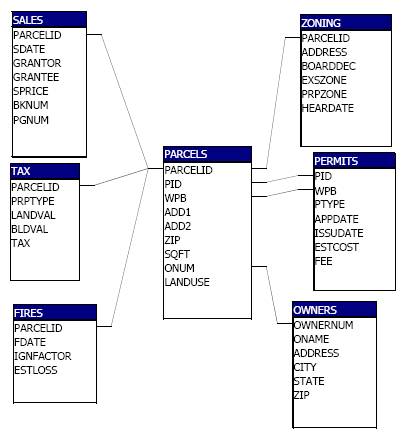
- JOINS among two or more tables are constrained by
- (a) specifying in the WHERE clause which columns in each table
must have matching values, or
- (b) using the alternate syntax: TABLE1 inner join TABLE2 on
TABLE1.ID = TABLE2.ID
- Note that the order of the SELECT clauses matters! The clauses, if
included, must appear in the order shown! Postgres will report an
error if you make a mistake, but the error message (e.g., "ERROR: syntax error at or near "from"; SQL state: 42601") may not be very
informative.
- Note that Postgres and MS-Access now support both ways
of expressing a join between two tables - hence most MS-Access
queries can be cut and pasted into Postgres (and vice-versa).
Handling one-to-many Relations: e.g., parcels & fires or parcels
& owners
- Parcels can have more than one fire and owners may own more than
one parcel.
- Handle such one-to-many relations by storing the data in two
separate tables: e.g., one table with a row for each parcel and
another table with a row for each fire (and another table with a row
for each owner).
- Join the tables via common attributes (parcelid) and use
aggregation functions (like count or sum) and the 'group by' clause
to answer questions that require combining across rows of the data after joining the
tables.
GROUP BY, and Aggregation Functions:
- When a SQL statement contains a GROUP BY clause,
- the rows are first filtered based on criteria in the WHERE
clause
- then rows are aggregated into groups that share common values
for the GROUP BY expressions
- The HAVING clause may be used to eliminate groups after
the aggregation has occurred.
These examples draw on the sample PARCELS database that we have used
previously.
| 1. List all the fires, including the date of the fire: |
2. List the count of fires by parcel: |
SELECT PARCELID, FDATE
FROM FIRES
ORDER BY PARCELID, FDATE;
|
SELECT PARCELID, COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
GROUP BY PARCELID
ORDER BY PARCELID;
|
|
Groups are shown in color, but this query
does not collapse groups into a single
row.
|
Groups and summary functions have been
calculated; notice that no FDATE values are shown. (Why? What summary of FDATE would make sense?)
|
| PARCELID |
FDATE |
| 2 |
02-AUG-88
|
| 2 |
02-APR-89
|
| 3 |
26-JUL-89
|
| 3 |
26-JUL-90
|
| 7 |
01-AUG-87
|
| 20 |
02-JUL-89
|
|
| PARCELID |
FIRE_COUNT |
| 2 |
2 |
| 3 |
2 |
| 7 |
1 |
| 20 |
1 |
|
The Different Roles of the WHERE Clause and the HAVING Clause
The WHERE clause restricts the rows that are processed before
any grouping occurs.
The HAVING clause is used with GROUP BY to limit the groups
returned after grouping has occurred.
| 3. List all the fires that occurred on or after 1 August
1988: |
4. List the count of fires that occurred on or after
1 August 1988 by parcel: |
5. List the count of fires that occurred on or after 1 August
1988 by parcel for parcels that had more than one fire: |
SELECT PARCELID, FDATE
FROM FIRES
WHERE FDATE >=
TO_DATE('01-AUG-1988',
'DD-MON-YYYY')
ORDER BY PARCELID, FDATE;
|
SELECT PARCELID,
COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
WHERE FDATE >=
TO_DATE('01-AUG-1988',
'DD-MON-YYYY')
GROUP BY PARCELID
ORDER BY PARCELID;
|
SELECT PARCELID,
COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
WHERE FDATE >=
TO_DATE('01-AUG-1988',
'DD-MON-YYYY')
GROUP BY PARCELID
HAVING COUNT(FDATE) > 1
ORDER BY PARCELID;
|
|
Groups are shown in color, but this query
does not actually perform grouping. Note that the fire at
parcel 7 on 1 August 1987 has been excluded by the WHERE
clause.
|
This query shows the result of grouping, but
no HAVING clause is applied. Groups that satisfy the HAVING
clause of Query 5 are shown in bold.
|
Final result, after groups that fail the
HAVING clause have been eliminated.
|
| PARCELID |
FDATE |
| 2 |
02-AUG-88
|
| 2 |
02-APR-89
|
| 3 |
26-JUL-89
|
| 3 |
26-JUL-90
|
| 20 |
02-JUL-89
|
|
| PARCELID |
FIRE_COUNT |
| 2 |
2 |
| 3 |
2 |
| 20 |
1 |
|
| PARCELID |
FIRE_COUNT |
| 2 |
2 |
| 3 |
2 |
|
Rules for GROUP BY Queries
- In a GROUP BY query, all expressions in the SELECT list not
containing group functions (SUM, AVG, COUNT, etc.) must
appear in the GROUP BY clause.
The following query is invalid because it includes a column (FDATE)
that is not in the GROUP BY clause. This query will fail with the
Oracle error "ERROR: column "fires.fdate" must appear in the GROUP BY clause or be used in an aggregate function":
SELECT PARCELID, FDATE, COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
GROUP BY PARCELID
ORDER BY PARCELID, FDATE;
Think for a minute why this query does not make sense. For each distinct
value of PARCELID, there may be multiple values of FDATE. For example,
the parcel with PARCELID = 2 had fires on both 2 Aug. 1988 and 2 Apr.
1989. When we group by PARCELID alone, the results of the query will
have at most one row for each value of PARCELID. If we include
FDATE in the SELECT list, which FDATE should Oracle pick for PARCELID
= 2? The answer is undefined, and that is why the query is invalid. Oracle
is unable to pick a single value of an unaggregated item to
represent a group.
To fix this query, we must ensure that the SELECT list and the GROUP
BY clause contain the same expressions (excluding expressions that use
group functions such as COUNT(FDATE)).We have two choices. First, we
can remove FDATE from the SELECT list (and the ORDER BY clause):
SELECT PARCELID, COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
GROUP BY PARCELID
ORDER BY PARCELID;
Second, we can add FDATE to the GROUP BY clause:
SELECT PARCELID, FDATE, COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
GROUP BY PARCELID, FDATE
ORDER BY PARCELID, FDATE
Be careful when picking this second option! Adding a column to the GROUP
BY clause may change the meaning of your groups, as in this example.
Notice that all the FIRE_COUNT values for this last query are 1.That's
because by adding FDATE to the GROUP BY clause we have effectively made
each group a single row from the FIRES table--not very interesting!
- All GROUP BY expressions should appear in the SELECT list.
(How else will you know what group is being shown?)
To find the names of the owners of exactly one parcel, we can use
this query:
SELECT OWNERS.ONAME, COUNT(*) AS PARCEL_COUNT
FROM PARCELS, OWNERS
WHERE PARCELS.ONUM = OWNERS.OWNERNUM
GROUP BY OWNERS.ONAME
HAVING COUNT(*) = 1;
The query below is valid, but uninformative. Who are the single-parcel
owners?
SELECT COUNT(*) AS PARCEL_COUNT
FROM PARCELS, OWNERS
WHERE PARCELS.ONUM = OWNERS.OWNERNUM
GROUP BY OWNERS.ONAME
HAVING COUNT(*) = 1;
Showing the count of parcels when we've restricted the parcel count to
1 is not very interesting. We can simply leave the count out of the
SELECT list. Note that you can use a HAVING condition without
including the group function in the SELECT list:
SELECT OWNERS.ONAME
FROM PARCELS, OWNERS
WHERE PARCELS.ONUM = OWNERS.OWNERNUM
GROUP BY OWNERS.ONAME
HAVING COUNT(*) = 1;
- GROUP BY expressions can be more elaborate than simple column
references.
Expressions such as
COL1 + COL2
|
(the sum of two columns) |
COL1 || COL2 || COL3
|
(three columns concatenated together) |
are also valid in the GROUP BY clause. As noted above, the expression
should appear both in the GROUP BY clause and in the
SELECT list. A column alias, while valid in the SELECT list, may not
be used in the GROUP BY clause. You must repeat the entire
expression from the SELECT list in the GROUP BY clause. Note, however,
that a column alias is valid in the ORDER BY clause.
Suppose we want to count the parcel owners based on the city and state
they live in, formatting the city and state as "City, State" (e.g.,
"BOSTON, MA"). The query below is valid:
SELECT CITY || ', ' || STATE AS CITY_STATE,
COUNT(*) OWNERS
FROM OWNERS
GROUP BY CITY || ', ' || STATE
ORDER BY CITY_STATE;
CITY_STATE OWNERS
------------------------ ----------
BOSTON, MA 8
BROOKLYN, NY 1
BURLINGTON, VT 1
NEW YORK, NY 1
The query below will fail for some database managers (but works in Postgres) because "CITY_STATE" is merely a column alias, not a real
column. (Curiously, column aliases are always valid in the ORDER BY
clause, as shown above.) Hence, it is good practice to include the original expression in the GROUP BY clause as above:
SELECT CITY || ', ' || STATE AS CITY_STATE,
COUNT(*) OWNERS
FROM OWNERS
GROUP BY CITY_STATE
ORDER BY CITY_STATE;
The HAVING clause restricts the groups that are returned.
Do not confuse it with the WHERE clause, which refers to the
original rows before they are aggregated. While you can use the HAVING
clause to screen out groups that the WHERE clause would have excluded,
the WHERE is more efficient than the GROUP BY clause, because it
operates while the rows are being retrieved and before they are
aggregated, while the HAVING clause operates only after the rows have
been retrieved and aggregated into groups.
The query below lists the count of fires by parcel, counting only
fires with a loss of at least $40,000:
SELECT PARCELID, COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
WHERE ESTLOSS >= 40000
GROUP BY PARCELID
ORDER BY PARCELID;
An incorrect way to attempt this query is to place the "ESTLOSS >=
40000" condition in the HAVING clause rather than the WHERE clause. The
following query will fail with the Postgres error "ERROR: column "fires.estloss" must appear in the GROUP BY clause or be used in an aggregate function" because we are attempting to exclude a group using a
column that is not part of the GROUP BY clause and hence out of context:
SELECT PARCELID, COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
GROUP BY PARCELID
HAVING ESTLOSS >= 40000
ORDER BY PARCELID;
Suppose we want to look at losses for fires by ignition factor
(IGNFACTOR), but want to ignore the case where IGNFACTOR is 2. We can
write this query two ways.
First, we can use a WHERE clause:
SELECT IGNFACTOR, COUNT(FDATE) AS FIRE_COUNT,
SUM(ESTLOSS) LOSSES
FROM FIRES
WHERE IGNFACTOR <> 2
GROUP BY IGNFACTOR
ORDER BY IGNFACTOR;
Second, we can use a HAVING clause:
SELECT IGNFACTOR, COUNT(FDATE) AS FIRE_COUNT,
SUM(ESTLOSS) LOSSES
FROM FIRES
GROUP BY IGNFACTOR
HAVING IGNFACTOR <> 2
ORDER BY IGNFACTOR;
Both of these queries return the same correct result, but the first
version using WHERE is more efficient because it screens out rows when
they are initially retrieved by the database engine, while the second
version using HAVING takes effect only after all the rows have been
retrieved and aggregated.This can make a big difference in performance in
a large database.
- Handling NULL & DISTINCT: Group
functions ignore NULL values.
Remember, however, that COUNT(*) counts rows, not any particular
column. Hence COUNT(*) is sometimes helpful when a particular column of
interest contains NULLs. This can lead to different results if you are
not careful. For example, the TAX table includes one row with no BLDVAL:
SELECT *
FROM TAX
WHERE BLDVAL IS NULL;
PARCELID PRPTYPE LANDVAL BLDVAL TAX
---------- ---------- ---------- ---------- ----------
20 9
N.B.: To find rows with NULLs in them, you must use the syntax
"expr IS NULL", as above. If you use "expr = NULL", the query will run
but not return any rows. The other comparison operators (e.g., =,
<>, !=, >, <, >=, <=, LIKE) will never match NULL.
For example, the query below executes but returns no rows:
SELECT COUNT(*)
FROM TAX;
COUNT(*)
----------
9
but if we count the building values we get a different one:
SELECT COUNT(BLDVAL)
FROM TAX;
COUNT(BLDVAL)
-------------
8
Values of ONUM in the PARCELS table are not unique. That explains why
COUNT(ONUM) and COUNT(DISTINCT ONUM) return different results in the
query below:
SELECT COUNT(ONUM) AS OWNERS,
COUNT(DISTINCT ONUM) AS DISTINCT_OWNERS
FROM PARCELS;
OWNERS DISTINCT_OWNERS
---------- ---------------
20 11
In the last three queries, we were treating the entire set of rows as a
single group (i.e., we used a group function such as COUNT without a
GROUP BY clause). Now let's use a GROUP BY to see if ownership of
properties in various land use categories is concentrated among a few
owners:
SELECT LANDUSE,
COUNT(*) AS PARCELS,
COUNT(ONUM) AS OWNERS,
COUNT(DISTINCT ONUM) AS DISTINCT_OWNERS
FROM PARCELS
GROUP BY LANDUSE;
LAN PARCELS OWNERS DISTINCT_OWNERS
--- ---------- ---------- ---------------
2 2 1
A 4 4 3
C 5 5 3
CL 1 1 1
CM 1 1 1
E 2 2 2
R1 2 2 2
R2 1 1 1
R3 2 2 2
9 rows selected.
Which value do we want to use for the count of owners, OWNERS or
DISTINCT_OWNERS? Why?
GROUP BY Examples
Find the parcels that experienced more than one fire:
SELECT PARCELID, COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
GROUP BY PARCELID
HAVING COUNT(FDATE) > 1
ORDER BY PARCELID;
List the fires with a loss of at least $40,000:
SELECT PARCELID, FDATE, ESTLOSS
FROM FIRES
WHERE ESTLOSS >= 40000
ORDER BY PARCELID, FDATE, ESTLOSS;
List the count of fires by parcel, counting only fires with a loss
of at least $40,000:
SELECT PARCELID, COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
WHERE ESTLOSS >= 40000
GROUP BY PARCELID
ORDER BY PARCELID;
Find the parcels that experienced more than one fire with a loss
of at least $40,000:
SELECT PARCELID, COUNT(FDATE) AS FIRE_COUNT
FROM FIRES
WHERE ESTLOSS >= 40000
GROUP BY PARCELID
HAVING COUNT(FDATE) > 1
ORDER BY PARCELID;
Advanced Queries: Self-Join:
Example: Did any parcel have a fire with little damage (< 10000) and a fire with lots of damage (>40000)
The following query does not work, because
it is not possible for value for a single column in a single row to
contain two values at the same time:
SELECT F1.PARCELID, FDATE
FROM FIRES
WHERE ESTLOSS < 10000
AND ESTLOSS >= 40000;
This type of query requires a self-join, which acts as if we had two
copies of the MATCH table and are joining them to each other.
SELECT F1.PARCELID, F1.FDATE AS small_FIRE, F2.FDATE AS big_FIRE
FROM FIRES F1, FIRES F2
WHERE F1.PARCELID = F2.PARCELID
AND F1.ESTLOSS < 10000
AND F2.ESTLOSS >= 40000
If you have trouble imagining the self-join, pretend that we actually
created two copies of MATCH, M1 and M2:
CREATE TABLE F1 AS
SELECT * FROM FIRES;
CREATE TABLE F2 AS
SELECT * FROM FIRES
Example: Find the time that passed between a fire on a parcel and all
fires occurring within 300 days later on the same parcel
SELECT F1.PARCELID, F1.FDATE AS FIRE1, F2.FDATE AS FIRE2,
F2.FDATE - F1.FDATE AS INTERVAL
FROM FIRES F1, FIRES F2
WHERE F1.PARCELID = F2.PARCELID
AND F2.FDATE > F1.FDATE
AND F2.FDATE <= F1.FDATE + 300;
Note that a number of days can be added to a date.
Advanced Queries: Subqueries
A subquery can be nested within a query
Example: Find the parcel with the highest estimated loss from a
fire
SELECT *
FROM FIRES
WHERE ESTLOSS =
(SELECT MAX(ESTLOSS)
FROM FIRES);
Alternatively, include the subquery as an inline "table" in the
FROM clause:
SELECT F.*
FROM FIRES F,
(SELECT MAX(ESTLOSS) MAXLOSS
FROM FIRES) M
WHERE F.ESTLOSS = M.MAXLOSS;
Example: Find the parcels that have not had a fire
SELECT *
FROM PARCELS
WHERE PARCELID NOT IN
(SELECT PARCELID
FROM FIRES);
or, more efficiently,
SELECT *
FROM PARCELS P
WHERE NOT EXISTS
(SELECT NULL
FROM FIRES F
WHERE P.PARCELID = F.PARCELID);
Example: Find the parcels that have not obtained a permit:
SELECT *
FROM PARCELS
WHERE (PID, WPB) NOT IN
(SELECT PID, WPB
FROM PERMITS);
or, more efficiently,
SELECT *
FROM PARCELS P
WHERE NOT EXISTS
(SELECT NULL
FROM PERMITS T
WHERE P.PID = T.PID and P.WPB = T.WPB);
Lab #2 Discussion:
Make sure everyone has found and understands the pre-constructed q_condosum query saved in MS-Access
Developed by Joseph Ferreira and Tom
Grayson.
Last modified: Rounaq Basu February 12, 2018