Rocks Cluster Distribution: Users Guide: 
| ||
|---|---|---|
| Prev | Chapter 2. Start Computing | Next |
This section describes ways to scale up a HPL job on a Rocks cluster.
To get started, you can follow the instructions on how run a two-processor HPL job at Using Mpirun on Ethernet. Then, to scale up the number of processors, add more entries to your machines file. For example, to run a 4-processor job over compute nodes compute-0-0 and compute-0-1, put the following in your machines file:
compute-0-0 compute-0-0 compute-0-1 compute-0-1 |
Then you'll need to adjust the number of processors in HPL.dat:
change:
1 Ps 2 Qs |
to:
2 Ps 2 Qs |
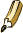 | The number of total processors HPL uses is computed by multiplying P times Q. That is, for a 16-processor job, you could specify:
|
And finally, you need adjust the np argument on the mpirun command line:
$ /opt/mpich/gnu/bin/mpirun -nolocal -np 4 -machinefile machines /opt/hpl/gnu/bin/xhpl |
To make the job run longer, you need to increase the problem size. This is done by increasing the Ns parameter. For example, to quadruple the amount of work each node performs:
change:
1000 Ns |
to:
2000 Ns |
| Keep in mind, doubling the Ns parameter quadruples the amount of work. |
 | For more information on the parameters in HPL.dat, see HPL Tuning. |
This section describes ways to scale up a HPL job on a Rocks cluster when submitting jobs through Grid Engine.
To get started, you can follow the instructions on how to scale up a HPL job at Interactive Mode. To increase the number of processors that the job uses, adjust HPL.dat (as described in Interactive Mode). Then get the file sge-qsub-test.sh (as described in launching batch jobs), and adjust the following parameter:
#$ -pe mpi 2 |
For example, if you want a 4-processor job, change the above line to:
#$ -pe mpi 4 |
Then submit your (bigger!) job to Grid Engine.
 | If you see in a error message in your output file that looks like:
or:
Then you'll need to increase the size of P4_GLOBMEMSIZE. To do that, edit sge-qsub-test.sh and increase value in the line:
Then resubmit the job to SGE. |