Congestion control schemes that are commonly deployed today are loss-based and were developed in the 2000s. The internet has changed dramatically since then, and these schemes are no longer suitable. This has prompted new research interest in this area, ranging from complex machine learning and optimization techniques [Remy, Tao, PCC, Vivace] to exploring usage of hitherto under-explored ack-arrival rate as signals [PCP, Sprout, BBR]. It has long been recognized that delay-based congestion control overcomes many challenges that loss-based schemes face [Vegas, FAST]. However they have challenges of their own that have precluded their deployment. In this work, we identify and solve some of these challenges to create Copa, a practical delay-based congestion control algorithm for the Internet.
About Copa
Copa is an end-to-end congestion control algorithm that uses three ideas. First, it shows that a target rate equal to 1/(δ dq), where dq is the (measured) queueing delay, optimizes a natural function of throughput and delay under a Markovian packet arrival model. Second, it adjusts its congestion window in the direction of this target rate, converging quickly to the correct fair rates even in the face of significant flow churn. These two ideas enable a group of Copa flows to maintain high utilization with low queuing delay. However, when the bottleneck is shared with loss-based congestion-controlled flows that fill up buffers, Copa, like other delay-sensitive schemes, achieves low throughput. To combat this problem, Copa uses a third idea: detect the presence of buffer-fillers by observing the delay evolution, and respond with additive-increase/multiplicative decrease on the δ parameter. Experimental results show that Copa outperforms Cubic (similar throughput, much lower delay, fairer with diverse RTTs), BBR and PCC (significantly fairer, lower delay), and co-exists well with Cubic unlike BBR and PCC. Copa is also robust to non-congestive loss and large bottleneck buffers, and outperforms other schemes on long-RTT paths.
Copa in Production at Facebook
Facebook is using Copa in production for live video upload for android devices from all over the world. They have found that Copa improves throughput and delay in most settings compared to BBR and Cubic—two widely used congestion control algorithms. It is thus able to deliver better quality video with lower delay. As a result, Facebook has experienced better end-user metrics (video watch time). Detailed analysis can be found in their blog post. We give a brief summary of their findings below:
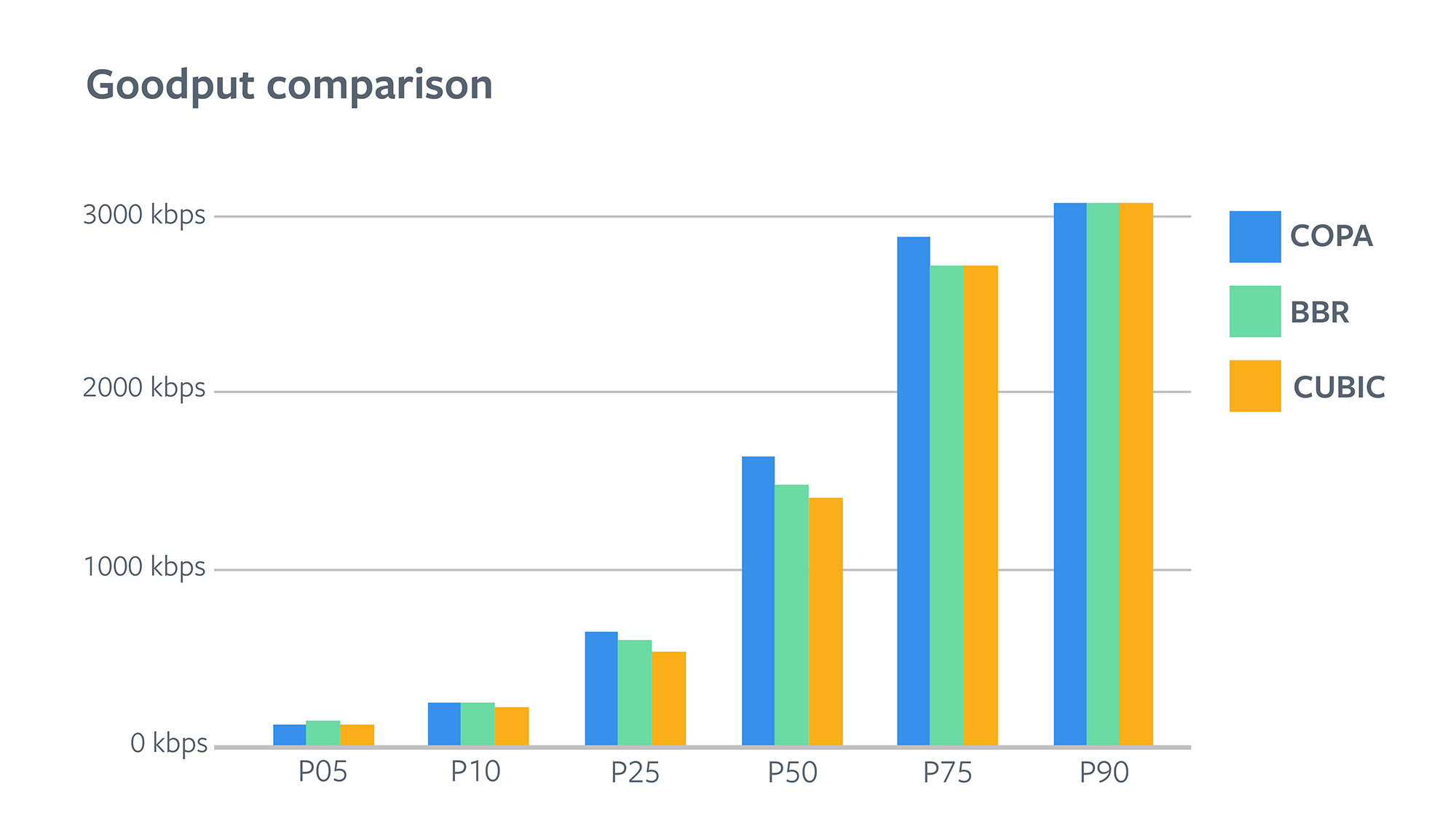
Goodput1 achieved by the various algorithms segregated by link quality. Copa correctly determines when the link is free and increases the transmission rate. Yet, as shown below, it maintains small queues, giving some confidence that this does not come at the cost of other competing flows. Note, there is little improvement at higher link rates since the application was limited to 3 Mbits/s and did not require any additional throughput.
1Goodput is the number of bytes/second that were successfully transmitted. Hence, it discounts for any retransmitted packets.
Image courtesy Nitin Garg, Yang Chi, Subodh Iyengar and the Facebook team
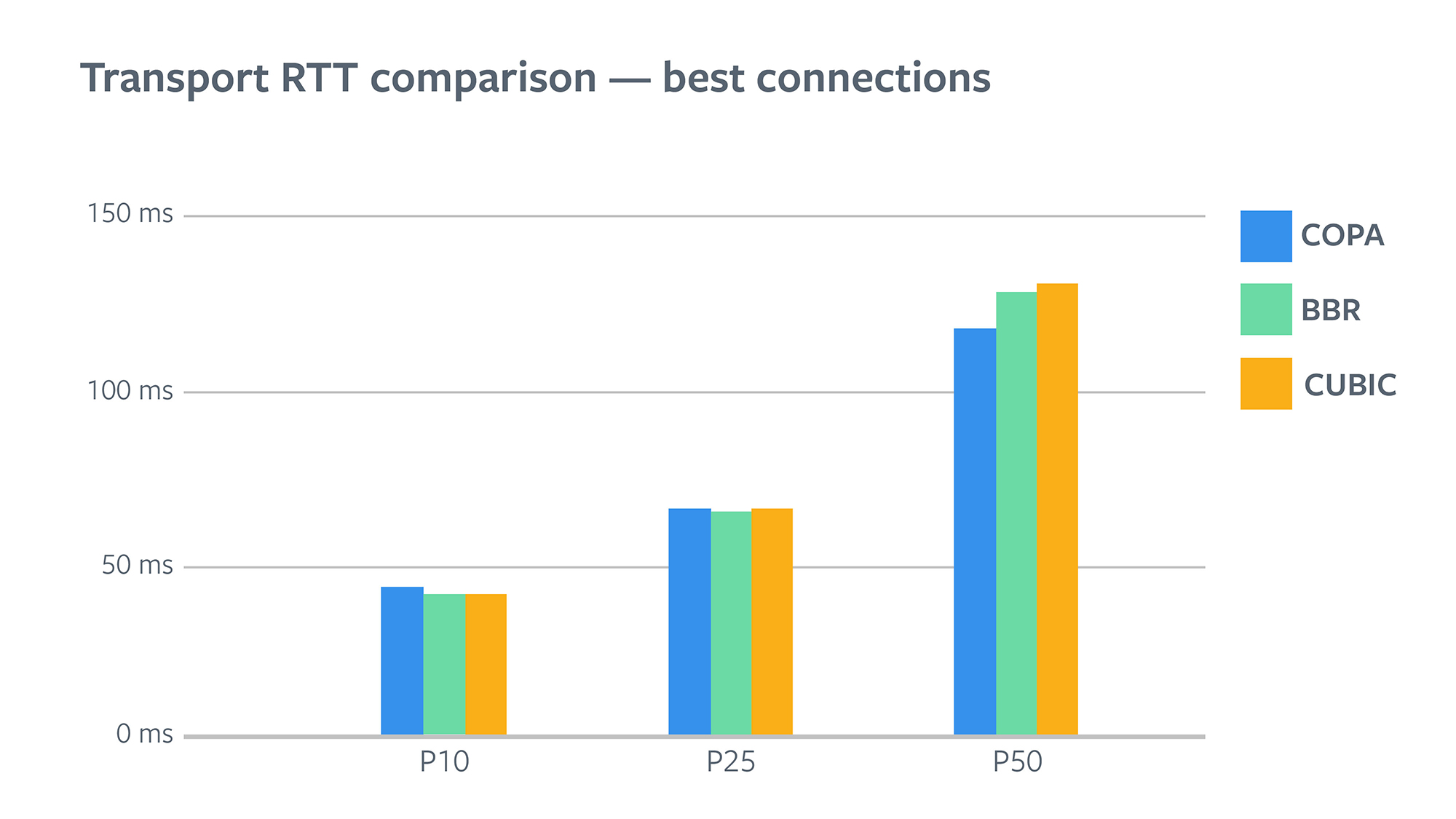
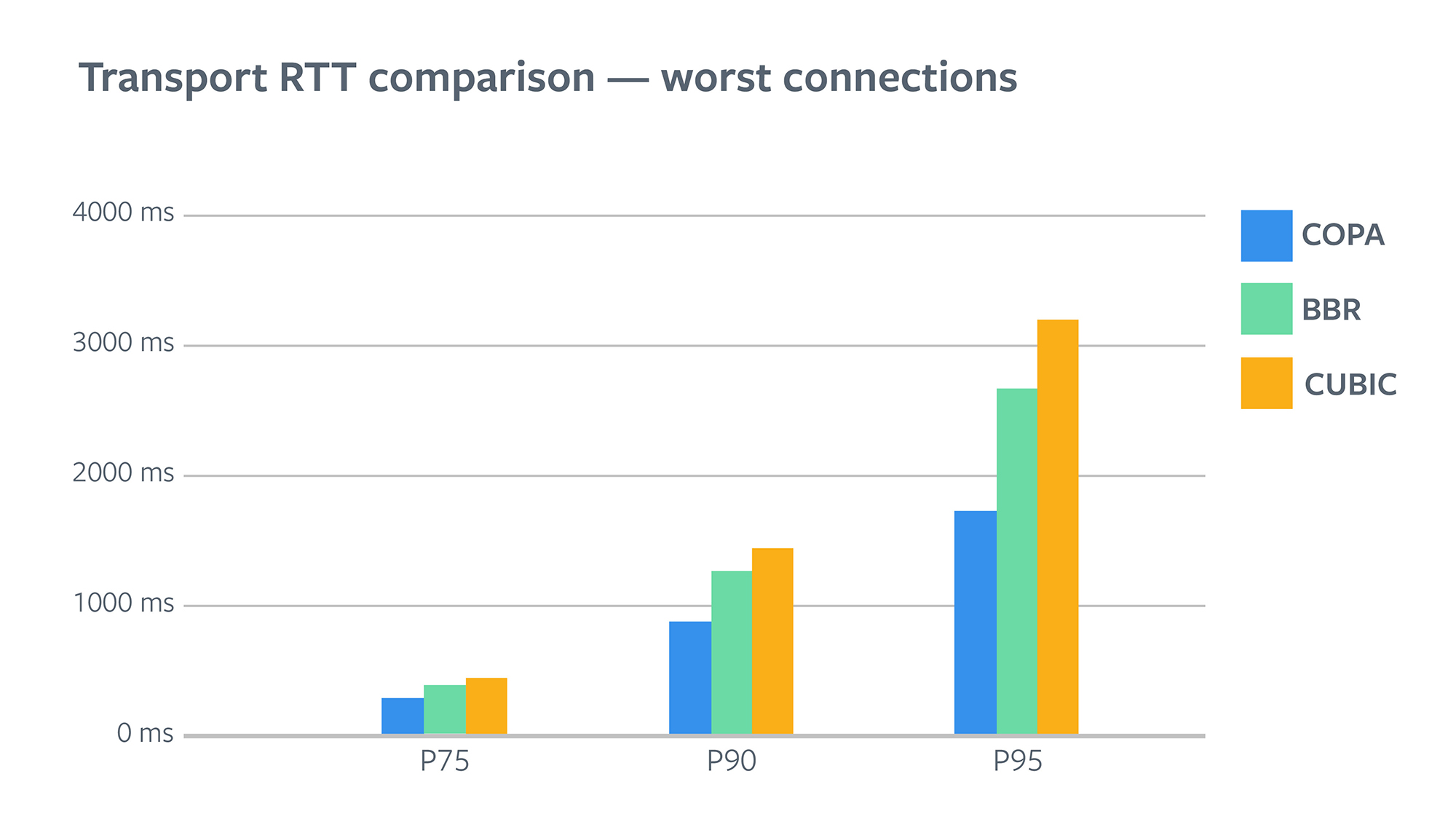
Copa significantly improves the RTT for connections that have the worst baseline RTTs, and hence most in need of improvement. For the worst connections, Copa reduces RTT by 35%-45%! Copa does this because it seeks to maintain small queues at the bottleneck link.
Image courtesy Nitin Garg, Yang Chi, Subodh Iyengar and the Facebook team
Note: The tested implementation does not include Copa's TCP mode switching behavior. In this case, Copa would get low throughput if a competing TCP were present. We believe this is rare on the internet, which is why overall performance isn't affected. Additionally, the implementation doesn't react to loss, which leads to high retransmission rates for bottleneck links with very short buffers. Our small-scale experiments show that this can be fixed by making Copa react to loss. Nevertheless, overall end-user metrics (video watch time) are higher for Copa in aggregate.
We thank Nitin Garg, Yang Chi, Subodh Iyengar and the Facebook team for this work. Their implementation of Copa can be found in mvfst, Facebook's QUIC implementation.
Copa Implementations
There are three implementations for Copa:
- Our UDP implementation: which is what we used for most experiments in our paper
- mvfst: Facebook's QUIC implementation
- CCP Copa: an implementation of Copa in CCP, a new API for writing congestion control algorithms. It provides a linux-kernel implementation for Copa. The code and documentation for CCP can be found here
Reproduce our results
Code for running many of our experiments can be found here. On Ubuntu, pre-requisite software can be installed as follows:
sudo apt-get install iperf tcptrace tcpdump libprotobuf-dev trash-cli python python-dpkt python-numpy
sudo add-apt-repository ppa:keithw/mahimahi
sudo apt-get update
sudo apt-get install mahimahi
Most of our evaluation in the paper uses a user-space UDP implementation, which can be found here. The core Copa logic is contained in the files markoviancc.[cc|hh] (the code refers to Copa as ‘markovian’). Installation instructions can be found in README.md. For example, The following command will run a Copa flow for 60 seconds
./sender serverip=100.64.0.1 offduration=0 onduration=60000 cctype=markovian delta_conf=do_ss:auto:0.5 traffic_params=deterministic,num_cycles=1
This should be run after running ‘./receiver’ on some node. 100.64.0.1 should be replaced with the IP address of the receiver. Note that delta_conf sets some parameters for Copa. do_ss instructs it to perform slow-start as opposed to an experimental fast-startup mechanism. auto:0.5 is the default Copa operation mode, where it automatically switches between TCP competitive and default modes. In default mode, it uses a delta of 0.5.
The mahimahi network emulator is a convenient tool for emulating networks. mm-delay 10 mm-link ~/traces/12Mbps ~/traces/12Mbps --uplink-queue=droptail --uplink-queue-args=bytes=60000 will run an emulator with a 12 Mbit/s link, where the file '~/traces/12Mbps’ contains the single ascii character ‘1’ (for 1 1500 byte packet per millisecond).
Using BBR requires Linux kernel version 4.9 or above. The kernel module can be loaded with modprobe tcp_bbr. The code for PCC can be found here. Our scripts in our CopaEvaluation repository expect some binaries in the directory ../bin. For Copa, it requires sender, for PCC, it requires appclient in ../bin and the senders' libudt.so in ../bin/pcc_sender (note that the PCC implementation creates different binaries of libudt.so for the sender and receiver).
The scripts expect receiver programs to be already running. Copa's receiver is the receiver binary produced by the makefile. Running the PCC requires export LD_LIBRARY_PATH=pcc_receiver && ./appserver, where pcc_receiver is the directory in which the receiver's libudt.so is located. Linux Kernel implementations are used for Cubic, Reno, BBR and Vegas, run using iperf, so iperf -s should be run on the receive side. For figures 3, 7 and 9, run the the receivers on the local machine. After this, run the scripts experiment-dynamic.sh, ./experiment-loss run and ./experiment-satellite run respectively. The graph command graphs the results in each of the scripts.
Figure 10 requires the use of two machines, one for senders and one for receivers. It is important that these machines be connected by a quiet, high-speed network, so that the emulated network, not the network connecting the machines is the bottleneck. It requires two iperf servers to be running on ports 5011 and 5010 (using the -p flag). Replace the variable receiver_ip with the IP address of the receiver in the script ./experiment-tcp-compatibility and run it. It should produce output sub-directories, one for each protocol, in the directory TcpCompatibility. These can be plotted using experiment-tcp-compatibility-plot.py, which takes the subdirectory as an argument.