History of Natural Language Processing
The idea of natural language processing (NLP) originates from Alan Turing, a British computer scientist, who formulated a hypothetical test, known as the "Turing Test". The "Turing Test" proposes that the question "Can machines think?" can be answered if a computer is indistinguishable from a human in all facets of thought such as conversation, object identification based on given properties, and so forth. After Turing's proposition, many attempts have been made to create natural language processing software. However, most of these programs do not have high-level semantic abilities. Rather they have a very limited set of operations, for which keywords are assigned.
Statistical Parsers
Parsers are a set of algorithms that determine the parts of speech of the words in a given sentence. Current parsers use a set of human-parsed sentences that creates a probability distribution, which is then used as a statistical model for parsing other sentences. Stanford University and the University of California Berkeley use probabilistic context-free grammars (PCFG) statistical parsers, which are the most accurate statistical parsers currently used, with 86.36% and 88% accuracy, respectively. The different parts of speech are separated as below.
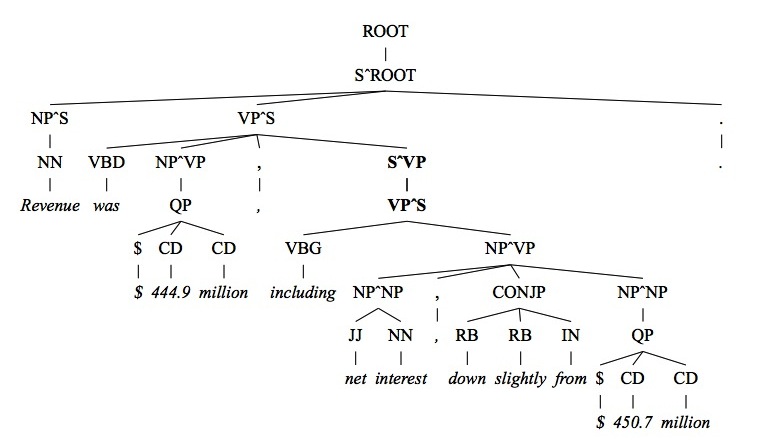
Picture from "Accurate Unlexicalized Parsing".
NN = noun, NP = noun phrase, S = subject, VP = verb phrase, and the other symbols represent more specific parts of speech. The parser splits the sentence into three parts: the subject noun phrase, the verb phrase, and the noun phrase. Each of these parts is then split into more parts and those parts into parts, finally arriving at individual qualifications for each word. These parsers are called context-free because the parse of a word is not affected by the other words in the sentence other than those in its phrase, while the less accurate parsers obtain an overall probability for a sentence and adjust their parsing accordingly.
Other NLP Programs
In addition to statistical parsers, which only determine the syntax of a sentence, some elementary programs have been written for evaluating the semantics of a given body of text. There is a system called FRUMP that organises news stories by finding key words in an article that match a set of scripts and then assigns the article to a certain category, in which it is grouped with other articles of similar content. SCISOR summarizes a given news article by analyzing the events, utilizing three different sets of knowledge: semantic knowledge, abstract knowledge, and event knowledge. As the program sifts through the body of text, certain words trigger different pieces of knowledge, which are compiled to gain the best understanding of that word or sequence of words. The resultant meanings can then be organized and rewritten using similar meanings, equally balanced among the three sets of knowledge as the original piece of information. Similarly, TOPIC summarizes a given text by distinguishing the nouns and noun phrases and then analyzing their meaning through a "thesaurus-like ontological knowledge base", after which the program uses these equivalent meanings to rewrite the text.