


6.6.2 Discrete and Finite State Space for Probabilistic NetworksAs a consequence of the conceptual and computational difficulties in obtaining shortest distances on probabilistic networks we are usually forced to make some simplifications when working with such networks. One obvious (and by far the most common) possible simplification is to use the expected link length for every link as a proxy for the true link length. This of course transforms what is actually a probabilistic network into a deterministic network with constant link lengths. Another possible simplification which, while increasing mathematical
tractability, preserves at the same time the added realism provided by the
probabilistic properties of the models is the assumption that link lengths
are discrete random variables that take only a finite number of values. That
is, we approximate the probability distribution of random variable L(i, j),
the length of the link (i, j), by writing
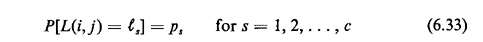
where The net effect of this assumption is that the network now has only a finite number, m, of states. Each state differs from the others by a change in the length of at least one link. Thus, the finest-grained sample space for the network consists of a listing of the set of all m mutually exclusive and collectively exhaustive possible network states that can be denoted as G1, G2, ..., Gm (to make explicit the fact that each state is a different "snapshot" of the network) with each network state having a probability of occurrence Pr, r = 1,2, ...,m. In general, the number of states will depend on the degree of statistical
dependence among the random variables 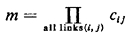
where Cij is the number of values that the length of link (i, j) [i.e., L(i, j)] can take. Similarly, the state probabilities, Pr must either be known [in the case when the L(i, j) are not mutually independent] or are easily computable (when we have statistical independence). Let us now define:
dr(x, y) = shortest distance between points x and y when the network is in state Gr For each given state, r, the network's snapshot Gr looks
exactly like a deterministic network and, therefore, using our earlier
shortest-path algorithms and the known link lengths In principle, then, it is possible to compute, under the assumption that
there is no change of states during travel, such quantities as:

The computational effort involved may, naturally, still be formidable and depends critically on the total number m of distinct states. For instance, supposing that each link length L(i, j) takes c distinct values and assuming full statistical independence between links, we have m = ce (6.36) where e is the total number of links in the network. Since for a
connected graph we have n - 1 On the other hand, it is very unlikely that in an urban context the link lengths will be statistically independent: traffic conditions, for example, have approximately identical time patterns throughout a city, and therefore at peak traffic times the higher values of link lengths prevail simultaneously, for all links on the network model, while the opposite is true at off-peak periods. Thus, in many cases it is possible that a few distinct states (small m) will suffice to model, at least approximately, the most common sets of travel conditions under which urban roadway networks operate. The approach that was outlined above will then prove computationally feasible under these circumstances.
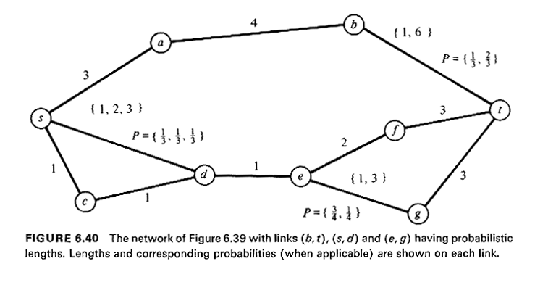
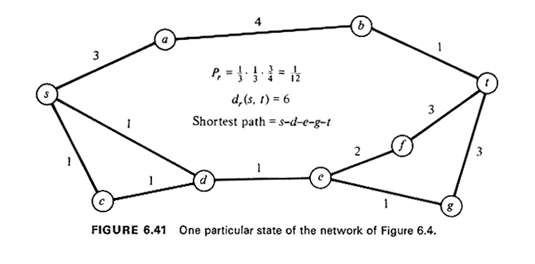
|
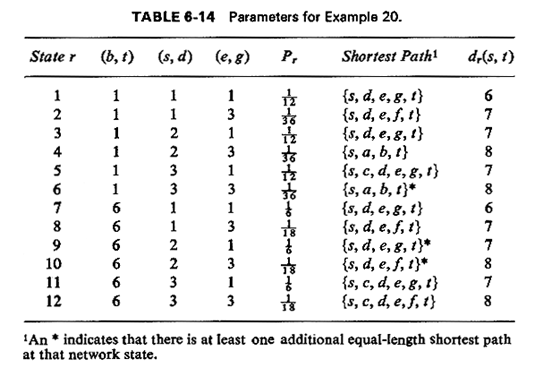
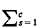 =1. Thus, the link length can only take
values
=1. Thus, the link length can only take
values 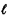 1,
1,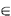 G.
G.
 e
e