9.35 Illusion Laboratory
Spring 2023 Auditory Lab

How does modulating sine-wave speech affect how realistic and easy it is to comprehend?
It has been demonstrated that very few parts of human speech are necessary in order
to comprehend meaning in sound. This has been aptly demonstrated by "sine-wave speech",
a form of speech created using sine waves that occur at the formants of vowel sounds. Despite
being highly-degraded in terms of sound information, sounds created with just three formants
can be parsed as language.
Additionally, it has been shown that modulation is important to our understanding of speech,
as the human voice naturally modulates while speaking. Thus, we wondered if modification
to sine-waves speech such as frequency modulation would affect how easy it is to understand.
To test this, we used a sine-wave speech file and modulated it using frequency and amplitude modulation.
Inital sounds
We first began with the initial sine-wave sound. See if you can identify what is being said!
Click for Answer:
Where were you a year ago?Frequency modulation
We applied frequency modulation to the sound to see if it would make the sound more perceptable. First at 300hz, then at 3000hz
Frequency modulation, 300hzFrequency modulation, 3000hz
Amplitude modulation
We then amplitude modulated the original sound; again at 300hz and 3000hz
Amplitude modulation, 3000hzAmplitude modulation, 3000hz
Additional findings
While transferring the sound from an .swi file, which includes frequencies and amplitudes at evenly-spaced timestamps, into an audio file that can be manipulated freely in python, we discovered that down-sampling the audio file from 40khz, which captures the complete range of human hearing to a sampling rate of 8khz, which only captures frequencies from 0-4khz, the sound became much easier to understand. Listen to it here!
Downsampled sine-wave speech
It's difficult to account entirely for why this is the case, as there are many variables
that may confound the results. The first is that our transfer of the sound from .swi to
.wav was not perfect. The software necessary for manipulating .swi was complicated and
didn't allow for easy manipulation, which is why we choose to convert in python. A second
reason may be that restricting a slightly modified sine-wave sound to 4khz was similar to
a phone call voice, which many of us are familiar with and are acclimated to.
More work would need to be done to create a perfect transfer from .swi to .wav in python.
Regardless, we only started with three sine-waves and their amplitudes at varying times, and
through some modulation, created something that closely resembles a modulated human voice.
Additionally, our amplitude modulations at 3000hz seemed to also capture the feeling of being spoken
to, though perhaps through some medium that is modulating the sound such as a fan. These pertubations
to the sound, though not natural, may be "explainable" by the brain, making the original sine-wave
speech more parsable.
Spectrogram readings
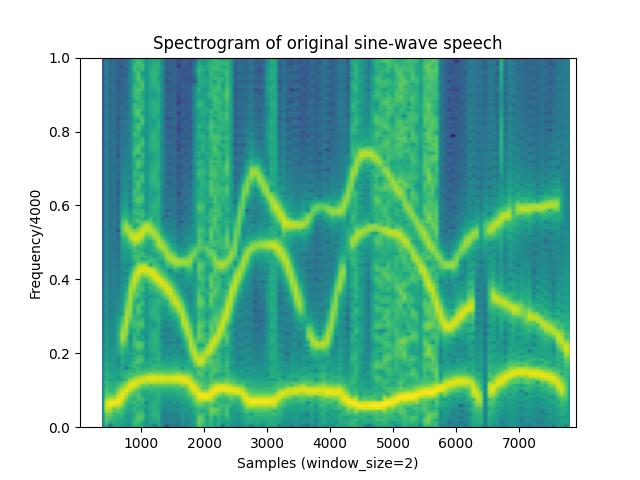
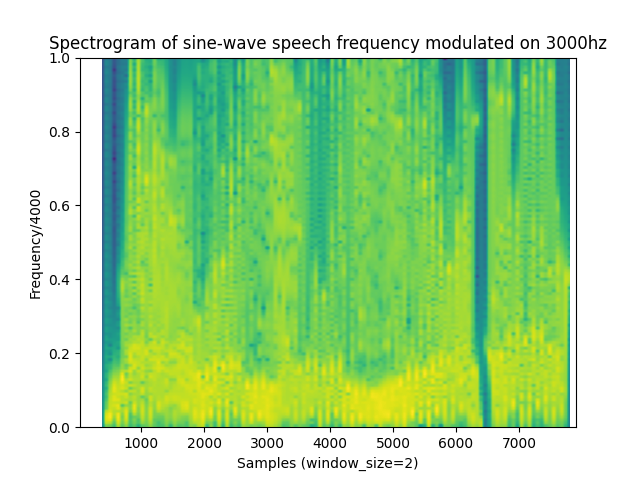
Here we can see that the modulation added a lot of variation to the original sine-wave speech, and in some ways looks closer to the spectrograms of normal human speech.
Conclusion
Amplitude modulation added an interesting timbre to the sound that increased its ability to be recognized as human speech. More work needs to be done in terms of what attributes of modulating a sine-wave make it sound more "human", as well as what attributes of random noise or other modulation can increase the recognizability of sine-wave speech.
Citations:
Remez, R.E. (1994) A guide to research on the perception of speech. In M.A. Gernsbacher (Ed.), Handbook of psycholinguistics. New York: Academic Press.
Carlyon, R.P. (1991) Discriminating between coherent and incoherent frequency modulation of complex tones. Journal of the Acoustical Society of America, 89 (1) , 329-340.