by Sean Gibbons and Claire Duvallet
sgibbons at systemsbiology dot org
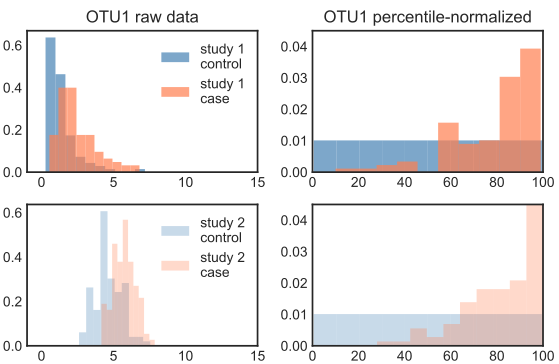
Percentile Normalization is a non-parametric method for removing batch effects from case-control studies. This method was developed for amplicon sequencing data (e.g. 16S sequencing), but can be extended to other types of 'omics data. In brief, feature values (e.g. Operational Taxonomic Units, Sequence Variants, etc.) are converted to percentiles of their control distribution, separately for each study. This procedure establishes the control samples as a null-distribution (i.e. a uniform distribution between zero and 100). If the case percentiles are significantly non-uniform, then they differ from the control samples. Upon transformation, features can be pooled together across studies with similar case-control definitions. Pooling percentile-normalized data provides greater statistical power to detect smaller effect sizes.
REFERENCE
Gibbons SM, Duvallet C, Alm EJ (2018) Correcting for batch effects in case-control microbiome studies.
PLoS Comput Biol 14(4): e1006102.
https://doi.org/10.1371/journal.pcbi.1006102
SOURCE
The Python 3.0 version of the code is available on the
github page, which also includes installation and usage instructions.
The method is also available as a
QIIME 2 plugin. It is currently available on
this github page, which also includes installation instructions.
