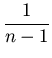The most commonly used measure of variation (dispersion) is the
sample standard deviation, ![]() . The square of the sample
standard deviation is called the sample variance, defined as2
. The square of the sample
standard deviation is called the sample variance, defined as2
| = | |||
| = |
|||
| = ( |
|||
| = ( |
(3) |
The advantage of Eq. 4 over Eq. 2 is that
it allows for the computation of
![]() xi2 required for the evaluation of
xi2 required for the evaluation of
![]() and
and ![]() xi required for the evaluation of
xi required for the evaluation of ![]() in one loop, whereas Eq. 2 requires the
precomputed value of
in one loop, whereas Eq. 2 requires the
precomputed value of ![]() before we can compute
before we can compute ![]() . For this
reason, Eq. 4 is used often in the computations of
the mean and variance.
. For this
reason, Eq. 4 is used often in the computations of
the mean and variance.
However, if you closely examine Eq. 2 and
Eq. 4, one important difference can be pointed out: Eq. 2
guarantees a non-negative variance because variance is given there as
the sum of squares. This is not necessarily true of Eq. 4
where we subtract
n(![]() xi)2 from
xi)2 from
![]() xi2.
From a computational perspective, we know that this can cause difficulties
for large samples prone to potential roundoff errors. So we are interested
in developing an algorithm which computes (a). both the mean and the variance
in the same loop and (b). variance as a sum of squares. How can this
be accomplished? Well, we can resort to developing recursive relations.
Applying Eq. 1 for the
the first p - 1 and p data and subtracting one from the
other, we get
xi2.
From a computational perspective, we know that this can cause difficulties
for large samples prone to potential roundoff errors. So we are interested
in developing an algorithm which computes (a). both the mean and the variance
in the same loop and (b). variance as a sum of squares. How can this
be accomplished? Well, we can resort to developing recursive relations.
Applying Eq. 1 for the
the first p - 1 and p data and subtracting one from the
other, we get
|
(p - 1) |
(7) |
The coefficient of variation of the sample data, denoted by CV is defined as
Note that CV is independent of the units of measurement.