


7.1.1 Generating Random NumbersIn generating sequences of random numbers we wish to duplicate, in effect, a game in which a fair wheel of fortune is spun and the outcome of the game is recorded after each spinning. If the periphery of the wheel of fortune is divided into m equal intervals which are indexed with the integers from I to m, this game produces independent random integers which are uniformly distributed in the 1 to m range. There are basically two ways of obtaining sequences of random numbers for a simulation experiment. The first way is simply to "read" the random numbers from a list of such numbers which has already been compiled by somebody else. For example, a table with I million random digits was published in 1955 by the Rand Corporation. Such tables of random numbers have been recorded on magnetic tape and can thus be read quickly by a digital computer. The second way (and, by now, the most common) is to have the computer itself generate a sequence of random numbers. This is accomplished by having the computer execute a short "program" every time a new random number is needed. This computer program essentially uses the last random number produced, say the (n - 1)st in the sequence, to produce the next random number, say the nth in the sequence. The specific method employed can be any one of the congruential methods. For instance, the mixed congruential method uses the expression How many different numbers can we obtain through (7. 1)? Obviously, at most, m, that is all the numbers between 0 and m - 1. For example, with a = 5, c = 3, x, = 7, and m = 16, we obtain x1 = 6 (as we just saw) and then x2 = 1, x3 = 8, x4 = 11, x5 = 10, x6 5, x7 = 12, x8 = 15, x9 = 14, x10 = 91 x11 = 01 x12 = 3, x13 = 2, x14 13, and x15 = 4, in all the 16 different numbers in the range from 0 to 15. What is x16 in this sequence? We have a·x15 + c=23 and x16=23 (modulo m) = 7. Thus, the earlier sequence will now be repeated once again with x17 = 6, x18 = 1, and so on. The example above illustrates two interesting points. First, any
sequence of random numbers produced through (7.1) is cyclical. Each
cycle consists of a necessarily finite number of distinct numbers (at
most m). After a cycle has been completed, a new cycle identical to the
previous one begins. (In our example each cycle consists of 16 distinct
numbers.) The finiteness of the cycles will obviously cause problems in
a simulation if the length of a cycle is small: a succession of
identical short cycles of numbers definitely does not behave as a
sequence of independent random numbers (we have
The second observation concerns the meaning of the word "random" in the case of sequences produced through (7.1). Obviously, if we know a, c, and m we can predict perfectly the complete sequence that will follow any initial number x0. For this reason, the initial number x0 used to produce some sequence of numbers is called the seed of this sequence. For the same reason, the sequences of numbers produced through (7. 1) (as well as through other congruential methods) are also called pseudo-random numbers. This, however, is also of academic importance as long as the sequences of numbers produced through (7.1) qualify (through passing the appropriate statistical tests) as independent samples from a discrete, uniform probability distribution, that is, as long as the successive numbers appear to an observer to be drawn from a game similar to the spinning wheel game that we described earlier. In fact, the property of reproducibility for the sequences generated through (7.1) is in itself a most desirable one. For, when we wish to perform a simulation experiment under "identical conditions" with some earlier experiment, all we have to do is provide the same seed, x0, used in the earlier experiment to obtain the same sequence of random (or pseudo-random) phenomena as before. We have yet to say how the constant positive integers a and c in (7. 1) are chosen. An unfortunate choice of a and c will unavoidably lead to short cycles1 of numbers (which are usually anything but uniformly distributed) even for a large m. Happily, the branch of mathematics called number theory provides the guidelines for a good choice of a and c. For instance, in the case of digital computers, where, as we have mentioned, we use m = 2b, it can be shown that a should be chosen such that it is equal to I in modulo 4 arithmetic (i.e., a = 1, 5, 9, 13 .... ) and that c should be an odd number.2 The choice of x0, the seed, is immaterial in this case as far as the length of the cycle is concerned. In summary, the desirable properties of any method for producing sequences of random numbers in a digital computer are:
The congruential method that we have just described is typical of the techniques used to generate random numbers and possesses all of the properties listed above. In a practical sense, the important fact is that any modern computer system is preprogrammed to produce sequences of random numbers that possess-at least as a close approximation-all six of the desirable properties mentioned above. Typically, these numbers are produced by just calling an appropriately named "function" or "subroutine" in the computer repertoire (typical names for these miniprograms include RAND, RANDU, etc.). All that is required of the programmer is to provide a seed to begin the sequence. The computer subsequently provides automatically the input (i.e., the number xn-1 in the mixed congruential. method) needed to produce the next number, xn, in the sequence. The random numbers produced through these preprogrammed methods are
usually presented in the form of numbers uniformly distributed between
0.0 and 1.0 [which is done by dividing internally the random number
resulting from (7. 1) by the number m]. Obviously, the 0 to I interval
is thus subdivided so finely that, for all practical purposes, it can be
assumed that the computer produces statistically independent samples
from the continuous uniform probability density function shown on Figure
7. 1. This, too, will be our assumption from here on, and we shall use
the expression "independent uniformly distributed (i.u.d.) over [0, 1]"
random numbers. 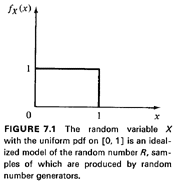
2 Strictly speaking, these are necessary but not sufficient conditions for the sequences of random numbers to possess all the statistical properties of independent samples from a uniform distribution. |
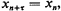 where
where
 is the length of the cycle). However, if m is a very large number and a
and c are chosen with sufficient care to make the length of each cycle
comparable to the size of m, the finiteness of the cycles is of no
practical significance. Consider the case when m is chosen to be equal
to 2b, where b is the number of bits in a binary computer word. (This
is the choice of m made in computer-based simulations, since 2b is the
total number of integers that can be expressed in binary form with the
number of bits available.) When b = 32, we have m = 232 ~/= 4.3 billion
distinct numbers. With a cycle length in this order of magnitude, it is
an entirely academic matter that the same sequence of numbers will be
repeated at some future point.
is the length of the cycle). However, if m is a very large number and a
and c are chosen with sufficient care to make the length of each cycle
comparable to the size of m, the finiteness of the cycles is of no
practical significance. Consider the case when m is chosen to be equal
to 2b, where b is the number of bits in a binary computer word. (This
is the choice of m made in computer-based simulations, since 2b is the
total number of integers that can be expressed in binary form with the
number of bits available.) When b = 32, we have m = 232 ~/= 4.3 billion
distinct numbers. With a cycle length in this order of magnitude, it is
an entirely academic matter that the same sequence of numbers will be
repeated at some future point.