Daniel Harari |
|---|
Daniel Harari |
|---|

The goal of this project is to explore the learning mechanisms, that underly the rapid developement of visual concepts in humans, during early infanthood.
Specifically, we suggest a model for learning to recognize hands and direction of gaze from unlabeled natural video streams.
This is a joint work with N. Dorfman.

Object segregation is a complex perceptual process that relies on the integration of multiple cues. This is a computationally challenging task in which humans outperform the best performing models.
However, infants ability to perform object segregation in static images is severely limited. In this project we are interested in questions such as:
* How the rich set of useful cues is learned?
* What initial capacities make this learning possible?
We present a model that initially incorporates only two basic capacities known to exist at an early age: the grouping of image regions by common motion and the detection of motion discontinuities.
The model then learns significant aspects of object segregation in static images in an entirely unsupervised manner by observing videos of objects in motion.

Human visual perception develops rapidly during the first months of life, yet, little is known about the underlying learning process, and some early perceptual capacities are rather surprising.
One of these is the ability to categorize spatial relations between objects, and in particular to recognize containment relations, where one object is inserted into another. This lies in sharp contrast to the computational difficulty of the task.
This study suggests a computational model that learns to recognize containment and other spatial relations, using only elementary perceptual capacities. Our model shows that motion perception leads naturally to concepts
of objects and spatial relations, and that further development of object representations leads to even more robust spatial interpretation. We demonstrate the applicability of the model by successfully learning to recognize spatial relations from unlabeled videos.

This project aims to explore the recognition capacity of tiny image patches of objects, object parts and object interactions,
we call MIRC - MInimal Recognizable Configurations.
These tiny images are minimal in the sense that any cropped or down-scaled sub-images of them, are no longer recognizable for human observers.
The project addresses both psychophysical aspects of this capacity, as well as computational recognition mechanisms to support such a capacity.
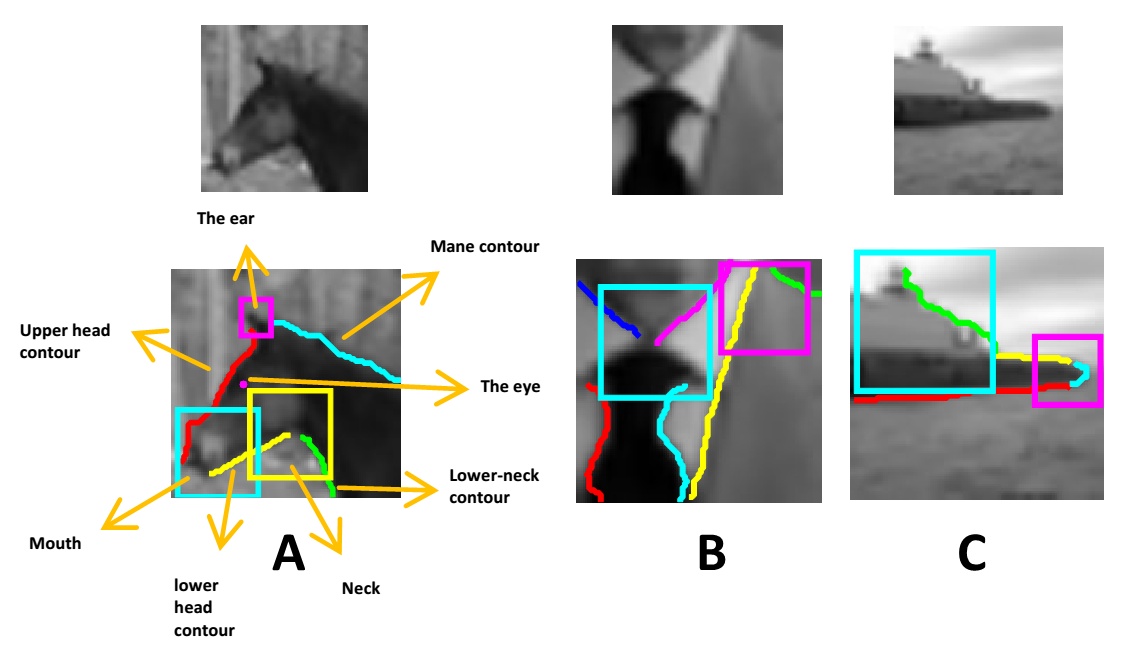
A ’full interpretation’ of an object image is performed by humans in recognizing an object category from an image, while identifying and localizing a rich set of internal object features. This capability is not currently produced by computational recognition schemes.
In this work we develop and test an interpretation algorithm, which is based on the extraction of primitives and a set of relations defined over them. We discover a useful set of relations for the
interpretation process, starting with a pool of assembled candidate relations, and identify the informative ones by testing their contribution to successful interpretations.
The results of the interpretation process are also used as a validation test for object recognition, by rejecting candidate detections that do not admit a valid interpretation.

Joint attention is a core, early-developing form of social intelligence, in which two or more people jointly attend the same target object. Discovering and interpreting joint attention in visual scenes is based on the ability to discriminate the common target of several people in the scene.
This work explores the human ability to discriminate a third person gaze directed towards objects that are further away, especially in unconstraint cases where the looker can move her head and eyes freely.
The research joins human psychophysics and a cognitively motivated computer vision model, which can detect the 3D direction of gaze from 2D face images.
Experimental results collectively show that the acuity of human joint attention is indeed highly impressive, given the computational challenge of the natural looking task. Moreover, the gap between human and model performance, as well as the variability of gaze interpretation across different lookers, require further understanding of the underlying mechanisms utilized by humans for this challenging task.
The study further extends to mechanisms that build on top of the gaze perception capabilites, to discover social interactions in scenes such as joint attention and mutual attention.

Visual understanding is a fundamental and yet very challenging task, in which humans by far outperform artificial intelligence capabilities for both low-level and high-level vision.
This research objective is to explore the human approach to visual understanding and to build a computational model that utilizes this approach to produce a system with an enhanced, human-like, visual understanding capability.
In particular, since humans often ask and answer questions using natural language about what they see in the world, we aim to develop computational models that jointly address vision and language.
These models will allow an AI system to answer human-like queries about images and video, and resolve linguistic ambiguities by visual interpretation.

The ability to recognize and segment-out small objects and object parts in a cluttered background is challenging for current visual models, including deep neural networks. In contrast, humans master this ability, once fixated at the target object. In this project we explore a variable resolution model for object recognition, inspired by the human retinal variable resolution system. Given restricted computational resources, the model acquires visual information at a high resolution around the fixation point, on the expense of lower resolution at the periphery. We evaluate the efficiency of the model by comparing its performance with an alternative constant resolution model. We test the model's ability to 'fixate' on the target by applying the model iteratively to a set of test images, and compare the results with human fixation trajectory given the same image stimuli.
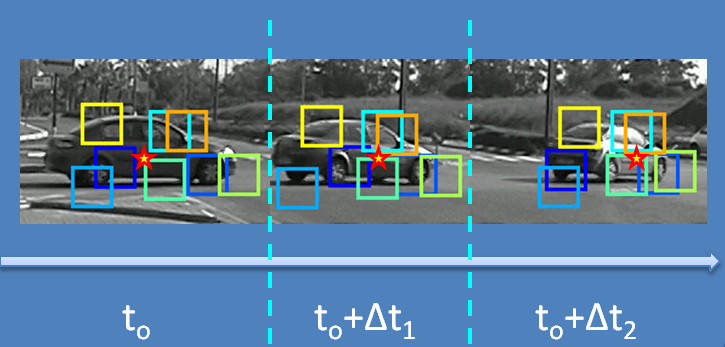
This project aims to explore the adaptation of a visual recognition system in a dynamically changing environment.
Given an initial model of an object category from a certain viewing direction, we suggest a mechanism to extend recognition capabilities to new viewing directions,
by observing unlabeled natural video streams.