualitative jump in IT developments. But the indisputable fact that EIA review processes are nowadays the "natural" ground for public participation cases, together with some of the characteristics that are associated with such predominance, led to a focus in EIA in the search for an adequate case study for this thesis research.
Among those characteristics, are the following facts:
• An EIA is required by law for most major developments in many countries, in particular in USA and European Union (EU);
• Some form of public participation is also required by law in most EIA cases, in the same countries;
• EIA review processes tend to become more standardized, for instance with all countries in EU adapting step by step their national laws and regulations to conform with common EU directives, and EU procedures for EIA being largely based in the American EPA's experience (Environmental Protection Agency, USA);
• Even if for different, possibly conflicting reasons, most stakeholders are interested in promoting some form of public involvement in EIA reviews.
These characteristics are enough to justify a choice to narrow down the field of my thesis research. Consequently, when public participation is referred in this thesis, the focus is on PP in EIA review processes.
3.3. Information Technology Review
Introduction; Criteria for selection of IT; The recent IT developments considered; Technology at the service of public participation; Knowledge representation and intelligent multimedia systems; Levels of information systems for impact assessment.
3.3.1. Introduction
The review of public participation research (previous chapter) shows the privileged status of public participation in environmental impact assessment (EIA), making it the favored ground for my thesis research. In this chapter I discuss the criteria for narrowing down the information technologies (IT) that are the focus of this thesis; I review the recent IT developments in question, in particular those that best serve public participation; I discuss more in detail knowledge representation models, based both on literature review and my previous work in this area; and finally I suggest a classification of information systems for impact assessment, according to their role and use level.
3.3.2. Criteria for selection of IT
The choice of technology to introduce in the EIA review process was a critical factor in the whole thesis experiment.
In this thesis I argue that a specific set of recent information technology developments represent a qualitative jump in IT potential for impacting public participation in EIA. Although I present this argument at a later stage, I must identify such IT developments here, since I need obviously to select elements of these IT to use in the experiment.
The choice of IT for the experiment is further narrowed down by my formulation of the thesis experiment expected evidence:
"T.1) That new IT can help lay, common citizens play a more knowledgeable and effective role, in public consultation concerning decisions involving technical arguments."
This suggests the choice of knowledge-based IT, applicable in the context of EIA.
"T.2) - That new IT can impact decision-making procedures: including and up to the point where many of the current procedures become inadequate and require a new regulatory framework."
This suggests the choice of technologies that are the base of modern decision support systems; and of new information systems that offer a reasonable expectation of helping the EIA review process.
"T.3) - That you need specific IT to best support a specific kind of public participation; and that IT solely promoted by the so-called "free market forces" does not satisfy this need, neither fulfills all the potential that new IT has in this domain."
This suggests the comparative use of IT available on the market, and an IT prototype specially developed and customized for public consultation.
"T.4) - That the presence alone (or even introduction) of new IT does not necessarily promote better public participation nor improve decision-making procedures favoring public participation and is actually unlikely to do so, unless a) there is a good understanding of the underlying planning paradigms in presence, and b) an effort is made to shape both new IT and a new institutional framework in order to build bridges between these planning paradigms."
This suggests the choice of IT and IT-based planning support systems that can be used by most, if not all, actors in the EIA review process and facilitate networked communication.
3.3.3. The recent IT developments considered
Among the significant IT developments relevant to the thesis experiment, I include:
3.3.3.1. Hardware:
a) The emergence of microcomputers (and personal computing) as a mainstream technology, enabled by the development of the integrated circuit, from a period where "real" computing implied mainframes and a mandatory MIS department. A notable component is also the computing power available in relatively cheap, portable computers.
b) Internet infrastructure (wire and wireless network, based on cable and satellite IT), together with digital telephone, with increased bandwidth for data transfers over the large net of telephone lines.
c) The massive distribution spread of CD-ROM readers (mass distribution of CD-RW "burners" only came by in late 90s, not really an option in 1996, but CD-R readers were at the time much more common in Portugal than Internet access)
d) Other support IT, such as satellite-based remote sensing, low cost scanners, etc.
3.3.3.2. Software:
a) Modern operating systems (UNIX, Mac OS, Windows), supporting desktop and portable "personal computers" (PC), as well as terminal distributed interactive access vs. batch process of mainframe-based OS (VMS, etc.);
b) TCP/IP (Transfer Communications Protocol / Internet Protocol), giving birth to an Internet where any kind of computer or operating system can connect to each other;
c) Hypermedia, multimedia;
d) Markup Languages Standards such as HTML (Hyper-Text Markup Language), corresponding multimedia server protocols such as HTTP (Hyper-Text Transfer Protocol) and other machine independent data representation (as opposed to word files incompatibility nightmare);
e) Artificial Intelligence applications (in particular knowledge representation, knowledge bases, inference engines, expert systems), and spin-off object-oriented languages with class inheritance, message/event driven software (scripting, automated metadata maintenance);
f) Direct Manipulation Computer User Interfaces, mouse-based, with new user interface paradigms such as cut-and-paste, drag and drop;
g) GIS (Geographic Information Systems) and spatial analysis tools.
The full discussion of why the particular relevance of these IT developments is left to a later chapter; here, I will lay down the general foundation.
In my view, the most adequate and promising IT for public consultation cannot be identified only from the point of view of the end user (either expert or "lay" citizen), but also and foremost from the point of view of the knowledge input and maintenance model. If data / knowledge input and maintenance is complex then it becomes expensive (time wise, expertise wise, equipment wise), it implies a specialized body of professionals (as at the early stages of computing: analysts, programmers, card punchers, operators, separated from user), and therefore such model is not likely to succeed. I will argue that the "IT qualitative jump" includes precisely the development of the microcomputer, having as a consequence the direct access of the end user to the machine, together with the control of its use, and even a certain level of programming (typically interpreted languages, vs. compiled, like macros and scripting languages). Therefore, the data structure, metadata, and mechanisms for data classification and metadata input are critical to a model where direct data input and classification is done by the end user.
This emphasizes the importance of metadata sustainable strategies and models, to which I dedicated previous work, and the concern about developing collaborative and automated classification tools (e.g. script events for meta classification, etc.) for the thesis experiment, as it will be further elaborated.
In table 3.3.3.-1 I present a brief chronology of some of the significant landmarks in information technology developments:
Table 3.3.3.-1 - Chronology of IT landmarks
(Global Reach 2002) (Boncheck 1996) (Hardy 1993) (Kurzveil 1990) (Owens 1986) (Panati 1984) (Langley 1968)
|
>600 BC |
The abacus (resembles the arithmetic unit of modern computers) is invented in China |
|
387 BC |
Foundation of Plato’s Academy, development (among others) of mathematical theories |
|
334 BC |
Foundation of Aristotles’ Lyceum, consolidation of the work of the Academy |
|
59 BC |
First regular daily newspaper, "Acta Diurna", Julius Caesar |
|
1450 |
Printing press invented (Johannes Gutenberg) |
|
1642 |
Pascaline, a machine that can add and subtract, is invented by Blaise Pascal |
|
1694 |
Liebniz computer, multiplies by repetitive additions, algorithm still used (Gottfried Wihelm Liebniz) |
|
1728 |
Automatic weaving with punch cards. (Joseph-Marie Jacquard) |
|
1822 |
Difference Engine, first computer built, calculated functions (Charles Babbage) |
|
1835 |
Analytical machine, with punched paper band, first programmable computer designed although never built (Charles Babbage). |
|
1844 |
First long-distance telegraph , Washington-Baltimore, USA (Samuel Morse) |
|
1847 |
Boolean algebra ("Mathematical Analysis of logic", George Boole) |
|
1867 |
First typewriter (Christopher Sholes) |
|
1876 |
First telephone patent (Alexander Bell) |
|
1879 |
Notation system for mechanical reasoning, precursor of predicate calculus and knowledge representation. (G. Frege) |
|
1888 |
First experiment with radio wave emission. (Heinrich Hertz) |
|
1897 |
Radio emission with antenna (Alexander Popov) |
|
1897 |
First patent for radio (Marconi) |
|
1906 |
First broadcast of human voice, AM radio (Reginald Fessenden) |
|
1927 |
First version of the "Differential Analyzer" (MIT), a "thinking machine for high mathematics (Vannevar Bush) |
|
1930 |
18 million radios owned by 60% USA households |
|
1936 |
Regular TV broadcast begins in UK |
|
1936 |
Binary calculus for programming - Turing machine (T. Turing, Louis Couffignall) |
|
1940 |
First fully electronic computer, ABC (Atanasoff-Berry Computer) |
|
1944 |
Mark I , fully electronic computer (Howard Aiken) |
|
1951 |
First electronic computer commercialized, UNIVAC-1 (Eckert, Mauchly) |
|
1955 |
First AI language, IPL-II information processing language (Newall, Shaw and Simon) |
|
1955 |
First transistor-based calculator |
|
1956 |
72 % USA households own a TV |
|
1956 |
First Artificial Intelligence conference is held |
|
1958 |
First integrated circuit (Jack St. Clair Kilby) |
|
1960 |
6000 computers in USA |
|
1965 |
Bell Labs produce integrated circuits (W.Hittinger, M. Sparks) |
|
1968 |
First ARPANET Information Message Processor (IMP), installed at UCLA (precursor to INTERNET) |
|
1971 |
First microcomputer in USA |
|
1971 |
First pocket calculator |
|
1972 |
Created the InterNetwork Working Group (INWG), giving birth to the INTERNET |
|
1974 |
Marvin Minsky publishes "A framework for representing knowledge", a landmark creating the sub field of Knowledge Representation |
|
1975 |
First Personal Computer (PC) introduced |
|
1975 |
5000 micro-computers sold in USA |
|
1977 |
First Apple PC ( Steven Jobs, Sthephan Wosniak) |
|
1981 |
IBM introduces its PC |
|
1981 |
212 Internet servers in operation |
|
1982 |
First Compact Disc (CD) Players in market |
|
1983 |
90% USA households own a TV |
|
1983 |
6 million PC sold in USA |
|
1986 |
700 expert systems in operation |
|
1987 |
1900 expert systems in operation, mostly finance and manufacture control |
|
1989 |
Developed HTTP (hypertext transfer protocol) at CERN, Switzerland |
|
1991 |
First Internet Web Server and Web Browser (CERN) |
|
1993 |
1,776,000 Internet servers in operation |
|
1993 |
120 web sites on-line (according to "worm robot"; actual number may be higher) |
|
1996 |
230,000 web sites on-line (according to "worm robot"; actual number may be higher) |
|
2000 |
25,675,581 web sites on-line (according to "worm robot"; actual number may be higher) |
|
2001 |
529 million people on-line (Internet) |
3.3.4. Technology at the service of public participation
In the chapter reviewing public participation, I discussed the different objectives that are pursued, from different perspectives. How does each variety of computer tool relate to each kind of public participation objective? A multimedia tool such as an "Interactive Kiosk" may clearly play an important role in education, and (maybe less important role) in information exchange and support building. As for supporting citizen input and decision-makers, there lies a bigger challenge, since it requires a qualitative jump in interactivity (support user input and non-structured search), adaptability (to different kinds of users, expert and lay), versatility (support multi-domain conceptual links) and robustness (integrate user input with system knowledge and keep the whole consistent). Also, many times those Kiosks are essentially a one-way street for conveying information, where there is no questioning of the contents, no feedback, no possibility of correcting or adding contradictory views to the multimedia data base. Any computer tool developed having in mind public participation should be designed to clearly respond to one or more of these needs.
Given the complexities of an impact assessment, information systems play an important role as aids for gathering and structuring related information: for analysis, and for experimenting with different hypothesis through simulation. If we take the example of evaluating impacts in infrastructure planning, a Decision Support System (DSS) may help national agencies and local governments to make strategic choices, such as: between different users of the infrastructure services (e.g. residential vs. commercial vs. manufacturing); between capital investments and maintenance of existing services; between different infrastructure sectors; between different city and regional priorities; and between different institutional and regulatory arrangements. By the same process, a DSS can help public participation, by fostering understanding of the implications of each alternative.
Different kinds of information systems play different roles. Ortolano refers to several model-based systems to study the impact of infrastructure on land use: conventional multiple regression models, dynamic simulations, multiple-market equilibrium models (Ortolano 1988). Krueckeberg suggests that different land uses or activities have typical data found repeatedly associated with them in information systems (Krueckeberg 1974).
For cases in the domain of environmental impact assessment, government agencies have accumulated some experience with specialized IT, within the techniques of information they use: press reports, newspaper ads, custom-made newsletters and, more commonly, printed versions of non-technical summaries distributed or made available in public sites, sometimes together with more detailed technical dossiers (Sapienza 1993). Less frequently, it is cited the use of presentations to groups of experts and citizens using audio-visual technology, even if it is recognized to be the only technique (from all the above) that does not present any known disadvantage (EPA 1990) (Costa 1993) (Joanaz de Melo 1993) (Rua 1993). Significantly, most of the disadvantages associated with each technique refer to its high cost, in terms of required experts and time spent (EPA 1990) (Joanaz de Melo 1993).
These are conditions that at first glance point to expert systems as the most promising IT for EIA. So why don't we observe an explosion of development of such AI systems applied to public participation?
Environmental Impact Assessments are typically multi-disciplinary: they usually require experts from several domains (environment, transportation, economy, law, city planning, etc., etc.) and frequently involve multiple institutions. This leads to certain difficulties. Besides the difficulties of institutional integration, problems arise from the need to interface not only different bodies of knowledge, but also different value systems.
Expert Systems succeeded mainly in either highly focused and specialized domains, or in domains of taxonomic nature (Winston 1988) (Han 1989) (Chen 1991) (Wright 1993). In other words, in domains where knowledge can be easily represented in one single or dominant form. It seems then that, in order to successfully apply this IT to public participation, we need to tackle the problem of allowing different kinds of knowledge to be represented in the most adequate form, without imposing a dominant paradigm of representation; and we need some metaknowledge that will help to choose the best representation formalism. By the same token, a "public-participation-friendly" system should allow different kinds of data to be incorporated and visualized in the most adequate media. The criteria of adequacy, relating kinds of data (or knowledge ) with the choice of media (sound, text, picture, map, video, etc.) may be not self-evident, and also require some expert knowledge included in the system - and, naturally, some kind of inferencing ability.
This leads us to discuss more in detail the information technology developments that address knowledge representation options, and in particular those able to handle multimedia formats.
3.3.5. Knowledge representation and intelligent multimedia systems
Among the multiple IT recent developments, it is of special relevance the progress done by a sub-field of artificial intelligence: knowledge representation. Why this relevance? I indicated above a specific motivation for a specific domain: the multidisciplinary nature of EIA and EIA reviews. But we can generalize this relevance to a broader domain. Any planning process, most particularly a decision making one concerning technical-dependent options, is supported on specialized knowledge, and not just the technical data per se. Hence the importance of a system able to represent "planning knowledge", elements of expertise and experience that can then be captured and stored in digital form and feed some form of computer-based support tool, usable by other experts and non-experts.
In this sub-chapter I analyze the different models of knowledge representation and their limitations; I then proceed to discuss the implementations that may have a direct bearing with the thesis experiment, based on specialized literature and my own earlier work.
3.3.5.1. - The limitations of knowledge representation models
One problem that persists in the design of systems that are not only knowledge-intensive but also must support multiple domains, is the choice of a suitable knowledge representation format. The problem lies in many fronts:
• Different types of knowledge require different types of representation. This is addressed by hybrid representation systems (Heylighen 1991). (Minsky 1981) (Winograd 1975) (Woods 1975);
• Different types of knowledge require different kinds of reasoning. This is addressed by the use of multiple inference engines, and intelligent "dispatching" systems (Carroll 1987) (Gleiz 1990);
• Knowledge acquisition and maintenance modules of the system are usually so hard-coded to a specific application (with pre-defined knowledge and knowledge types) that sustainability of the system is put in question. This is addressed with intelligent user interfaces (Ferraz de Abreu 1989) (Rissland 1984);
• Knowledge management usually implies the "internalization" of knowledge and data files, that is, any bit of information must be reformatted, re-classified and some times stored for private use of the system, creating a high impedance between the system and the outside world that further limits sustainability. This is addressed by non-obtrusive metadata strategies (Davis 1977) (Ferraz de Abreu 1992).
In Table 3.3.5.1.-1 , I present a summary of my compilation of the different knowledge representation models, the kind of inference (reasoning) engine usually associated with each, and the more suitable system dynamic context or control mechanism (Heylighen 1991) (Ferraz de Abreu 1989a) (Winston 1988) (Brachman et al 1985) (Minsky 1981) (Maruyama 1973).
Table 3.3.5.1.-1 - Knowledge Representation Models
|
Representation |
Inference / Reasoning |
System Dynamic |
|
Expressions (equations) |
Algebra |
attribute driven |
|
Rule-Based |
Production Rules (forward/backward chaining) |
event or attribute driven |
|
Regular Grammars (Automata) |
Production Rules (expansion) |
event or attribute driven |
|
Semantic Networks |
Relational Rules |
relationship driven |
|
Object-Oriented |
Inheritance (Z,N) |
attribute driven |
|
Script/Procedural |
Dispatcher |
event driven |
|
Frames |
Daemons |
event driven |
|
Intelligent agents |
Blackboard |
event driven |
|
Case-Based descriptors |
Pattern-Matching |
attribute driven |
Reflecting the earlier "general problem solving" orientation that prevailed within artificial Intelligence, many authors favor this or that model of representation as the most promising for any domain. The discussion concerning the relationship between representation and the world of applications is still going on (Pearce 1992) (Aiken 1991) (Davenport 1991) (Gleizes 1990) (Jaffe 1989), and it remains as an open question.
My own approach, applied to my area of concern (EIA), was to consider building a library of default representation formats for each kind of "knowledge unit", in the domain of impact assessment considered by the system.
For instance, knowledge about primary and secondary consequences of infra-structure shortfalls and of each alternative action, is more about causal relationships (if truck traffic and weak pavement than new road is needed) than about knowledge in depth about entities or objects (roads, trucks); this points towards a rule-based representation and reasoning. Other knowledge domains may depend on much weaker cause-effect relationships and be instead more based on precedent experience (like border cases in environmental law applications), pointing towards a case-based representation and reasoning. Yet other domains may be based on in-depth knowledge about entities, or objects (like land uses, or parametric description of water treatment systems), hence pointing towards the use of object-oriented or frame-based representation and reasoning (Booch 1991).
To build a library of links between domain and representation, one needs to associate with each knowledge unit a descriptor about itself, or "metaknowledge" descriptor (Davis 1977). For the sake of tradition, I will use in this thesis the term metadata with the wider definition that include the metaknowledge concept.
Although my earlier work in this area targeted other application areas (such as infrastructure shortfalls and natural resource management), I can draw upon this experience for this thesis research, as I discuss next.
3.3.5.2. - Rule-based representation (expert system for infrastructure shortfalls)
Rule-based representation is usually associated with knowledge expressed in cause-consequence relationships, or "causal reasoning". Expert systems are the most typical approach to handle rule-based representation and use it to infer reasoning chains. There are many examples of successful expert systems in areas like finance and diagnosis. MYCIN (medical diagnosis), developed at MIT, is one of them (Kurzveil 1990).
Applying this representation paradigm to deal with planning knowledge, I developed a prototype of an expert system dedicated to explore the cycles of cause-consequence in relation to infrastructure shortfalls (Ferraz de Abreu 1991b). This system in particular uses a forward chaining inference engine, that I developed and programmed myself based on my previous work on intelligent graphic interfaces (Ferraz de Abreu 1989a), and 5 classes of rules: definition, qualitative, quantitative, spatial, and question. Fig. 3.3.5.2. - 1 shows an index of the rules and classes in this expert system.
Fig. 3.3.5.2. - 1
- Rule Index card in the Expert System for Infrastructure ShortfallsIt is useful to consider a brief example of the correspondence between the issue (or reasoning) and its rule representation:
Suppose we have a great number of low-income households, therefore with very low housing standards, and that there is no service providing gas or other cooking / heating fuel (a shortfall). These houses are likely to have poorly ventilated wood stoves. This will cause indoor pollution (a primary consequence). Then, this will cause high rates of children suffering from chronic lung disorders; then, this will cause their mothers to lose hours of work time caring for them (secondary consequences); then, this will bring low productivity; if an epidemic arises, increased public health costs (aggregated secondary consequences).
Representing this reasoning with rules is fairly straightforward:
IF household IS low-income
THEN house-infrastructure IS low-standard
ventilation IS poor
IF house-infrastructure IS low-standard AND
heating-fuel IS-NOT available
THEN house-heating IS wood-stove
IF house-heating IS wood-stove AND
ventilation IS poor
THEN indoor-pollution IS high
IF indoor-pollution IS high
THEN rate-of-children-lung-disorder IS high
IF rate-of-children-lung-disorder IS high
THEN mothers-productivity IS low
public-health-costs IS high
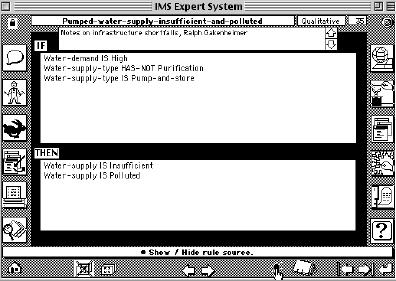
Fig. 3.3.5.2. - 2
- Rule example in the Expert System for Infrastructure ShortfallsFig. 3.3.5.2. - 2 shows how one of these rules is represented in the system.
The rule representation of the above reasoning is therefore adequate and simple. However, if we consider now that low productivity and increased costs are likely to cut on salaries and on health subsidies, which will perpetuate the low-income of the original families considered, we have a positive feedback or reinforcement of secondary consequences over the primary consequences. Representing these facets of causal reasoning with a rule-based system is not so trivial.
Because of the cyclical nature of the inference net, that is, a graph with cycles instead of a tree-graph, I implemented the inference engine in such a way that the user can visualize (Fig. 3.3.5.2 - 3) the intermediate steps of the inference process, and not just the final inference set (as it is more common). The output of this system can be extended to suggest policy recommendations, or estimate costs of shortfall situations. However, rule-based representation is clearly more suited to knowledge that can be expressed in tree-like inference nets.

Fig. 3.3.5.2. - 3
- Expert system inference showing intermediate steps3.3.5.3. - Rule-based vs. regular grammar representation and reasoning
Environmental impact assessments is a domain that, at first sight, seems to suit itself well to a rule-based representation model, since it is frequent to listen to experts arguing for cause-consequence relationships, using a "causal reasoning". But instead of the usual tree of inference, many problems in impact assessment demand also other forms (like a non-tree graph, or graph with loops) able to capture cycles and feedback. Representing cycles is important because consequences of impacts, just like the infrastructure shortfall example, may affect individuals, activities and the environment in general, cycling through all of them. A cycle implies that some kind of feedback is present, either positive (reinforcement) or negative (regulation). In such cases, a "regular-grammar" (state automata) representation model may be more adequate.
To clarify my application of the notion of positive and negative feedback's in modeling shortfall consequences, consider this more aggregated graph of inferences with the following factors:
In a city, there is a poor garbage collection service, resulting in the accumulation of garbage in the area (G). This will increase the number of bacteria present in the area (B). This will increase the number of diseases (D). All these are direct proportionality functions (if the number of G increases, B increases; if G decreases, B will decrease). Now consider that increasing diseases will induce people to leave the city (or will kill people), causing the reduction of the number of people in the city (P). This will cause the quantity of garbage to decrease, that is, a case of negative feedback or regulatory effect of the secondary consequences over the primary consequences.
In Fig. 3.3.5.3.-1 is a graph representation of this simplified model (adapted from (Maruyama 1973)), with other dimensions added: S for sanitary improvements (which will decrease directly both the number of diseases and bacteria); C for migration into the city (increasing the number of people in the city) and M for modernization of the city. In general, a + sign identifies a direct proportionality relationship, a - sign the inverse proportionality.
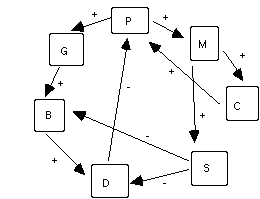
Fig. 3.3.5.3.-1
- Graph representation of the inference net of shortfall consequencesThis representation formalism is simple, yet very powerful. For instance, by counting the number of negative signs (inverse proportionality relationships) within a complete cycle, it is possible to forecast either a positive feedback - reinforcement (even number of minus signs) or a negative feedback - regulation (odd number of minus signs), for that cycle.
Several authors developed models of different aspects of these relationships that have some component relevant to the analysis of the shortfall implications. Laredo emphasizes the importance of the sector linkages of water services in its impact on agriculture, industry, health, and housing (Laredo 1990). Scenarios involving infrastructure shortfalls kind of problems can serve as a testbed for the potential of this representation formalism.
3.3.5.4. Case-based representation and reasoning issues
Environmental Impact Assessment (EIA) case-based reasoning presents issues that are similar to the ones faced in the domain of natural resource management, as I concluded from previous research (Ferraz de Abreu 2002b).
Case study materials collected for other purposes can be useful for "crude hypothesis testing" (Feeny 1992). They may be used to generate hypothesis inductively, as suggested by Elinor Ostrom (Ostrom 1992); or they may be used to test hypothesis derived from theory or from previous inductive reasoning. Just as within the EIA domain.
Examples of case studies to test hypothesis are the studies to examine the effects of group size on the performance of institutions managing common-property resources. Bullock, Baden and Feeny mention similar use of case studies (Baden 1977) (Feeny 1992). One advantage of this research approach is that it reveals patterns of variables or factors impacting on the outcome of the case. For instance, Feeny reports four factors that emerged from the referred study: cost of intragroup enforcement, cost of group exclusion, cost of decision making, and cost of coordination (Feeny 1992).
Representing case-based knowledge is not trivial either, and I did not find any example of a software implementation, other than adaptations from general-purpose data base management systems.
One common problem with domains that rely heavily on precedent experience, as commonly is the case in EIA, is the lack of a structured library of relevant cases. The problem is compounded by "syntactic" and "semantic" sub-problems:
On one hand, one needs more than written papers or reports to grasp the complexities and subtleties surrounding each case. For instance, dynamic visual data - typically recorded in videotapes, during series of field surveys - is often essential (Wiggins 1990). The sequential nature of the traditional analog video devices makes the search for the significant video segments a time consuming and tiring task, which further discourages the integration of that data in the analytical process.
On the other hand, case studies often provide conflicting evidence. No simple system can keep its consistency under these circumstances; for instance, it is not possible to use the already "traditional" approach of Truth Maintenance Systems in Database and Expert Systems.
Having in mind natural resource management, I designed an information system to make the most of a case-based approach: a "multimedia data base of research cases". Reviewing the data structure for this system is relevant, since it was one important step towards the system I prototyped to test the potential of "intelligent" multimedia technology in the context of EIA reviews.
a) Data structure:
The data unit of this multimedia data base is the research case. The body of this data unit is structured the following way:
• Case identifier (usually a name). Serves as index key;
• Context (resource type, geographic location, etc.);
• Initial status (conditions at a date defined as the beginning of the research period);
• Actions (deliberate, controlled human intervention impacting on the resource and its users);
• Events (non-deliberate, non-controlled natural or social changes impacting on the resource and its users);
• Final status (conditions at a date defined as the end of the research period, if past, or the current date);
• Outcome (degree of success or failure, which may be user defined);
• Experts (persons contributing with information).
b) Data model:
Modeling this kind of data (research case descriptor) in such a way that the system is comprehensive but at the same time simple to consult and update, is not trivial. The popular aphorism "there is no such thing of a free lunch" is particularly valid in the world of data base design. In this case, the more structured the data is, the better we can manipulate it; but also the greater loss of information content happens in the process.
In my approach, I intended to test a data model with two levels of abstraction (consequently, two levels of structure) to capture as much as possible the best of the two worlds; in this case, the trade-off is with redundancy. To illustrate this data model, consider Fig. 3.3.5.4.- 1:
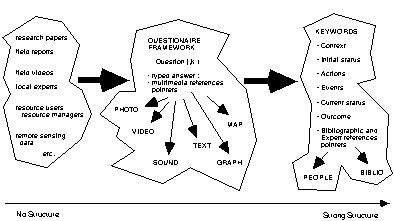
Fig. 3.3.5.4.- 1
- Data Model for Case-Based Knowledge RepresentationOutside the data base, data is not constrained in any way by a particular data model structure. By bringing it in, through a pre-defined questionnaire, and then linking each answer with specific multimedia references (for instance, several discrete video segments), some structure is gained, which facilitates for instance comparative analysis between different cases. At the same time, some information that does not fit neatly in the questionnaire framework, will be lost. This is the first level of abstraction, which still allows a large degree of freedom, like free text directly typed into the data base, possible contradictory opinions and references, etc.
A second level of abstraction is then possible, by "summarizing" the characterization of the research case by sets of keywords. This allows for more sophisticated data analysis, such as cluster analysis, search by patterns of keywords (Pearce 1992), and deductive or inductive inferencing by generalization from the "nearest" matches among the data base cases (case-based reasoning). The price to pay is a more imperfect representation of the case - semantic loss - together with some redundancy - keywords may in some cases be a simple repetition of some of the sentences of the questionnaire's answers.
By adopting an object-oriented representation, it is possible to structure even more this information with recourse to a hierarchy of classes and class instantiations arising from the realm of the Environmental Impact Assessment. For instance, a class Industry has associated all the relevant information (relevant to impact assessment) that is shared by any and all industries; when a industry is added to the system, it is sufficient to declare it as belonging to the Industry class, in order to inherit automatically all that information. A taxonomy of industries can be represented under this class hierarchy (for instance Chemical industries, Textile industries, etc., for Industry class; Paint industries, Fertilizer industries, etc., for Chemical industry subclass, etc.). Problems may arise in some cases given the lack of rigorous consensus over the definitions and concepts.
The handling of conflicting evidence is a challenge, but in this data model it is possible to adopt Lenat's approach of co-existence of multiple belief or truth systems within the data base. This approach implies the introduction of an operator to detect conflict, and to call upon meta-rules to handle each conflict type.
An example of such meta-rules would be: if two cases (A, B) present all the same keywords identifying status, actions and events, and one of the keywords identifying outcome is different (not matched), we have a conflict of evidence. Then, search for all other cases in data base containing the conflicting outcome keywords; select among the cases those that contain the larger match of similar keywords defining status, actions and events; list the non-matching keywords defining status, actions and events; suggest to the user that the reason for conflicting outcome may be found in the fact that one of the keywords in this list is in reality present in case A, despite the fact that case A representation was not given that keyword. This way, the system has the means to infer best possible matches in conditions of conflicting truth systems, and give useful hints on analytical efforts to "break" the conflicting evidence.
3.3.6. Levels of Information Systems for impact assessment
One kind of system, or for that matter, one kind of IT, won't solve by itself the technological handicap presented by current systems when applied to public participation. It is therefore important to understand the context (of other systems and IT) in which it will play its best role.
In Fig. 3.3.6. - 1, I introduce a diagram modeling the role of different information systems in the quest for analyzing and correcting impact assessment problems. The diagram proposes four levels at which information systems may operate, and complement each other: source level, conceptual level, analytical level, and use level.
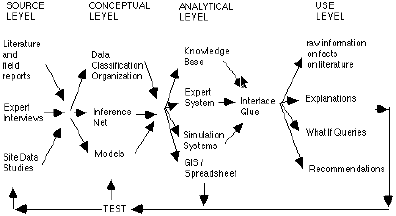
Fig. 3.3.6. - 1
- Role levels for information systems in impact assessmentAn experimental prototype of an "Intelligent Multimedia Decision Support System" should be able to interact with any module at all these levels. However, targeting the use to public participation poses heavier requirements on the "Interface glue", to handle different levels of user domain expertise.
