Morphology: Algorithm
The program was initially developed in C++ then translated to Java to take advantage of non-standard characters, and is set up in two main portions. The first step involves generating a table of frequency values from a file, and the second step is to compare the two tables and determine the level of similarity.
>> Download <<
Download the program here.
See the source code here.
This program runs via command line (cmd in Windows or Terminal in OS X), and includes six sample texts for use with the program. Navigate to the folder using cd Downloads/morphology/ (assuming standard setup) and run with:
java -jar ngrams.jar
Enter the name of each file to be compared without the ".txt". For example, try the following:
Input First File Name: eu_en
Input Second File Name: eu_fr
Frequency Tables
A two-dimensional numerical array is created based on the set of valid characters, initialized with each value at zero. The table below represents this array for the character set {a, à, b, c, ç, ...}, with each space representing the letter combination of the corresponding row and column in that order.
| a | à | b | c | ç | ... | |
| a | 0 | 0 | 0 | 0 | 0 | ... |
| à | 0 | 0 | 0 | 0 | 0 | ... |
| b | 0 | 0 | 0 | 0 | 0 | ... |
| c | 0 | 0 | 0 | 0 | 0 | ... |
| ç | 0 | 0 | 0 | 0 | 0 | ... |
| ... | ... | ... | ... | ... | ... | ... |
For each word from the input file, the program checks each pair of letters, adding one to the corresponding position in the bigram frequency table as seen below.
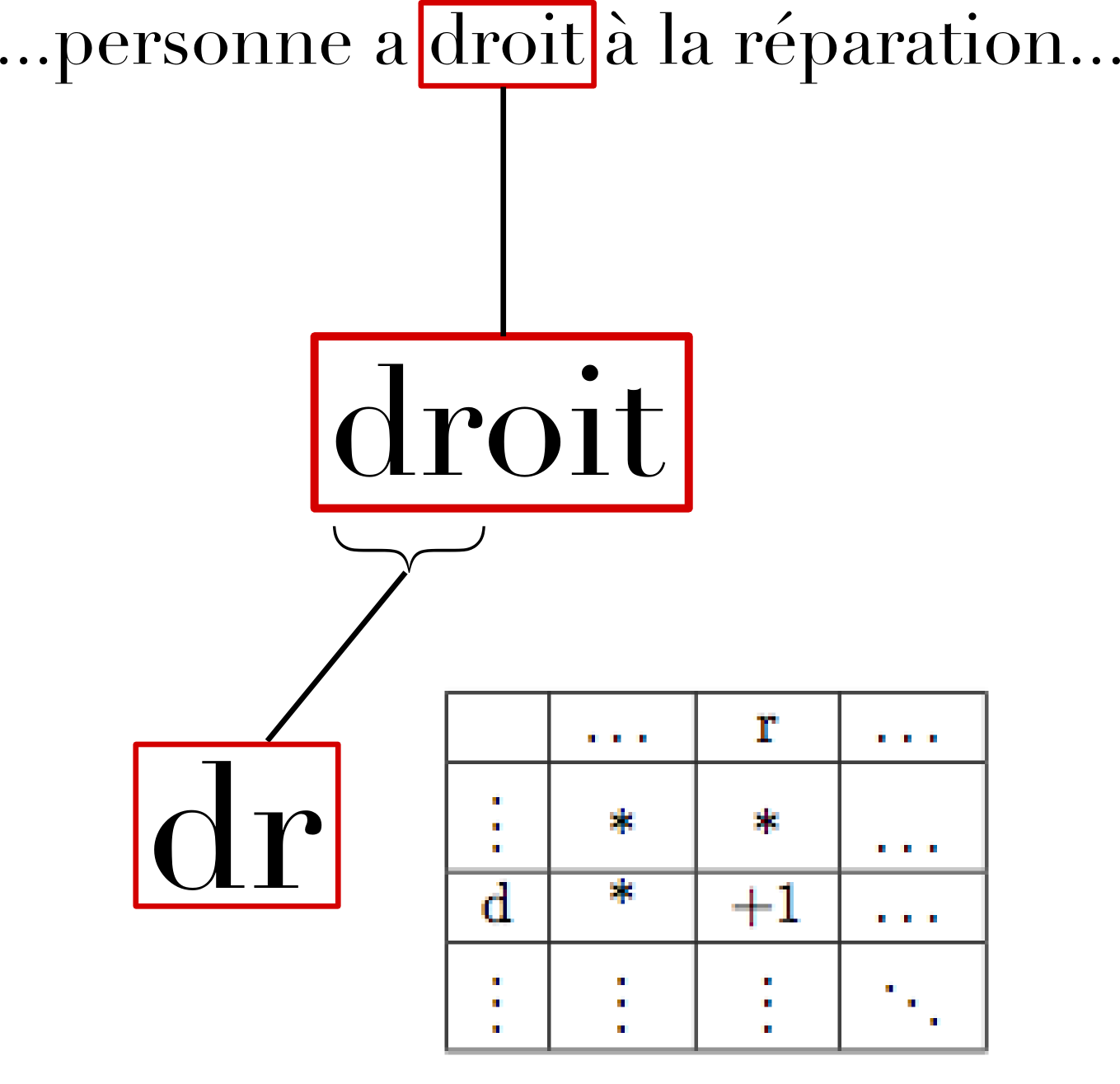
Once the end of the file is reached, each frequency count is divided by the total number of bigrams found, then multiplied by 100 to give a percentage frequency, resulting in an array as below.
| a | à | b | c | ç | ... | |
| a | 0 | 0 | 0.34 | 1.07 | 0 | ... |
| à | 0 | 0 | 0 | 0 | 0 | ... |
| b | 0.19 | 0 | 0 | 0 | 0 | ... |
| c | 0.72 | 0 | 0 | 0 | 0 | ... |
| ç | 0 | 0 | 0 | 0 | 0 | ... |
| ... | ... | ... | ... | ... | ... | ... |
Language Comparison
After the frequency tables are created for each file, the two must be compared to determine the level of similarity between the languages of the two files. This is done by finding the absolute values of the differences between corresponding frequencies for the two files, then finding the sum of these differences.
This gives an approximate measure of how different the two files are in terms of the frequency of given bigrams. As each language tends to have a unique frequency distribution, a large net difference suggests a different language for each file while a smaller net difference suggests the same language. The threshold dividing a determination of 'same language' or 'different language' was experimentally determined to be approximately 55.