


6.4.13 Multidepot VRPThe existence of multiple depots (or multiple origins in unconstrained, traveling-salesman-type problems) poses the additional requirement of assigning demand points to specific depots. This new "degree of freedom" further increases the computational complexity of the problem. The approach to multidepot VRP problems so far has been based entirely on heuristic algorithms, of which the most common are of the "cluster first, route second" variety: first, demand points are assigned to depots; then, single depot VRP's are solved for each depot. The best known of these approaches [GILL 74a] assigns demand points to depots
in the following way: For each demand point i, we compute the quantity
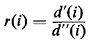
where d'(i) and d''(i) are the distances from i to the nearest and second
nearest of its depots. A threshold value An extension of the savings algorithm to multidepot VRP's that avoids the early partitioning of the demand points into clusters around depots has also been developed [TILL 72]. The latter algorithm has been recently combined with the cluster-forming approach outlined above into an efficient algorithm capable of handling large-scale problems [GOLD 76]. |
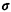 such that 0 <
such that 0 <
