Morphology: Results
The program was run using a series of files in English, French and Spanish. Initial frequency tables for analysis of individual languages were created using the EU Charter in each respective language, and the comparison threshold was determined using a series of randomized Wikipedia articles of considerable length in English and French.
Bigram Distributions
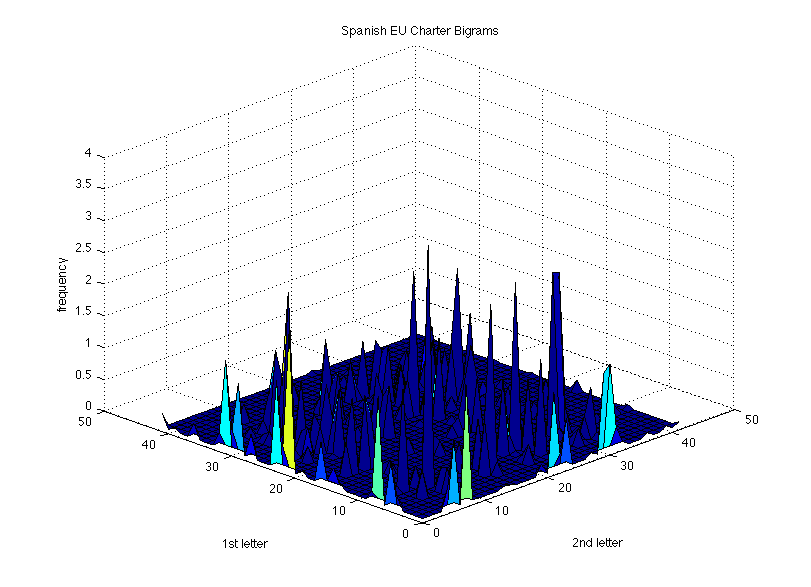
Analysis of the EU charters in each of the three languages produced the following frequency distribution graphs (click to see larger).
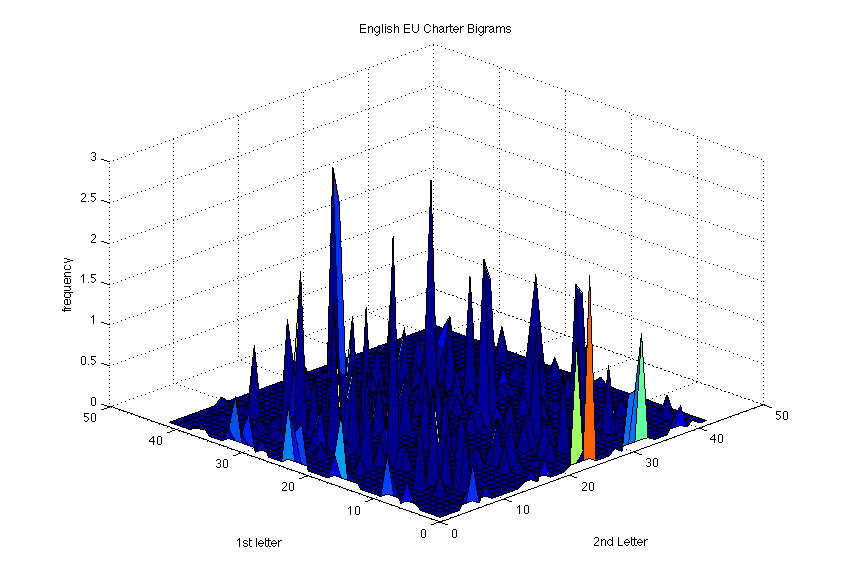

These frequency graphs show that each language has a handful of extremely common bigrams (in addition to some which appear little or not at all). In English, this includes "th" and "he" with percentage frequencies of 2.9 and 2.8, respectively, along with "on" and "ti" also both above 2.5%. This data is slightly skewed by the text used, though "th" and "he" are indeed the most common bigrams in English. A study conducted using a sample of 40,000 words gave the two frequencies of 1.5 and 1.3, respectively, though the next most common bigrams in the sample text are not as common in the English language as a whole as their frequencies here would suggest. This is largely due to an inherent bias in the text, as words such as "protection" or "responsibilities" appear frequently in the EU Charter.
French resulted in "es" and "on" as the most common bigrams, followed by "de" and "le". In Spanish, the most common bigram by far was "de", followed by "cl", "en", "er", and "es". Again, however, these likely suffer from slight biases due to the nature of the text.
File Comparison
The threshold determined using sample texts in English and French was also tested with Spanish, with continued accuracy for texts of considerable length. The difference values for a series of files are shown in the table below.
| philosophy | encyclopedia | france (fr) | capitalism (fr) | jazz (es) | nyc (es) | |
| philosophy | ... | ... | ... | ... | ... | ... |
| encyclopedia | 33.13 | ... | ... | ... | ... | ... |
| france (fr) | 73.83 | 75.31 | ... | ... | ... | ... |
| capitalism (fr) | 73.94 | 79.62 | 30.15 | ... | ... | ... |
| jazz (es) | 67.68 | 69.56 | 64.76 | 67.76 | ... | ... |
| nyc (es) | 71.76 | 73.42 | 66.41 | 70.46 | 28.95 | ... |
Limitations
This method does have certain limitations, however. Since the program deals with bigrams (though it can be easily made to use n-grams for any n greater than 1), single-letter words are not taken into account. While this does not have a large overall effect, it produces some inaccuracies in the analysis of frequencies for a given language.
A more significant limitation is the requirement that all "legal" characters be defined before the program is run. Although it would be relatively straightforward to dynamically determine the character set based on the input files, this creates issues where the character sets for each file are not the same, making it difficult, if not impossible, to accurately compare the two files. Even ignoring this, varying the number of characters may produce variations in the threshold used to determine language similarity. The program is also effective only for files of considerable length to allow for a large enough sample size. In tests, the algorithm was no longer accurate below approximately 300 words.