Reading 6: Specifications
Java Tutor exercises
Keep making progress on Java by completing these categories in the Java Tutor:
Software in 6.031
| Safe from bugs | Easy to understand | Ready for change |
|---|---|---|
| Correct today and correct in the unknown future. | Communicating clearly with future programmers, including future you. | Designed to accommodate change without rewriting. |
Objectives
- Understand preconditions and postconditions in method specifications, and be able to write correct specifications
- Be able to write tests against a specification
- Know the difference between checked and unchecked exceptions in Java
- Understand how to use exceptions for special results
Introduction
Specifications are the linchpin of teamwork. It’s impossible to delegate responsibility for implementing a method without a specification. The specification acts as a contract: the implementer is responsible for meeting the contract, and a client that uses the method can rely on the contract. In fact, we’ll see that like real legal contracts, specifications place demands on both parties: when the specification has a precondition, the client has responsibilities too.
In this reading we’ll look at the role played by specifications of methods. We’ll discuss what preconditions and postconditions are, and what they mean for the implementer and the client of a method. We’ll also talk about how to use exceptions, an important language feature found in Java, Python, and many other modern languages, which allows us to make a method’s interface safer from bugs and easier to understand.
Before we dive into the structure and meaning of specifications…
Why specifications?
Many of the nastiest bugs in programs arise because of misunderstandings about behavior at the interface between two pieces of code. Although every programmer has specifications in mind, not all programmers write them down. As a result, different programmers on a team have different specifications in mind. When the program fails, it’s hard to determine where the error is. Precise specifications in the code let you apportion blame (to code fragments, not people!), and can spare you the agony of puzzling over where a fix should go.
Specifications are good for the client of a method because they spare the task of reading code. If you’re not convinced that reading a spec is easier than reading code, take a look at some of the standard Java specs and compare them to the source code that implements them.
Here’s an example of one method from BigInteger — a class for representing integers up to arbitrary size without the size limit of primitive int — next to its code:
Specification from the API documentation: add
Returns a BigInteger whose value is Parameters: Returns: |
Method body from Java 8 source: |
The spec for BigInteger.add is straightforward for clients to understand, and if we have questions about corner cases, the BigInteger class provides additional human-readable documentation.
If all we had was the code, we’d have to read through the BigInteger constructor, compareMagnitude, subtract, and trustedStripLeadingZeroInts just as a starting point.

Specifications are good for the implementer of a method because they give the implementer freedom to change the implementation without telling clients. Specifications can make code faster, too. We’ll see that using a weaker specification can rule out certain states in which a method might be called. This restriction on the inputs might allow the implementer to skip an expensive check that is no longer necessary and use a more efficient implementation.
The contract acts as a firewall between client and implementer. It shields the client from the details of the workings of the unit — you don’t need to read the source code of the procedure if you have its specification. And it shields the implementer from the details of the usage of the unit; he doesn’t have to ask every client how she plans to use the unit. This firewall results in decoupling, allowing the code of the unit and the code of a client to be changed independently, so long as the changes respect the specification — each obeying its obligation.
Behavioral equivalence
Consider these two methods. Are they the same or different?
static int findFirst(int[] arr, int val) {
for (int i = 0; i < arr.length; i++) {
if (arr[i] == val) return i;
}
return arr.length;
}
static int findLast(int[] arr, int val) {
for (int i = arr.length -1 ; i >= 0; i--) {
if (arr[i] == val) return i;
}
return -1;
}Of course the code is different, so in that sense they are different; and we’ve given them different names, just for the purpose of discussion. To determine behavioral equivalence, our question is whether we could substitute one implementation for the other.
Not only do these methods have different code, they actually have different behavior:
- when
valis missing,findFirstreturns the length ofarrandfindLastreturns -1; - when
valappears twice,findFirstreturns the lower index andfindLastreturns the higher.
But when val occurs at exactly one index of the array, the two methods behave the same: they both return that index.
It may be that clients never rely on the behavior in the other cases.
Whenever they call the method, they will be passing in an arr with exactly one element val.
For such clients, these two methods are the same, and we could switch from one implementation to the other without issue.
The notion of equivalence is in the eye of the beholder — that is, the client. In order to make it possible to substitute one implementation for another, and to know when this is acceptable, we need a specification that states exactly what the client depends on.
In this case, our specification might be:
static int find(int[] arr, int val)- requires:
valoccurs exactly once inarr- effects:
- returns index
isuch thatarr[i]=val
reading exercises
static int findFirst(int[] a, int val) {
for (int i = 0; i < a.length; i++) {
if (a[i] == val) return i;
}
return a.length;
}static int findLast(int[] a, int val) {
for (int i = a.length - 1 ; i >= 0; i--) {
if (a[i] == val) return i;
}
return -1;
}As we said above, suppose clients only care about calling the find method when they know val occurs exactly once in a.
(missing explanation)
Now let’s change the spec.
Suppose clients only care that the find method should return:
- any index
isuch thata[i] == val, ifvalis ina - any integer
jsuch thatjis not a valid array index, otherwise
(missing explanation)

Specification structure
A specification of a method consists of several clauses:
- a precondition, indicated by the keyword requires
- a postcondition, indicated by the keyword effects
The precondition is an obligation on the client (i.e., the caller of the method). It’s a condition over the state in which the method is invoked.
The postcondition is an obligation on the implementer of the method. If the precondition holds for the invoking state, the method is obliged to obey the postcondition, by returning appropriate values, throwing specified exceptions, modifying or not modifying objects, and so on.

The overall structure is a logical implication: if the precondition holds when the method is called, then the postcondition must hold when the method completes.
If the precondition does not hold when the method is called, the implementation is not bound by the postcondition. It is free to do anything, including not terminating, throwing an exception, returning arbitrary results, making arbitrary modifications, etc.
reading exercises
Here’s the spec we’ve been looking at:
static int find(int[] arr, int val)- requires:
valoccurs exactly once inarr- effects:
- returns index
isuch thatarr[i]=val
(missing explanation)
(missing explanation)
Specifications in Java
Some languages (notably Eiffel) incorporate preconditions and postconditions as a fundamental part of the language, as expressions that the runtime system (or even the compiler) can automatically check to enforce the contracts between clients and implementers.
Java does not go quite so far, but its static type declarations are effectively part of the precondition and postcondition of a method, a part that is automatically checked and enforced by the compiler. The rest of the contract — the parts that we can’t write as types — must be described in a comment preceding the method, and generally depends on human beings to check it and guarantee it.
Java has a convention for documentation comments, in which parameters are described by @param clauses and results are described by @return clauses.
You should put the preconditions into @param where possible, and postconditions into @return.
So a specification like this:
static int find(int[] arr, int val)- requires:
valoccurs exactly once inarr- effects:
- returns index
isuch thatarr[i]=val
… might be rendered in Java like this:
/**
* Find a value in an array.
* @param arr array to search, requires that val occurs exactly once
* in arr
* @param val value to search for
* @return index i such that arr[i] = val
*/
static int find(int[] arr, int val)The Java API documentation is produced from Javadoc comments in the Java standard library source code. Documenting your specifications in Javadoc allows Eclipse to show you (and clients of your code) useful information, and allows you to produce HTML documentation in the same format as the Java API docs.
Read: Introduction, Commenting in Java, and Javadoc Comments in Javadoc Comments.
When writing your specifications, you can also refer to Oracle’s How to Write Doc Comments.
reading exercises
Given this spec:
static boolean isPalindrome(String word)- requires:
wordcontains only alphanumeric characters- effects:
- returns true if and only if
wordis a palindrome
(The correct lines taken together need not form a complete Javadoc comment.)
(missing explanation)
Null references
In Java, references to objects and arrays can also take on the special value null, which means that the reference doesn’t point to an object. Null values are an unfortunate hole in Java’s type system.
Primitives cannot be null:
int size = null; // illegal
double depth = null; // illegaland the compiler will reject such attempts with static errors.
On the other hand, we can assign null to any non-primitive variable:
String name = null;
int[] points = null;and the compiler happily accepts this code at compile time. But you’ll get errors at runtime because you can’t call any methods or use any fields with one of these references:
name.length() // throws NullPointerException
points.length // throws NullPointerExceptionNote, in particular, that null is not the same as an empty string "" or an empty array.
On an empty string or empty array, you can call methods and access fields.
The length of an empty array or an empty string is 0.
The length of a string variable that points to null isn’t anything: calling length() throws a NullPointerException.
Also note that arrays of non-primitives and collections like List might be non-null but contain null as a value:

String[] names = new String[] { null };
List<Double> sizes = new ArrayList<>();
sizes.add(null);These nulls are likely to cause errors as soon as someone tries to use the contents of the collection.
Null values are troublesome and unsafe, so much so that you’re well advised to remove them from your design vocabulary. In 6.031 — and in fact in most good Java programming — null values are implicitly disallowed in parameters and return values. So every method implicitly has a precondition on its object and array parameters that they be non-null. Every method that returns an object or an array implicitly has a postcondition that its return value is non-null. If a method allows null values for a parameter, it should explicitly state it, or if it might return a null value as a result, it should explicitly state it. But these are in general not good ideas. Avoid null.
There are extensions to Java that allow you to forbid null directly in the type declaration, e.g.:
static boolean addAll(@NonNull List<T> list1, @NonNull List<T> list2)where it can be checked automatically at compile time or runtime.
Google has their own discussion of null in Guava, the company’s core Java libraries.
The project explains:
Careless use of
nullcan cause a staggering variety of bugs. Studying the Google code base, we found that something like 95% of collections weren’t supposed to have any null values in them, and having those fail fast rather than silently acceptnullwould have been helpful to developers.Additionally,
nullis unpleasantly ambiguous. It’s rarely obvious what anullreturn value is supposed to mean — for example,Map.get(key)can returnnulleither because the value in the map isnull, or the value is not in the map. Null can mean failure, can mean success, can mean almost anything. Using something other thannullmakes your meaning clear.
(Emphasis added.)
reading exercises
If you’re not sure, try it yourself in a small Java program.
Check all that apply:
(missing explanation)
public static String none() {
return null; // (1)
}
public static void main(String[] args) {
String a = none(); // (2)
String b = null; // (3)
if (a.length() > 0) { // (4)
b = a; // (5)
}
return b; // (6)
}(missing explanation)
If we comment out that line and run main…
(missing explanation)

What a specification may talk about
A specification of a method can talk about the parameters and return value of the method, but it should never talk about local variables of the method or private fields of the method’s class. You should consider the implementation invisible to the reader of the spec.
In Java, the source code of the method is often unavailable to the reader of your spec, because the Javadoc tool extracts the spec comments from your code and renders them as HTML.
Testing and specifications
In testing, we talk about black box tests that are chosen with only the specification in mind, and glass box tests that are chosen with knowledge of the actual implementation (Testing). But it’s important to note that even glass box tests must follow the specification. Your implementation may provide stronger guarantees than the specification calls for, or it may have specific behavior where the specification is undefined. But your test cases should not count on that behavior. Test cases must obey the contract, just like every other client.
For example, suppose you are testing this specification of find, slightly different from the one we’ve used so far:
static int find(int[] arr, int val)- requires:
valoccurs inarr- effects:
- returns index
isuch thatarr[i]=val
This spec has a strong precondition in the sense that val is required to be found; and it has a fairly weak postcondition in the sense that if val appears more than once in the array, this specification says nothing about which particular index of val is returned.
Even if you implemented find so that it always returns the lowest index, your test case can’t assume that specific behavior:
int[] array = new int[] { 7, 7, 7 };
assertEquals(0, find(array, 7)); // bad test case: violates the spec
assertEquals(7, array[find(array, 7)]); // correct
Similarly, even if you implemented find so that it (sensibly) throws an exception when val isn’t found, instead of returning some arbitrary misleading index, your test case can’t assume that behavior, because it can’t call find() in a way that violates the precondition.
So what does glass box testing mean, if it can’t go beyond the spec? It means you are trying to find new test cases that exercise different parts of the implementation, but still checking those test cases in an implementation-independent way.
Testing units
Recall the web search example from Testing with these methods:
/** @return the contents of the web page downloaded from url */
public static String getWebPage(URL url) { ... }
/** @return the words in string s, in the order they appear,
* where a word is a contiguous sequence of
* non-whitespace and non-punctuation characters */
public static List<String> extractWords(String s) { ... }
/** @return an index mapping a word to the set of URLs
* containing that word, for all webpages in the input set */
public static Map<String, Set<URL>> makeIndex(Set<URL> urls) {
...
calls getWebPage and extractWords
...
} We talked then about unit testing, the idea that we should write tests of each module of our program in isolation.
A good unit test is focused on just a single specification.
Our tests will nearly always rely on the specs of Java library methods, but a unit test for one method we’ve written shouldn’t fail if a different method fails to satisfy its spec.
As we saw in the example, a test for extractWords shouldn’t fail if getWebPage doesn’t satisfy its postcondition.
Good integration tests, tests that use a combination of modules, will make sure that our different methods have compatible specifications: callers and implementers of different methods are passing and returning values as the other expects.
Integration tests cannot replace systematically-designed unit tests.
From the example, if we only ever test extractWords by calling makeIndex, we will only test it on a potentially small part of its input space: inputs that are possible outputs of getWebPage.
In doing so, we’ve left a place for bugs to hide, ready to jump out when we use extractWords for a different purpose elsewhere in our program, or when getWebPage starts returning web pages written in a new format, etc.
Specifications for mutating methods
We previously discussed mutable vs. immutable objects, but our specifications of find didn’t give us the opportunity to illustrate how to describe side-effects — changes to mutable data — in the postcondition.
Here’s a specification that describes a method that mutates an object:
static boolean addAll(List<T> list1, List<T> list2)- requires:
list1!=list2- effects:
- modifies
list1by adding the elements oflist2to the end of it, and returns true iflist1changed as a result of call
We’ve taken this, slightly simplified, from the Java List interface.
First, look at the postcondition.
It gives two constraints: the first telling us how list1 is modified, and the second telling us how the return value is determined.
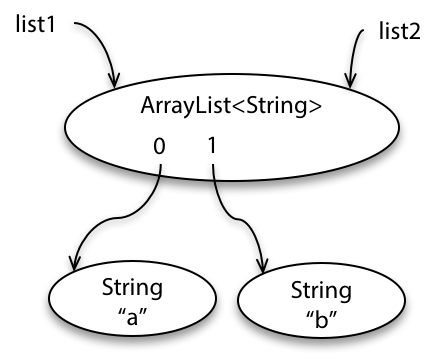
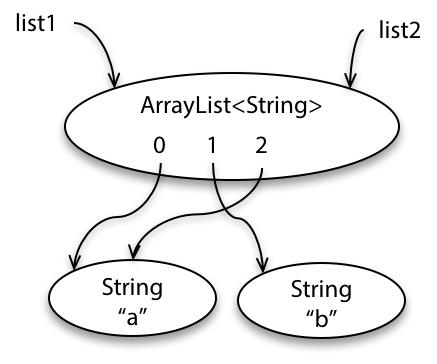
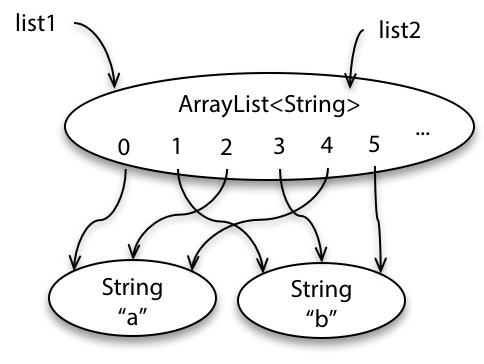
Second, look at the precondition.
It tells us that the behavior of the method if you attempt to add the elements of a list to itself is undefined.
You can easily imagine why the implementer of the method would want to impose this constraint: it’s not likely to rule out any useful applications of the method, and it makes it easier to implement.
The specification allows a simple implementation in which you take an element from list2 and add it to list1, then go on to the next element of list2 until you get to the end.
The sequence of snapshot diagrams at right illustrate this behavior.
So if list1 and list2 are the same list, this simple algorithm will not terminate — or practically speaking it will throw a memory error when the list object has grown so large that it consumes all available memory.
Either outcome, infinite loop or crash, is permitted by the specification because of its precondition.
Remember also our implicit precondition that list1 and list2 must be valid objects, rather than null.
We’ll usually omit saying this because it’s virtually always required of object references.
Here is another example of a mutating method:
static void sort(List<String> lst)- requires:
- nothing
- effects:
- puts
lstin sorted order, i.e.lst[i]≤lst[j]for all 0 ≤i<j<lst.size()
And an example of a method that does not mutate its argument:
static List<String> toLowerCase(List<String> lst)- requires:
- nothing
- effects:
- returns a new list
twheret[i]=lst[i].toLowerCase()
Just as we’ve said that null is implicitly disallowed unless stated otherwise, we will also use the convention that mutation is disallowed unless stated otherwise.
The spec of toLowerCase could explicitly state as an effect that “lst is not modified”, but in the absence of a postcondition describing mutation, we demand no mutation of the inputs.
reading exercises
(missing explanation)
Alice writes the following code:
public static int gcd(int a, int b) {
if (a > b) {
return gcd(a-b, b);
} else if (b > a) {
return gcd(a, b-a);
}
return a;
}Bob writes the following test:
@Test public void gcdTest() {
assertEquals(6, gcd(24, 54));
}The test passes!
Alice should write a > 0 in the precondition of gcd
Alice should write b > 0 in the precondition of gcd
Alice should write gcd(a, b) > 0 in the precondition of gcd
Alice should write a and b are integers in the precondition of gcd
(missing explanation)
If Alice adds a > 0 to the precondition, Bob should test negative values of a
If Alice does not add a > 0 to the precondition, Bob should test negative values of a
(missing explanation)
Exceptions
Now that we’re writing specifications and thinking about how clients will use our methods, let’s discuss how to handle exceptional cases in a way that is safe from bugs and easy to understand.
A method’s signature — its name, parameter types, return type — is a core part of its specification, and the signature may also include exceptions that the method may trigger.
Read: Exceptions in the Java Tutorials.
Exceptions for signaling bugs
You’ve probably already seen some exceptions in your Java programming so far, such as ArrayIndexOutOfBoundsException (thrown when an array index foo[i] is outside the valid range for the array foo) or NullPointerException (thrown when trying to call a method on a null object reference).
These exceptions generally indicate bugs in your code, and the information displayed by Java when the exception is thrown can help you find and fix the bug.
ArrayIndexOutOfBounds- and NullPointerException are probably the most common exceptions of this sort.
Other examples include:
ArithmeticException, thrown for arithmetic errors like integer division by zero.NumberFormatException, thrown by methods likeInteger.parseIntif you pass in a string that cannot be parsed into an integer.
Exceptions for special results
Exceptions are not just for signaling bugs. They can be used to improve the structure of code that involves procedures with special results.
An unfortunately common way to handle special results is to return special values.
Lookup operations in the Java library are often designed like this: you get an index of -1 when expecting a positive integer, or a null reference when expecting an object.
This approach is OK if used sparingly, but it has two problems.
First, it’s tedious to check the return value.
Second, it’s easy to forget to do it.
(We’ll see that by using exceptions you can get help from the compiler in this.)
Also, it’s not always easy to find a ‘special value’.
Suppose we have a BirthdayBook class with a lookup method.
Here’s one possible method signature:
class BirthdayBook {
LocalDate lookup(String name) { ... }
}(LocalDate is part of the Java API.)
What should the method do if the birthday book doesn’t have an entry for the person whose name is given? Well, we could return some special date that is not going to be used as a real date. Bad programmers have been doing this for decades; they would return 9/9/99, for example, since it was obvious that no program written in 1960 would still be running at the end of the century. (They were wrong, by the way.)
Here’s a better approach. The method throws an exception:
LocalDate lookup(String name) throws NotFoundException {
...
if ( ...not found... )
throw new NotFoundException();
...and the caller handles the exception with a catch clause.
For example:
BirthdayBook birthdays = ...
try {
LocalDate birthdate = birthdays.lookup("Alyssa");
// we know Alyssa's birthday
} catch (NotFoundException nfe) {
// her birthday was not in the birthday book
}Now there’s no need for any special value, nor the checking associated with it.
reading exercises
Assume we’re using BirthdayBook with the lookup method that throws NotFoundException.
Assume we have initialized the birthdays variable to point to a BirthdayBook, and assume that Elliot is not in that birthday book.
What will happen with the following code:
try {
LocalDate birthdate = birthdays.lookup("Elliot");
}(missing explanation)
try {
LocalDate birthdate = birthdays.lookup("Elliot");
} catch (NotFoundException nfe) {
birthdate = LocalDate.now();
}(missing explanation)
try {
LocalDate birthdate = birthdays.lookup("Elliot");
} catch (NotFoundException nfe) {
throw new DateTimeException("Missing reference birthday", nfe);
}(DateTimeException is provided by the Java API.)
(missing explanation)
Checked and unchecked exceptions
We’ve seen two different purposes for exceptions: special results and bug detection. As a general rule, you’ll want to use checked exceptions to signal special results and unchecked exceptions to signal bugs. In a later section, we’ll refine this a bit.
Some terminology: checked exceptions are called that because they are checked by the compiler:
- If a method might throw a checked exception, the possibility must be declared in its signature.
NotFoundExceptionwould be a checked exception, and that’s why the signature endsthrows NotFoundException. - If a method calls another method that may throw a checked exception, it must either handle it, or declare the exception itself, since if it isn’t caught locally it will be propagated up to callers.
So if you call BirthdayBook’s lookup method and forget to handle the NotFoundException, the compiler will reject your code.
This is very useful, because it ensures that exceptions that are expected to occur will be handled.
Unchecked exceptions, in contrast, are used to signal bugs. These exceptions are not expected to be handled by the code except perhaps at the top level. We wouldn’t want every method up the call chain to have to declare that it (might) throw all the kinds of bug-related exceptions that can happen at lower call levels: index out of bounds, null pointers, illegal arguments, assertion failures, etc.
As a result, for an unchecked exception the compiler will not check for try-catch or a throws declaration.
Java still allows you to write a throws clause for an unchecked exception as part of a method signature, but this has no effect, and is thus a bit funny, and we don’t recommend doing it.
All exceptions may have a message associated with them.
If not provided in the constructor, the reference to the message string is null.
Throwable hierarchy
To understand how Java decides whether an exception is checked or unchecked, let’s look at the class hierarchy for Java exceptions.
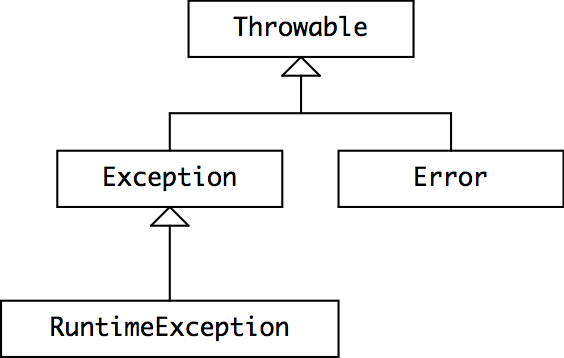
Throwable is the class of objects that can be thrown or caught.
Throwable’s implementation records a stack trace at the point where the exception was thrown, along with an optional string describing the exception.
Any object used in a throw or catch statement, or declared in the throws clause of a method, must be a subclass of Throwable.
Error is a subclass of Throwable that is reserved for errors produced by the Java runtime system, such as StackOverflowError and OutOfMemoryError.
For some reason AssertionError also extends Error, even though it indicates a bug in user code, not in the runtime.
Errors should be considered unrecoverable, and are generally not caught.
Here’s how Java distinguishes between checked and unchecked exceptions:
RuntimeException,Error, and their subclasses are unchecked exceptions. The compiler doesn’t require them to be declared in thethrowsclause of a method that throws them, and doesn’t require them to be caught or declared by a caller of such a method.- All other throwables —
Throwable,Exception, and all of their subclasses except for those of theRuntimeExceptionandErrorlineage — are checked exceptions. The compiler requires these exceptions to be caught or declared when it’s possible for them to be thrown.
When you define your own exceptions, you should either subclass RuntimeException (to make it an unchecked exception) or Exception (to make it checked).
Programmers generally don’t subclass Error or Throwable, because these are reserved by Java itself.
reading exercises
Suppose we’re building a robot and we want to specify the function
public static List<Point> findPath(Point initial, Point goal)which is responsible for path-finding: determining a sequence of Points that the robot should move through to navigate from initial to goal, past any obstacles that might be in the way.
In the postcondition, we say that findPath will search for paths only up to a bounded length (set elsewhere), and that it will throw an exception if it fails to find one.
(missing explanation)
(missing explanation)
Exception design considerations
The rule we have given — use checked exceptions for special results (i.e., anticipated situations), and unchecked exceptions to signal bugs (unexpected failures) — makes sense, but it isn’t the end of the story. The snag is that exceptions in Java aren’t as lightweight as they might be.
Aside from the performance penalty, exceptions in Java incur another (more serious) cost: they’re a pain to use, in both method design and method use.
If you design a method to have its own (new) exception, you have to create a new class for the exception.
If you call a method that can throw a checked exception, you have to wrap it in a try-catch statement (even if you know the exception will never be thrown).
This latter stipulation creates a dilemma.
Suppose, for example, you’re designing a queue abstraction.
Should popping the queue throw a checked exception when the queue is empty?
Suppose you want to support a style of programming in the client in which the queue is popped (in a loop say) until the exception is thrown.
So you choose a checked exception.
Now some client wants to use the method in a context in which, immediately prior to popping, the client tests whether the queue is empty and only pops if it isn’t.
Maddeningly, that client will still need to wrap the call in a try-catch statement.
This suggests a more refined rule:
- You should use an unchecked exception only to signal an unexpected failure (i.e. a bug), or if you expect that clients will usually write code that ensures the exception will not happen, because there is a convenient and inexpensive way to avoid the exception;
- Otherwise you should use a checked exception.
Here are some examples of applying this rule to hypothetical methods:
Queue.pop()throws an uncheckedEmptyQueueExceptionwhen the queue is empty, because it’s reasonable to expect the caller to avoid this with a call likeQueue.size()orQueue.isEmpty().Url.getWebPage()throws a checkedIOExceptionwhen it can’t retrieve the web page, because it’s not easy for the caller to prevent this.int integerSquareRoot(int x)throws a checkedNotPerfectSquareExceptionwhenxhas no integral square root, because testing whetherxis a perfect square is just as hard as finding the actual square root, so it’s not reasonable to expect the caller to prevent it.
The cost of using exceptions in Java is one reason that many Java API’s use the null reference as a special value. It’s not a terrible thing to do, so long as it’s done judiciously, and carefully specified.
How to declare exceptions in a specification
Since an exception is a possible output from a method, it may have to be described in the postcondition for the method.
The Java way of documenting an exception as a postcondition is a @throws clause in the Javadoc comment.
Java may also require the exception to be included in the method signature, using a throws declaration.
This section discusses when to use each of these ways of indicating the possibility of an exception, and when not to.
Exceptions that are used to signal unexpected failures – bugs in either the client or the implementation – are not part of the postcondition of a method, so they should not appear in either @throws or throws.
For example, NullPointerException need never be mentioned in a spec.
Our implicit precondition already disallows null values, which means that a valid implementation is free to throw it without any warning if a client ever passes a null value.
So this spec, for example, never mentions NullPointerException:
/**
* @param lst list of strings to convert to lower case
* @return new list lst' where lst'[i] is lst[i] converted to lowercase
*/
static List<String> toLowerCase(List<String> lst)Exceptions that signal a special result are always documented with a Javadoc @throws clause, specifying the conditions under which that special result occurs.
Furthermore, if the exception is a checked exception, then Java requires the exception to be mentioned in a throws declaration in the method signature.
An example is the checked NotPerfectSquare exception in the spec below:
/**
* Compute the integer square root.
* @param x value to take square root of
* @returns square root of x
* @throws NotPerfectSquareException if x is not a perfect square
*/
int integerSquareRoot(int x) throws NotPerfectSquareException;For unchecked exceptions that signal a special result, Java allows but doesn’t require the throws clause.
But it is better to omit the exception from the throws clause in this case, to avoid misleading a human programmer into thinking that the exception is checked.
The EmptyQueueException in the example below shows how to document an unchecked exception:
/**
* Pops a value from this queue.
* @return next value in the queue, and removes the value from the queue
* @throws EmptyQueueException if this queue is empty
*/
int pop();reading exercises
Examine this code for analyzing some Thing objects:
static void analyzeEverything() {
analyzeThingsInOrder();
}
static void analyzeThingsInOrder() {
try {
for (Thing t : ALL_THE_THINGS) {
analyzeOneThing(t);
}
} catch (AnalysisException ae) {
return;
}
}
static void analyzeOneThing(Thing t) throws AnalysisException {
// ...
// ... maybe go off the end of an array
// ...
}AnalysisException is an unchecked exception.
(missing explanation)
(missing explanation)
Summary
Before we wrap up, check your understanding with one last example:
reading exercises
Suppose we’re working on the method below…
// Requires: tiles has length 7 & contains only uppercase letters.
// crossings contains only uppercase letters, without duplicates.
// Effects: Returns a list of words where each word can be made by taking
// letters from tiles and at most 1 letter from crossings.
public static List<String> scrabble(String tiles, String crossings) {
if (tiles.length() != 7) { throw new RuntimeException(); }
return new ArrayList<>();
}(missing explanation)
(missing explanation)
(missing explanation)
(missing explanation)
A specification acts as a crucial firewall between the implementer of a procedure and its client. It makes separate development possible: the client is free to write code that uses the procedure without seeing its source code, and the implementer is free to write the code that implements the procedure without knowing how it will be used.
Let’s review how specifications help with the main goals of this course:
Safe from bugs. A good specification clearly documents the mutual assumptions that a client and implementer are relying on. Bugs often come from disagreements at the interfaces, and the presence of a specification reduces that. Using machine-checked language features in your spec, like static typing and exceptions rather than just a human-readable comment, can reduce bugs still more.
Easy to understand. A short, simple spec is easier to understand than the implementation itself, and saves other people from having to read the code.
Ready for change. Specs establish contracts between different parts of your code, allowing those parts to change independently as long as they continue to satisfy the requirements of the contract.