
[UPDATE Jan 2023] In 2021, the Omnipush dataset was hacked and, unfortunatelly, our backup storage system failed. So far, we can provide access to object models w/o weights , individual object parts , and the Video prediction dataset . WE ARE LOOKING FOR people that might have downloaded any of the remaining data before the hack . If that is you, please contact us if you could share back the data! Thank you all for understanding and helping when possible.
We introduce Omnipush, a dataset with high variety of planar pushing behavior.
The dataset contains 250 pushes for each of 250 objects, all recorded with RGB-D and high precision state tracking.
The objects are constructed to explore key factors that affect pushing --the shape of the object and its mass distribution--
which have not been broadly explored in previous datasets and allow to study generalization in model learning.
Paper: Omnipush: accurate, diverse, real-world
dataset of pushing dynamics with RGBD images. (PDF).
Maria Bauza, Ferran Alet, Yen-Chen Lin, Tomás Lozano-Pérez,
Leslie P. Kaelbling, Phillip Isola, and Alberto Rodriguez.
Contact: Maria Bauza (bauza@mit.edu)
[UPDATE Jan 2022] We have recovered access to: CAD models of the objects without etra weights , CAD models of the parts to build the objects , and Video prediction dataset . Please contact Maria Bauza (bauza@mit.edu) if you would need other data.
[IMPORTANT] DATA ACCESS: Unfortunately, the Omnipush dataset was hacked and corrupted on Aug 13th, 2021. We are currently working on backing up all data. Meanwhile, please contact Maria Bauza (bauza@mit.edu) to access the Omnipush data. The links below might still lead to corrupted data. We apologize for any inconvenience this may cause.
Dataset description
We split the datasets in 7 types
- 0_weight, 1_weight, 2_weight: 250 pushes for 250 obecjts. The name of the dataset indicates the number of extra weights added to the objects it contains. In this case, for each object there are 250 pushes.
- plywood, old, old_plywood: 250 pushes for out-of-distribution objects and surface. These datasets contain pushes that were recorded with out-of-distribution objects (old and old_plywood) and/or on an out-of-distrubtionon surface (plywood and old_plywood). For each object considered, there are 250 pushes.
- bias: 2500 pushes for 5 objects. For 5 objects we collected a larger dataset with 2500 additional pushes for each.
Data formats
- bag: raw data from each push with object and pusher poses and RGB-D images.
- hdf5, json: raw data except for the RGB-D images. This means that they include object poses as well as tip poses.
- json_simple: initial and final poses of the object and pusher.
- color_img: initial and final RGB images of each push.
Datasets used for benchmarking and other useful data
- Model prediction data: normalized data of the full dataset of initial and final object and pusher poses. Used for the model prediction benchmark. The non-normalized version of the data is in the folder processed_data .
- Video prediction dataset: contains the dataset used in the video prediction benchmark.
- CAD_models, top-down_view: CAD model and top-down view of each object in the dataset.
- Example on how to download the folder with all CAD models: on a terminal, wget -r ftp://omnipush.mit.edu/omnipush/CAD_models
- The downloading process might take a while, please contact us if you have any issues.
Content of the model prediction dataset
Inside the folder processed_data you will find all the data for each of the 7 datasets. For each object, we provide 6 different files depending on whether they contain input or output information, and the number of dimensions considered to represent the pushes.- 6 files per object: 2 (input,output) * 3 (3,5,7 input dimensions).
In general, you will only need 2 of those. For instance, object_X_3.npy for the input and object_Y_3.npy for the ouput is the most compact version with only 3 input dimensions. You can find more details on what each dimension represents in here (paper PDF).
Data capturing setup

About the surfaces
The surface used for most experiments is ABS. You can get the same material from McMaster (US vendor):
ABS.
In the datasets plywood and old_plywood we considered a surface made of
plywood.
About the objects
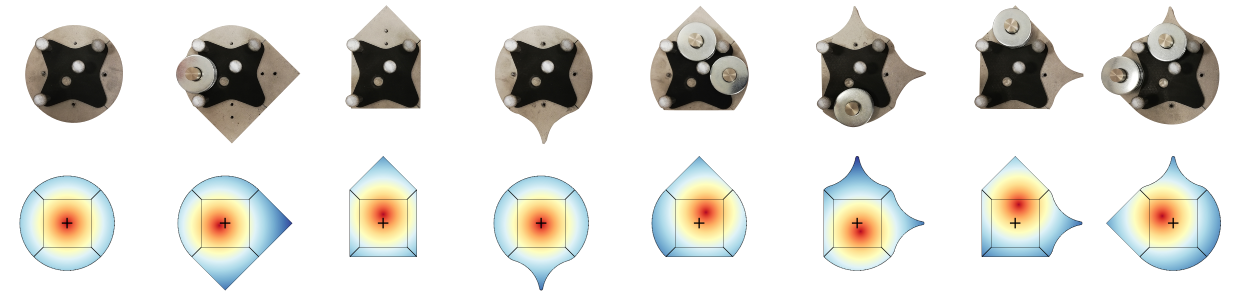
We have used 250 new objects to record this dataset. In the picture below, you can see some examples of the shapes considered for these objects.


Each object is built by magnetically attaching different sides to a central piece.
Additonally, the sides can carry extra weight which allows us to alter the mass distribution.
Object Name Convention
Each side type is described by a number: 1 (concave), 2 (triangular), 3 (circular), and 4 (rectangular). The additional weight is described by letters a, b, or c where a means the side does not carry extra weight, b small weight, and c big weight. If b or c are capitalized (B or C) it means that the weight is placed further away from the center. Only side 2 (triangular) has this option.The object below has the name 1a3a4a2B. You can also see its generated CAD model.

We provide CAD_models and top-down_views of each object in the dataset.
Code
We provide code
for the meta-learning baseline on prediction and code for video prediction.
We also provide a rendering script in Python to visualize different shapes: visualization code.
And processing code to exemplify how to process the bag files and visualize both
the RGB images and the ground truth poses from state tracking. Below there is an example of the videos that can be generated using the code:

The RGB-D camera for data collection is an Intel Realsense Camera D415 mounted with the following properties:
Intrinsics, camera matrix: [ [619.1314086914062, 0.0, 331.664428710937], [0.0, 618.7793579101562, 237.65293884277344], [0.0, 0.0, 1.0] ]
Extrinsics: [0.0023272667674563447, -0.06900554474977508, 1.0925066145059459, 0.6421809348136694, 0.5936457170366655, -0.29445740216220995, 0.3853352409496794]
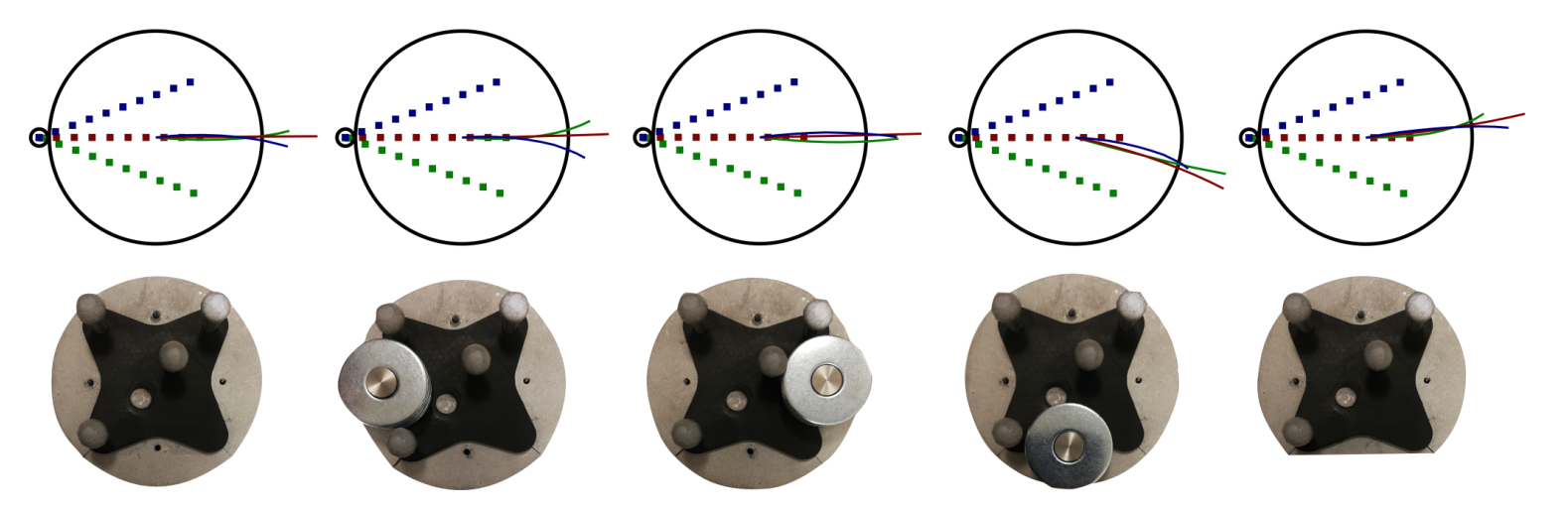
Mass distribution effect on dynamics
This dataset allows to study the effect of the mass ditribution on the motion of objects.
Results on benchmarks
Meta-learning benchmark
| Dataset | Meta-learning | NLPD | RMSE | Dist. equivalent |
|---|---|---|---|---|
| Zero: Normal(0,1) | - | 4.25 | .997 | 21.9 mm |
| Upperbound on Bayes error | - | < -2.15 | .165 | 3.6mm |
| Omnipush | no | 0.16 | .225 | 7.2mm |
| Omnipush | yes | -0.11 | .328 | 4.9mm |
| Out-of-distribution | no | 2.46 | .516 | 11.2 mm |
| Out-of-distribution | yes | 2.33 | .469 | 10.3mm |
Sharing reflections on the data collection
As it is well-known in the robotics community, collecting accurate robotic data is hard and demanding. Below we detail
some of our experiences and conclusions after collecting the Omnipush dataset:
1. It takes time: collecting the final version of this dataset took 12 hours a day for 2 weeks, i.e., more than 150 hours.
Planning as accurately as possible how much time it will take can prevent you from aiming at something that is unfeasible. Try to be realistic, unexpected things happen.
In our case, data collection for each object takes around 15min, so figuring out how to be efficient doing other things while also collecting data became really important.
2. Check everything: To make the system as autonomous as possible we had, for instance, to check continuously that all
sensors worked (RGBD camera, tracking system, robot), that the frequency was good and that the memory space was enough. Collect a few times a small amount of data before
collecting a large amount of data, even subtle errors can force you to recollect it all.
Similarly, make sure to avoid the possibility of any robot collision or object falling outside the workspace even when sensors are unaccurate.
3. Automate as much as possible: Minimal human intervention is key beyond expected. Human intervention can add unexpected
errors including setting the wrong object or moving calibrated cameras. For the Omnipush dataset, we made sure that we had properly built all objects
by checking the first collected image of that object. We realized that 5 objects had been wrongly assembled and had to recollect data for them.
4. Process some data beforehand: collecting all the dataset before using any of the data is a bad idea.
Some questions that can be answered almost from the beginning:
Does the recording frequency match the desired one? How frequent are the errors in the data? How many data files
do you expect to discard because of errors? Include those into your estimates of how long it will take to collect the data.
5. Hardware improvements save time: it is worth to think carefully on what could go wrong or will
need human intervention, and try to find ways to change the setup so that you can prevent or improve them.
In our system, we can relocate the object at the center of the workspace every time it gets close to its edges by adding a circular
spot that the pusher can engage to move the object. Also, hardware can break, have replacements.