| Vol.
XXV No.
2 November / December 2012 |
| contents |
| Printable Version |
MIT: First in the World, Sixth in the U.S.?
Many organizations create and publish rankings of institutions of higher education. They range from the trivial – Princeton Review’s top party schools – to the much-hyped U.S. News and World Report rankings. One goal most of these rankings have in common is putting the top institutions into a simple rank-order list that somehow captures the quality of the entire educational experience. Colleges and universities are sufficiently complex that any comparison will by nature be reductive, but the publishers of these rankings each claim that they are reducing to the most important factors.
Here at MIT, Institutional Research (in the Office of the Provost) routinely collects and distributes to our Schools and departments four popular ranking systems: the aforementioned U.S. News and World Report (which has overall university rankings as well as undergraduate and graduate subject rankings), Times Higher Education (from the U.K. magazine of the same name, also divided into institutional and subject rankings), the QS World University Rankings, and the National Research Council ranking of graduate programs.
These rankings incorporate a variety of measures to arrive at an overall score. For each category, say teaching for example, the rankings usually incorporate quantitative measures, such as the faculty-student ratio, and qualitative measures, such as teaching ratings from reputation surveys. In addition to measures of teaching, other drivers of these rankings methodologies include indices of research productivity (such as numbers of publications and citations), financial resources, and the ill-defined construct of reputation.
Generally speaking, the different rankings adopt different orientations which can be broadly categorized into input-centric and output-centric. Nearly half of the U.S. News and World Report ranking is composed of input measures such as incoming undergraduate class rank, incoming undergraduate SAT scores, undergraduate selectivity, financial resources per student, and student-to-faculty ratio. A third of the U.S. News ranking is based on outputs (graduation and retention rates and alumni giving).
Two other rankings are more output-based than U.S. News. 60% of the Times Higher Education (THE) World University Rankings is based on faculty research outputs (publications and citations), and 20% of the QS World University Rankings is related to citations. Both of these rankings, as their names would suggest, include institutions from around the globe, not just in the United States. MIT tends to do much better in these rankings than in the U.S. News rankings, due to their focus on research. The most recent THE rankings have MIT third worldwide, and the QS rankings have MIT as the number one institution in the world. While this may sound perfectly reasonable to those of us who work here, U.S. News disagrees and most recently had us tied for sixth place nationally with Stanford.
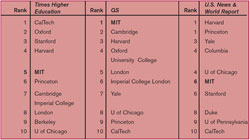
While these systems of rankings assign different weights to different categories, all three of them include some arguably objective, verifiable measures, such as publications and citations, student characteristics, or student-to-faculty ratios. The survey-based measures of reputation are more opaque, and influence the rankings to a considerable extent. Each of the rankings includes the results of surveys sent to faculty, department chairs, employers of graduates, and/or college and university presidents. As a part of these surveys, academics from the participating institutions are asked to score the other institutions, and an average of these scores is a part of the final tally. The most reputation-based ranking is QS, with 50% of an institution’s rank derived thereof. U.S. News is 22.5% reputation, and THE is 15%.
All three of these publishers also produce rankings at the subject/course level. THE uses the same methodology for their subject rankings as they do for their institution rankings. QS’s subject rankings are more simplified than their institutional ones and rely only upon a survey of academics, of employers of graduates, and counts of citations. The relative weight of each category is tailored to each field as deemed appropriate to that field. U.S. News, however, includes no objective measures in their undergraduate and graduate subject rankings. These are determined entirely by surveys sent to deans (for their rankings of undergraduate engineering and business) and department heads (for their rankings of graduate programs).
| Back to top |
The last ranking system mentioned in the introduction, but purposefully left separate, is the NRC’s 2010 ranking of doctoral programs. The methodology for the NRC rankings was designed to use measurable data on doctoral programs and apply both the stated preferences of academics in the field and their revealed preferences. This was done using a survey that asked not only how respondents would rate each program, but the importance of certain factors – such as graduate student support or number of publications by faculty – to compute a range of rankings for each program. One range was calculated using weights derived from the stated importance of the factors, while the other was calculated using the revealed importance of these factors based upon ratings of programs. So, for example, if respondents to the NRC survey (i.e., faculty in the field) said that diversity was very important, but then the top-rated programs were not diverse, measures of diversity would be a large part of one ranking but not the other. The end result was a ranking that, despite its noble goal of capturing the “multidimensionality” of doctoral program quality, gave programs two ranges of rankings (e.g., from fourth to fourteenth for stated importance and fifth to eighth for revealed importance) that are difficult to understand or interpret because the typical consumer of rankings wants a single number.
All of these rankings attempt to do something very difficult by quantifying – at a single point in time – the relative quality of one school or program that is constantly evolving.
For those of us at MIT, the difference in our rank from one year to the next, say from fifth to sixth, seems arbitrary. But for institutions and programs on the margin of the top 10 or the top 50 or top 100, being bumped out of one of these groups could mean a difference in which students apply for admission. Perhaps the greatest source of anxiety is being ranked first, as there is nowhere to go but down. In summary, while it is important to watch the rankings in order to know how your institution or program will be perceived by consumers of these rankings, it is also important to know that the methods behind these rankings determine the results just as much as the quality of the school or department.
This article was written by the Office of theProvost/Institutional Research at the request of the Faculty Newsletter.
| Back to top | |
| Send your comments |
| home this issue archives editorial board contact us faculty website |