Selected Projects
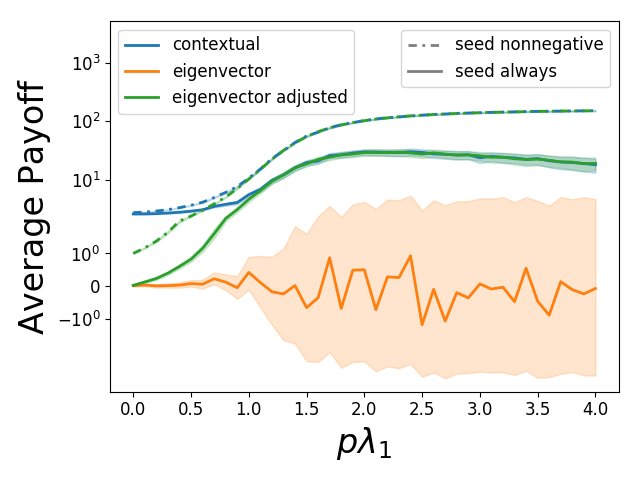
Contextual centrality: going beyond network structure
Centrality is a fundamental network property which ranks nodes by their structural importance. However, this alone may not predict successful diffusion in many applications, such as viral marketing and political campaigns. We propose contextual centrality, which integrates structural positions, the diffusion process, and, most importantly, relevant node characteristics. It nicely generalizes and relates to standard centrality measures. We test the effectiveness of contextual centrality in predicting the eventual outcomes in the adoption of microfinance and weather insurance. Our empirical analysis shows that the contextual centrality of first-informed individuals has higher predictive power than that of other standard centrality measures. Further simulations show that when the diffusion occurs locally, contextual centrality can identify nodes whose local neighborhoods contribute positively. When the diffusion occurs globally, contextual centrality signals whether diffusion may generate negative consequences. Contextual centrality captures more complicated dynamics on networks and has significant implications for network-based interventions. Scientific Reports.
Learning quadratic games on networks
Individuals, or organizations, cooperate with or compete against one another in a wide range of practical situations. The understanding of such strategic interactions plays a crucial role in modeling the collective decision-making process. Strategic interactions are commonly modeled and analyzed as games played on networks, which are assumed known a priori.
We tackle the inverse problem and propose a novel framework for learning quadratic network games, in particular, the structure of the network, based on the Nash equilibrium of such games, and test the framework on real-world examples showing that it outperforms existing methods by accounting for strategic dependencies of actions. The proposed framework has both theoretical and practical implications for understanding strategic interactions in a network environment.
Thirty-Seventh International Conference on Machine Learning (ICML) 2020.
Here is my 5-min talk at the Imagination in Action event at MIT Media Lab.
Please reach out if you are interested in extending this work to generalized network games using deep learning.
Calibration of heterogeneous treatment effect
Using machine learning to estimate the heterogeneity of treatment effects (HTE) in randomized experiments is a common practice when seeking to understand how units differ in their response to treatment. These models are then often used to construct personalized policies (for instance, by enabling a feature only for those users who are estimated to have a positive treatment effect).
Unfortunately, many of these models have no guarantees of unbiasedness for estimating the aggregate effects of subgroups. We provide a simple way to calibrate black-box estimates of HTEs to known unbiased average effect estimates, ensuring that sign and magnitude best approximate these non-parametrically identified estimates. Our method is a combination of histogram-binning and the Platt scaling technique used in supervised learning. It requires no additional data beyond that necessary for estimating HTEs, and it can be trivially scaled to arbitrarily large datasets.We show that it provides great benefits in ensuring that aggregated effects from HTE models align with the experimental benchmarks. Under review. Available upon request.
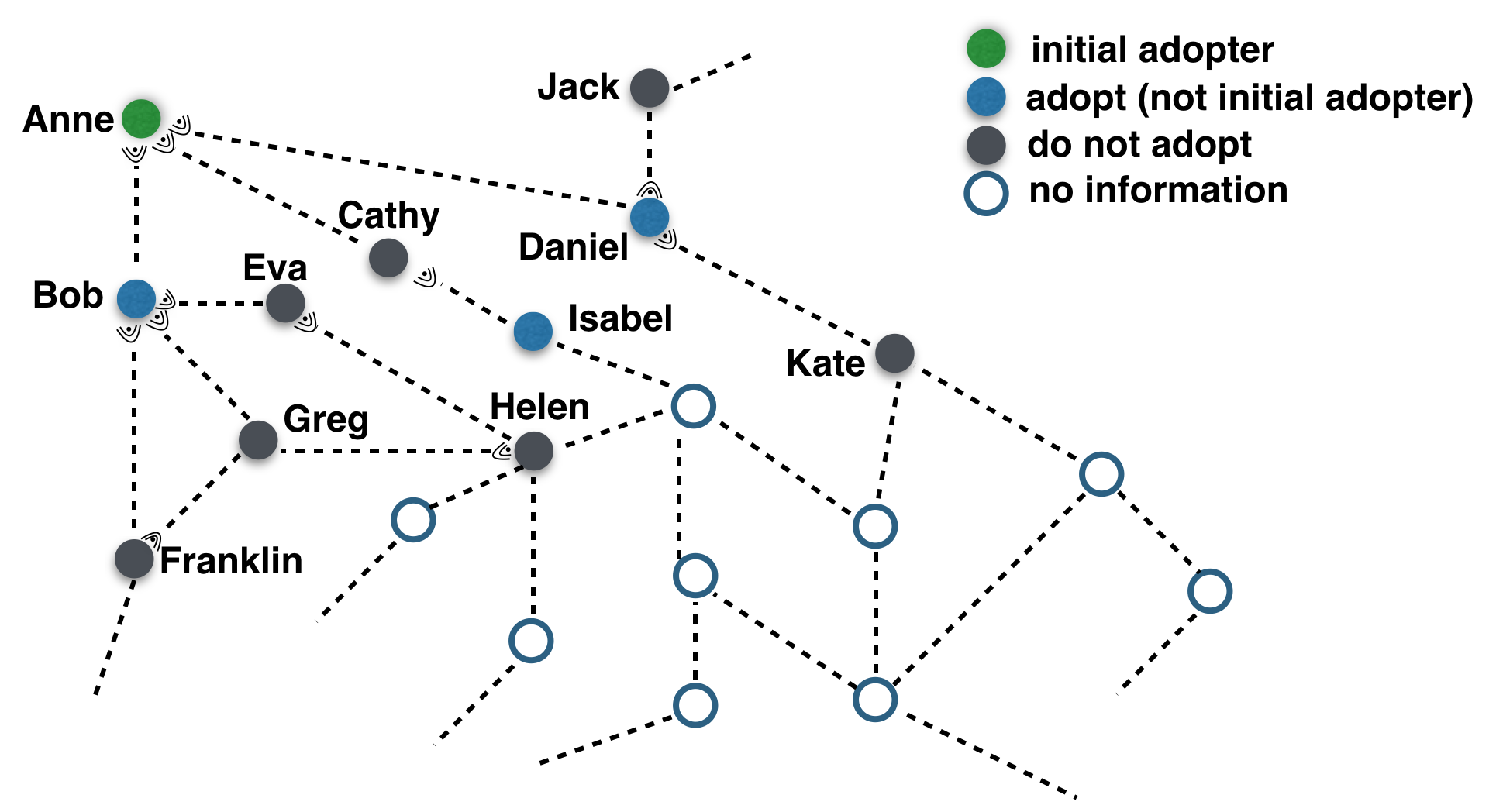
The Ripple Effect of Social Influence in Phone Networks
Several empirical works have shown that social influence propagates beyond direct neighbors in relatively costless online decision-making settings mainly due to the exposure effect explained by simple or complex contagion. Yet precisely how influence plays a role in costly offline behaviors and propagates through a social network and especially what is the underlying mechanisms that drive such propagation remain unclear. In this study, we leverage a high-resolution mobile phone data and a new behavioral matching method, based on revealed preference theory, to study how social influence propagates and affects individual off-line behavior. Our results show that propagation within the network persists in shaping individual decision-making through up to more than three degrees of separation regarding attending an international cultural performance in Andorra degrees of separation and regarding visiting a newly opened retail store in Mérida, Mexico. We find that exposure to behavior does not suffice to explain this social influence’s ripple effect, but it can be rather explained by a compound mechanism based on local communication and information aggregation. Based on those ideas we propose a Bayesian network-based learning model that can better predict individual adoption behavior than exposure-based models. This means that social learning is a paramount ingredient to understand the diffusion of influence in social networks, and it might have far-reaching implications in such domains as viral marketing, public health management, political campaign, and social mobilization, where it is often desirable to trigger a costly behavioral change in large-scale populations. Shorter version. Under review.
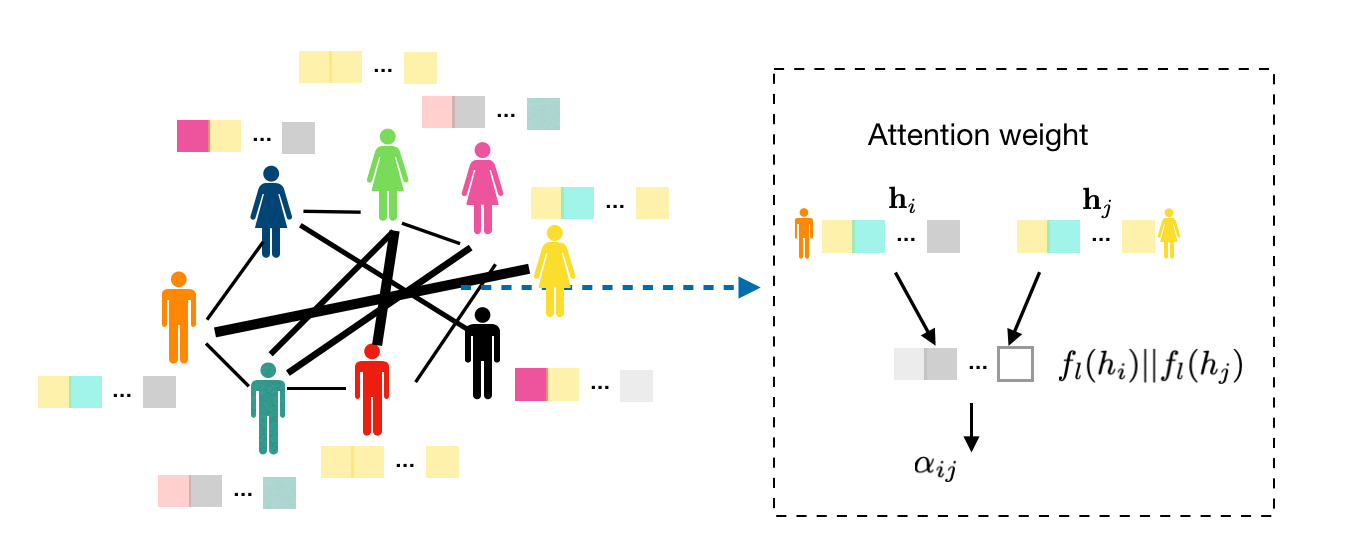
Recommender systems with heterogeneous information: A geometric deep learning approach
Many real-world data cover multiple aspects of consumer behaviors and business characteristics, creating opportunities for marketing companies to better understand the demand and preferences of customers with complementary information. However, to effectively combine data with multi-modal nature and complex structure is challenging. In this study, we propose a novel geometric deep learning framework for building effective recommender systems by predicting customers' preferences on businesses they have not yet rated. The proposed framework is capable of handling heterogeneous and auxiliary information on businesses and customers, and at the same time enforcing that only information relevant to the prediction task will be utilized. We compare the proposed framework with several baseline models in a prediction task using the Yelp open data set, where the improved performance of our method highlights the advantage of incorporating spatial, temporal, network, and other types of data in a principled manner. The proposed framework can be further applied to help make more informed marketing and managerial decisions in a variety of domains where the fusion of heterogeneous and structured information could be beneficial. Draft.
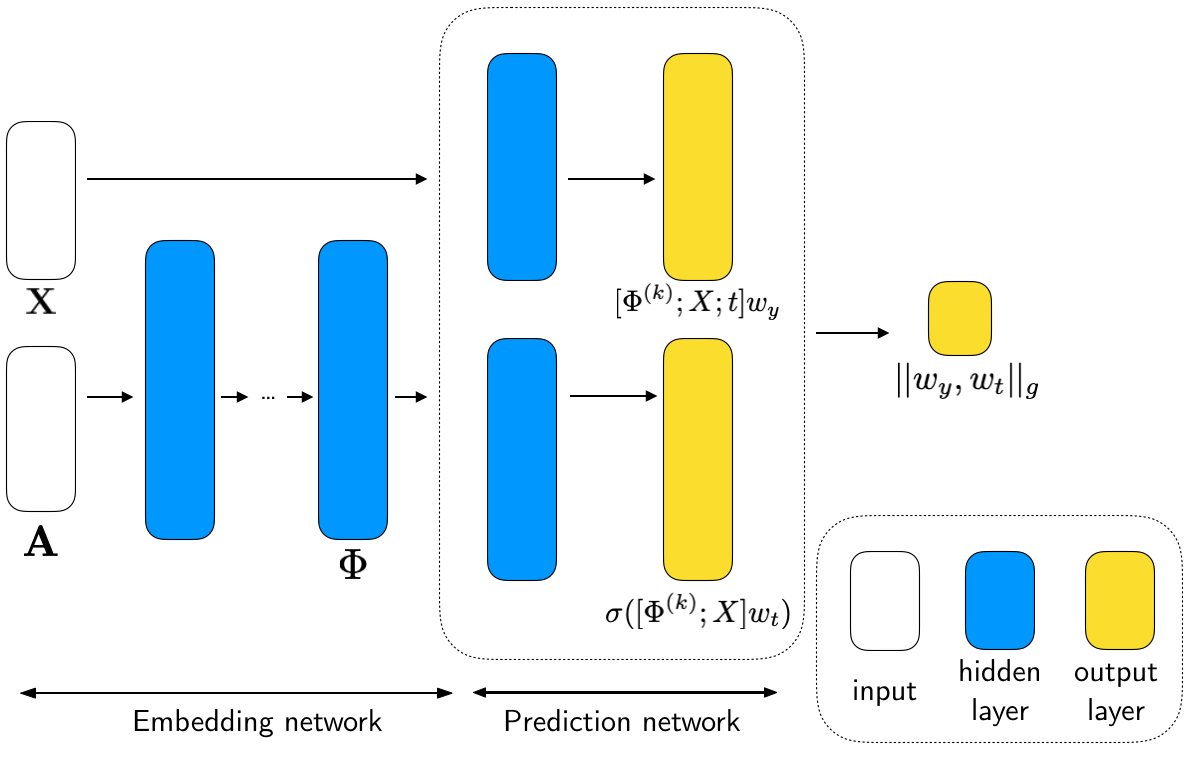
Observational causal inference using network information with unobserved confounding
Effective causal inference techniques in observational studies are highly desirable. The existence of unobserved confounding variables leads to selection bias and thus is the main challenge in causal inference. There has been a rich literature focusing on predicting the counterfactual outcomes using high-dimensional covariates as the control variables. However, this literature builds on the unconfoundedness assumption, which is unrealistic in practice. Even worse, controlling for covariates that are instrument variables may instead amplify the bias. We propose to use the social network for counterfactual prediction, which may (i) encode information about the nodes' latent characteristics, and (ii) treatment may, by self-selection, be assigned to nodes according to one's network positions. We explore how we can use network information to improve causal inference. We propose a framework to address the bias amplification due to controlling for instruments or community-level fixed effects. In particular, we propose a representation learning approach with group lasso regularization, which ensures that the learned representations will associate highly with both the treatment and the outcome. Experiments on the Facebook 100 dataset demonstrate the effectiveness of our approach and illustrate the potential of using network information for observational inference in general. Available upon request.
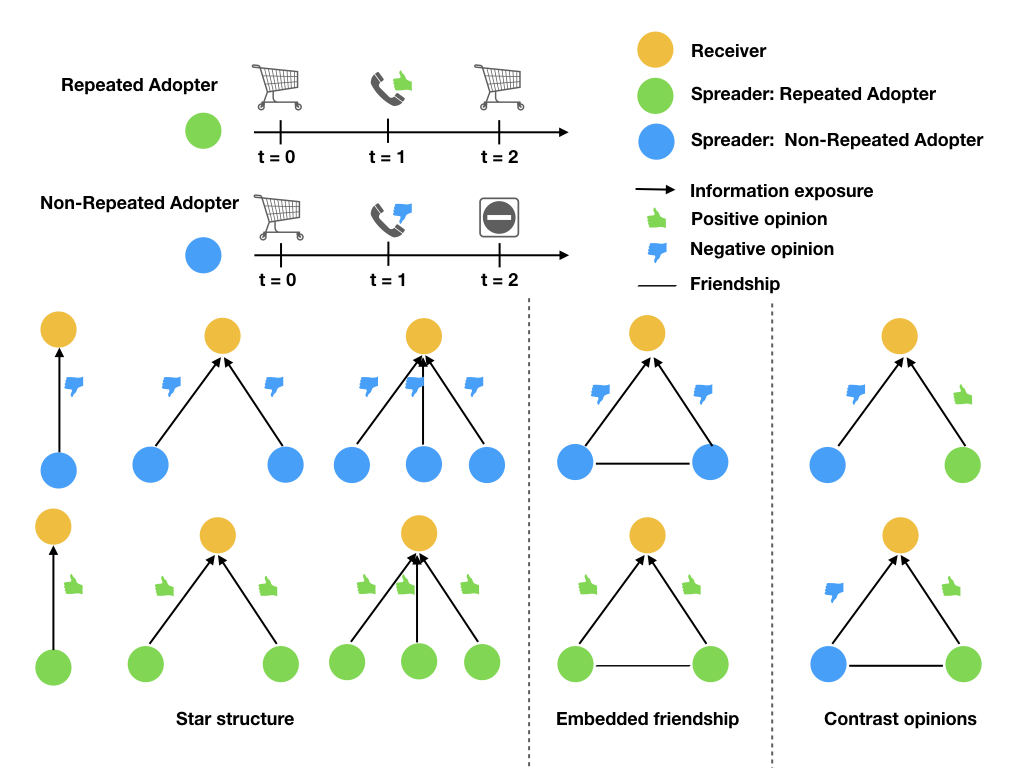
Beyond exposure: the paradoxical nature of social influence
Social influence manifests and drives the adoption decisions in a wide range of behaviors. The cascade model and complex contagion have been widely adopted to explain the diffusion of social influence. We argue that social influence goes beyond merely exposure. Preference elicitation, another form of social influence, potentially acts as an opposing effect to and jointly influences decision-making with exposure. However, unraveling the two effects is an empirically challenging task since they happen simultaneously during a conversation and the content of the conversation is hardly observed. We utilize future adoption decisions as the behavioral signal predicting the elicited preference. After controlling for observed covariates to isolate social influence with matched sampling, we observe a drastic difference in the adoption outcomes with ego network consists of different behavioral signals in three offline settings - visiting a newly-opened grocery store, adopting the micro-finance, and enrolling in weather insurance. To further disentangle the impacts of exposure and preference elicitation, we leverage the fixed effect of exposure to the existence of the product and the variation in ego network structures. With such a framework, we observe the paradoxical nature of social influence with the potential opposing effect of exposure and preference elicitation. Our study provides empirical evidence to enrich influence models and informs more effective interventions. Under review. Available upon request.
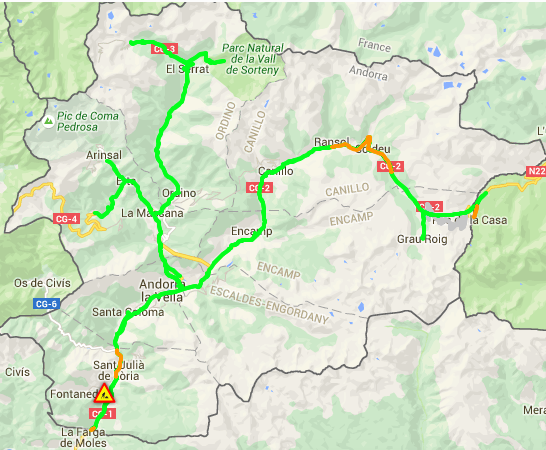
Synergistic data-driven travel demand management based on phone records
Traffic congestion has increasingly threatened urban development economically, societally, and environmentally. Leisure trips contribute to 79% of the total travel demand. However, leisure trips suffer from the ‘richer-get-richer’ effect, leading to congestion exacerbation. We address this issue with a novel data-driven travel demand management framework by recommending locations based on phone records. In particular, we infer unobserved location preferences using Matrix Factorization from longitudinal mobility histories. We then formulate a constrained optimization problem to maximize preferences regarding recommended locations while accounting for constraints imposed by road capacity. Our case study shows that under full compliance rate, congestion falls by 52% at the cost of 31% less location satisfaction. Under 60% compliance rate, 41% travel delay is saved with a 17% reduction in satisfaction. This study highlights the effectiveness of the synergy among collective behaviors in improving system efficiency.
Paper.
Bayesian Models of Cognition in the Wisdom of the Crowd
There is disagreement in the literature as to the role of social learning and influence on group accuracy. We believe that a missing piece of this line of research is to model of how humans update their belief distributions. Using a novel dataset (of 17K predictions from 2K people) that was collected in a series of live online experimental studies, we use models the literature of cognitive science to investigate how individuals learn from each other, and how they build belief distributions of the future prices of real assets (such as the S&P 500 and WTI Oil prices). Finally, we create a metric that estimates how much each individual prefers to use peer belief distributions instead of the past price distribution to update their belief, and we use this metric to filter for more ‘social-learning’ individuals in the group to see if their aggregate estimate is more accurate than that of the whole ‘crowd’. We observe that filtering using our novel metric outperforms other previous works’ metric of resistance to social influence (that we also reproduce), indicating that the ability to process social information is beneficial to group accuracy. We extend our finding to a very different domain and dataset where there is no explicit social information exposure by first estimating social-learning of individuals (using a hidden Markov model) and using it again to improve group accuracy, showing that finding individuals who are better at social learning can improve group accuracy in a very different domain. Under review. Available upon request.