Brief description: This website is dedicated to functional localization in fMRI studies of language. Here you can find information about the method, links to some relevant papers, as well as tools for download.
Acknowledgment: Much of this work was suported by NICHD K99R00 award 057522 from Eunice Kennedy Shriver National Institute Of Child Health & Human Development awarded to Ev Fedorenko.
For the application of the methods described here to the ventral visual regions, see http://web.mit.edu/bcs/nklab/GSS.shtml.
Previous research has identified a number of brain regions that are engaged during linguistic processing, but precise functional characterization of these regions has proven challenging. Limitations of traditional methods may be at least partly responsible.
In particular, in the traditional fMRI methodology individual brains are aligned together in a common space in order to determine whether activation patterns are similar across individuals and thus reflect something about human neural architecture in general, as opposed to some idiosyncractic properties of an individual brain. However, because brains differ across individuals in terms of size, shape, folding patterns, and the locations of areas with particular cell types relative to the sulci and gyri, activations often do not line up well across brains. This poor alignment leads to a loss of sensitivitiy and functional resolution, and makes it difficult to compare results across studies. These problems have plausibly slowed down progress in the field of language research.
A clearer picture of the functional architecture of language may emerge if candidate language-sensitive regions are identified functionally within each subject individually, a method that has been highly successful in the study of visual cortex but that has rarely been applied to neuroimaging studies of language. This method enables pooling of data from corresponding functional regions across subjects, rather than from corresponding locations in stereotaxic space (which may differ functionally because of the inter-subject anatomical variability).
Around 2005-2006, I began developing tools to define language-sensitive regions in individual subjects. We successfully developed a which quickly and reliably identifies brain regions previously implicated in linguistic processing, including the "classic" regions in the left inferior frontal and posterior temporal cortices. These regions (i) are present in the vast majority of subjects individually, (ii) are replicable within subjects (both within and across scanning sessions) and have clear correspondence across subjects, and (iii) respond similarly to linguistic stimuli presented visually vs. auditorily. Furthermore, this localizer is robust to changes in task (e.g., passive reading vs. reading with a memory probe), materials, and various aspects of the design/procedure.
The ability to define language-sensitive regions in individual subjects opens the door to characterizing these regions in detail, which is essential for developing models of language function in the brain and linking those models to existing cognitive and computational models.
The goal of this website is to share the tools that we have developed – and are continuing to develop – with the scientific and clinical communities, so that anyone who is interested in using this approach can easily do so.
In the individual-subjects functional localization approach, a region or a set of regions is defined in each subject using a contrast targeting the cognitive process of interest. For example, to identify face-selective brain regions, a contrast between faces and objects is commonly used (e.g., Kanwisher, McDermott & Chun, 1997). Once a localizer task has been developed and validated, in each subsequent study every participant is scanned on the localizer task and on the "task of interest", i.e., a task designed to evaluate a particular hypothesis about the functional profile of the region(s) in question. For example, with respect to face-selective brain regions, one might want to know whether these regions respond more strongly to upright vs. inverted faces (e.g., Kanwisher, Tong & Nakayama, 1998), or how they respond to a wide range of visual objects (Downing et al., 2006).
There are two challenges that face researchers who want to adopt this approach for studying high-level cognitive processes, such as language. First, it is non-trivial to decide on a contrast that would target all and only regions supporting the cognitive process of interest. And second, many high-level cognitive tasks elicit robust and distributed activations, which can make it difficult to decide (a) what counts as a "region", and (b) how different parts of activations correspond across subjects. Here are the solutions we came up with.
Your localizer task should be robust to changes in materials, task, and procedure. When developing our language localizer, we experimented with a few different contrasts and settled on a relatively broad functional contrast between sentences and pronounceable nonwords. This contrast targets regions engaged in retrieving the meanings of individual words and in combining these lexical-level meanings into more complex meaning/structural representations. This contrast identifies a set of brain regions previously implicated in linguistic processing. Importantly, this contrast works similarly well for visual and auditory presentation modality, and we have now used it with a few different sets of materials. Furthermore, similar contrasts between language stimuli and a degraded version of those stimuli (e.g., sentences > word lists / false fonts, speech > foreign / backwards speech, etc.) appear to work similarly well. The key requirement seems to be that the critical condition is a language stimulus (words, phrases, sentences, texts), and the control condition matches those language stimuli in perceptual features but lacks meaning/structure (see Fedorenko & Thompson-Schill, 2014, for discussion).
Importantly, i) activations for language localizer contrasts are extremely stable within individuals over time (e.g., Mahowald & Fedorenko, 2016), and ii) a network of regions similar to the ones activated by such contrasts emerges from the correlational analyses of resting state data (e.g., Blank et al., 2014), suggesting that we are picking out a "natural kind". Furthermore, it is possible that in the future it will be possible to define high-level language processing regions from anatomical connectivity (DTI) data (e.g., Saygin et al., 2012). For now, however, using a language localizer is a quick and reliable way to pick out the relevant functional subset of the brain.
As we learn more about the functional architecture of language, it is possible that some of our current functional ROIs (fROIs) will need to be abandoned, some will need to be split into multiple sub-regions, and others will need to be combined (in fact, see - parcels). We always complement our fROI analyses with individual-subject whole-brain analyses, which can help us see structure within our fROIs as well as detect activations outside the borders of our fROIs.
It is also important to note that depending on your research question, you may want to include several localizers in your scanning session. For example, given that we are interested in the division of labor between the language system and the domain-general multiple demand (MD) system (e.g., Duncan, 2013) and/or the system that supports social cognition (e.g., Saxe & Powell, 2006), we often include localizers for the MD and social systems.
The traditional way to select subject-specific voxels for a particular ROI is to examine an individual subject's activation map for the localizer contrast and define the fROI(s) by hand, using macroanatomy as a guide. This method works well in cases where the regions activated by the localizer contrast are far away from one another, so that there is no confusion as to what part of the activation reflects the activity of a particular brain region, and so that it is easy to establish correspondence across different brains. Because (i) this method would not obviously work for high-level language processing regions due to the distributed nature of the activations, and because (ii) we were seeking a more principled way to define subject-specific fROIs, we developed a new procedure.
This procedure - that we termed the "group-constrained subject-specific" (GSS; formerly known as GcSS) analysis - consists of several steps (described in detail in Fedorenko et al., 2010). These steps are schematically illustrated here.
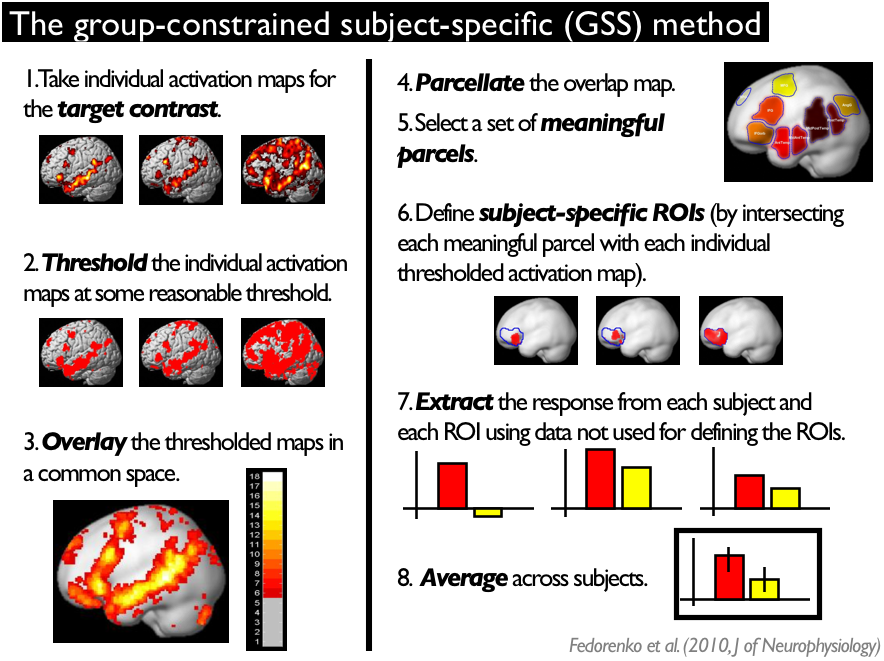
In particular, the GSS analysis involves thresholding individual activation maps for some contrast of interest at some significance level, overlaying these individual maps on top of one another in a common space to create a probabilistic overlap map (where each voxel contains information about how many subjects show an effect in that voxel), and using an image parcellation algorithm to divide the map into "functional parcels", following the map’s topography. These parcels are then used as spatial constraints to select subject-specific voxels for each region. Finally, the response is extracted from each set of subject-specific voxels (using a subset of the data that was not used in defining the ROIs) and averaged across subjects for each region.
The parcels that have a non-zero intersection with a substantial proportion of individual subjects (a non-zero intersection means that a subject has at least one supra-threshold voxel within the borders of the parcel) and that show a replicable effect in an independent subset of the data can be treated as meaningful and used in future studies to constrain the selection of subject-specific voxels in defining fROIs.
If you use a version of our language localizer task, you can download and use our . However, this method can also be applied in developing new localizers (for language or other domains), or to perform group-level analyses on datasets where a traditional random-effects analysis doesn’t yield strong/clear results (see for additional information).
You can download our SPM toolbox . The toolbox contains a Readme file which walks through the key steps for each type of analysis. The toolbox has a GUI interface but we recommend using batch *.m scripts. An advantage of using batch scripts is that you have a record of everything you have done. Once your individual subjects’ data are analyzed, running the toolbox scripts takes only a few minutes.
There are several advantages to functionally defining regions of interest in individual subjects over using traditional group-based methods (that are based on voxel-level inter-subject overlap). We discuss these in detail in our papers, but here is a summary of the key advantages.
The key problem with the traditional approach, which examines voxel-level activation overlap across subjects, is that individual subjects’ activations do not line up well. This is a consequence of inter-subject anatomical variability. Even the more advanced normalization methods that take into account the folding patterns (e.g., Fischl et al., 1999) are not good enough in cases where cytoarchitecture does not align well with the cortical folds, which is often the case for the association cortices (e.g., Brodmann, 1909; Frost & Goebel, 2011; Tahmasebi et al., 2011). This problem has two important ramifications. First, group-based methods are less sensitive: even if every subject shows activation in/around a particular anatomical location, this activation may be missed in a group analysis because of insufficient voxel-level spatial overlap across subjects. For example, the extensively studied fusiform face area (FFA) often does not emerge in group analyses even though it is robustly present in every individual.
Because of its greater sensitivity, the functional localization approach enables us to investigate small but interesting populations (where, in some cases, there may not be enough power for a traditional group analysis due to a small number of participants or due to an even higher level of variability in the precise loci of functional activations than in the healthy population). This is important, because such populations (e.g., patients with brain lesions or patients suffering from developmental or acquired disorders) have been a valuable source of evidence in understanding human cognition.
And second, group-based methods have lower functional resolution: nearby functionally distinct regions that differ in their absolute and/or relative locations in individual subjects may emerge - in the group analysis - as a single multi-functional region. This latter problem is especially serious if we are trying to discover functional specificity. (See Nieto-Castañon & Fedorenko, 2012, for an extensive discussion of lower sensitivity and functional resolution in group-based analyses.)
Using the individual-subjects functional localization approach enables us to establish a cumulative research enterprise where we, as a field, work together to discover and characterize the key components of the language system. With the traditional (group-based) methods, it is difficult to compare findings across studies and therefore to build upon previous research. People fiercely argue about whether some bit of activation is the "same" or not across two studies. Having a standardized way to identify the components of the language system before investigating their functional properties ensures that we are talking about the same regions across studies and labs. This, in turn, leads to accumulation of knowledge and faster progress in understanding the functional architecture of the language system.
Including a localizer task in every participant leads to accumulation of large datasets (with hundreds of participants) that allow us to relate neural variability (e.g., in the size or lateralization of the language system) to behavioral and genetic variability. Using functional neural markers may yield more power and reveal clearer patterns compared to purely anatomical markers based on properties of macroanatomical regions.
N.B.: Using functional localizers does not preclude you from analyzing your data using traditional analysis methods. In fact, it is sometimes a good idea to complement targeted fROI-based analyses with traditional analyses. However, if you don't include a functional localizer in your study a priori, you cannot benefit from the extra sensitivity and functional resolution that functional localizers yield, and from the ability to relate your results to those from other studies, after the fact (although see ).
First, due to its greater sensitivity and functional resolution, the functional localization method will a) allow you to potentially discover regions that would be missed with traditional group analyses; and b) see clearer functional profiles, with better differentiation among conditions, for each region you are examining. This is true regardless of whether you are using an explicit "localizer" task, or whether you are applying the GSS-style analysis methods to a dataset without a localizer task (read about how to do that).
Note also that these advantages apply to traditional fMRI designs that rely on the mean BOLD signal differences across conditions, as well as to designs that use neural suppression paradigms, multivariate pattern analysis methods, or other techniques.
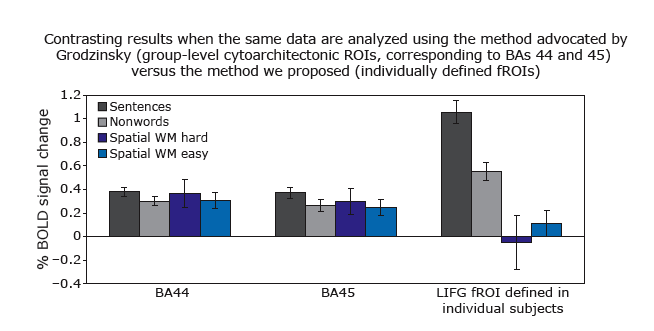
Second, increases in functional resolution are especially critical if you are asking questions about functional specialization (i.e., whether two mental processes rely on the same neural mechanisms). The figure below (from Fedorenko & Kanwisher, 2011) illustrates this point. We extracted the response from two group-level ROIs that are commonly used in the literature (corresponding to Brodmann Areas 44 and 45, i.e., ~ "Broca’s area"), and from subject-specific fROIs for our LIFG parcel, which is similar in its location to these Brodmann areas. As can be clearly seen, both of the group ROIs show weak effects for both the language task (sentences > nonwords), and for a spatial working memory task (hard spatial WM > easy spatial WM). Critically, however, if we focus on language-responsive, i.e., sentences > nonwords, voxels (using a portion of the data) and examine their response to the two language conditions (in a left-out portion of the data) and to the spatial WM conditions, we see a striking degree of specificity such that the language-responsive fROIs show no response to spatial WM (besides, the sentences > nonwords effect increases in size several-fold). Using group-level ROIs in this case would lead us to fundamentally different (and wrong) conclusions. (See this paper for evidence that Broca's area contains both language-selective and highly domain-general subregions.)
And third, perhaps the greatest advantage of functional localizers is that they allow for easier accumulation of knowledge across studies and across labs (if similar localizers are used). For example, imagine you are studying some mental process (e.g., syntactic processing), and another lab is also studying this mental process, with both labs using the traditional group-based methods. Let’s say you conduct a study and discover that some region X is engaged in syntactic processing. And let’s say that the other lab does a study and does not find region X for their syntactic task but instead finds region Y in some other part of the brain, or maybe it finds a region nearby to where you found your region X, but not quite in the same location. Where do we go from here?
In such situations (that are all too common in the field of language research) it is hard to determine which set of results is (more) valid and should be trusted, and/or to decide whether two nearby activations reflect the activity of the "same" region or of two nearby functionally distinct regions. If, on the other hand, both labs can agree on some functional signature that a brain region should demonstrate if we are to think that the region is important for syntactic processing (e.g., a stronger response to sentences than sequences of unconnected words), then both labs can define the relevant region(s) in the same way, thus establishing that they are studying the "same" region(s), and test different hypotheses about these regions. For example, one lab might want to know whether regions that support syntactic processing in language also care about structure in music, and another lab might want to know whether regions that support syntactic processing are sensitive to the frequency of syntactic constructions. In that way, the two labs can relate their sets of findings to each other in a straightforward way. Some would say, "Well, can't we just use coordinates in the common stereotaxic space to relate different sets of findings to each other?" We don’t think this is a good way. For example, as we discuss in our 2009 paper, in a review published in 1998 Aguirre & Farah have argued for a distributed representation of different visual categories (faces, objects and words) in the vental visual cortex based on observing no clear spatial clustering for a set of activation peaks from previous studies investigating visual processing. However, later work has established that in each individual subject different regions in the ventral visual cortex are highly specialized for processing different categories of visual stimuli, suggesting that sets of coordinates in stereotaxic space are not well-suited for asking questions about the architecture of human cognition.
Yes. You can apply the GSS analysis method to any dataset (as long as you have multiple functional runs per subject; multiple runs are important for cross-validation).
For example, you can use the GSS analysis as a powerful alternative to the traditional random-effects analysis. In such case, you would use your main contrast as both the "localizer" contrast and the "effect of interest" contrast. The toolbox we developed would perform cross-validation in such case, as described , so that the effect of interest is estimated using data not used for defining subject-specific fROIs. We discuss this procedure in more detail in Nieto-Castañon & Fedorenko (2012).
Alternatively, if you have multiple conditions in your study, you may choose to use some conditions for defining subject-specific fROIs and examine the response to the other conditions.
If you don’t have much data per subject, it is not unreasonable to work with liberal thresholds: given that all the effects are always estimated in a left-out portion of the data, even regions discovered at liberal thresholds in individual subjects can be thought of as meaningful regions if they show replicable response profiles.
For any other localizers used in our work, please contact Ev.
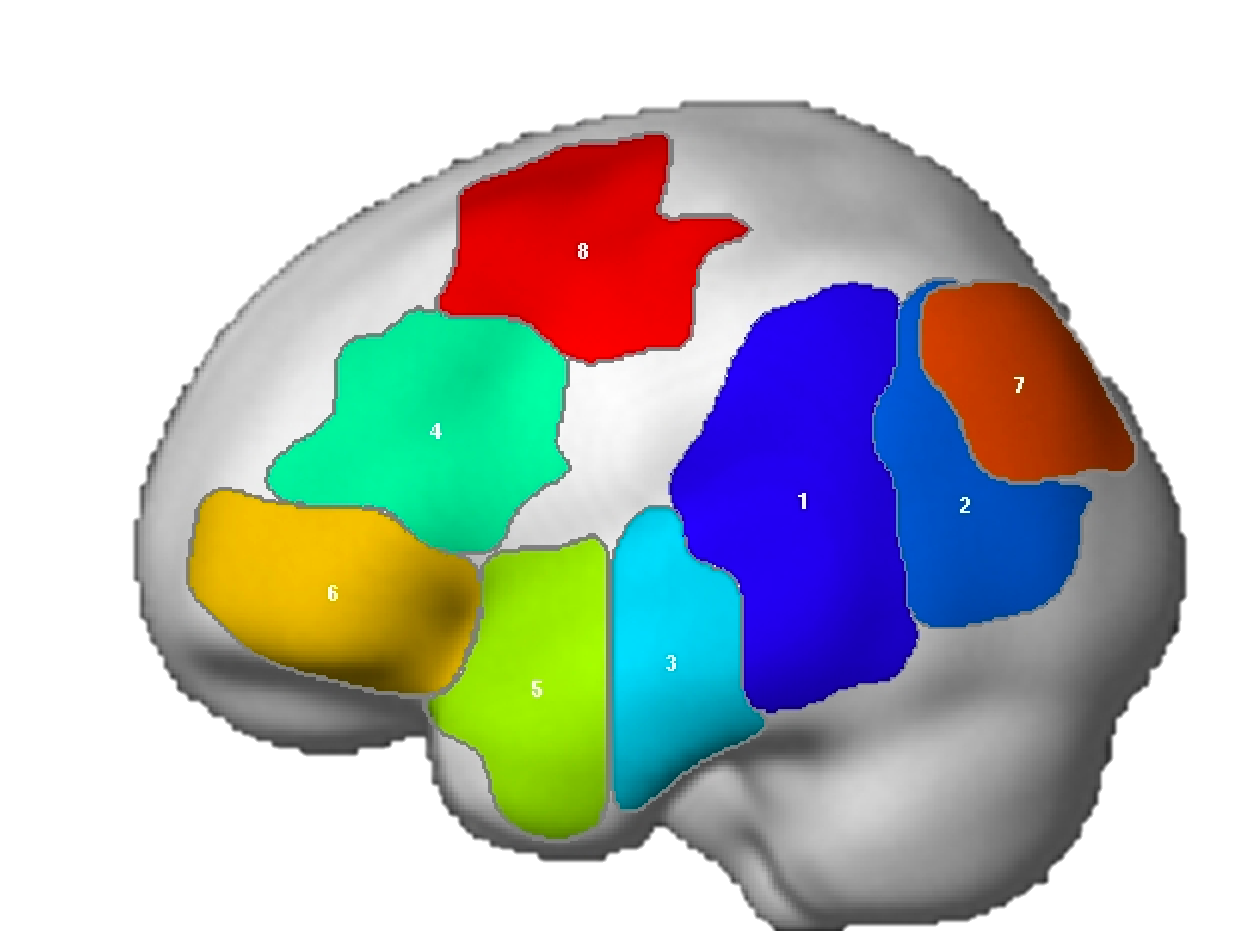
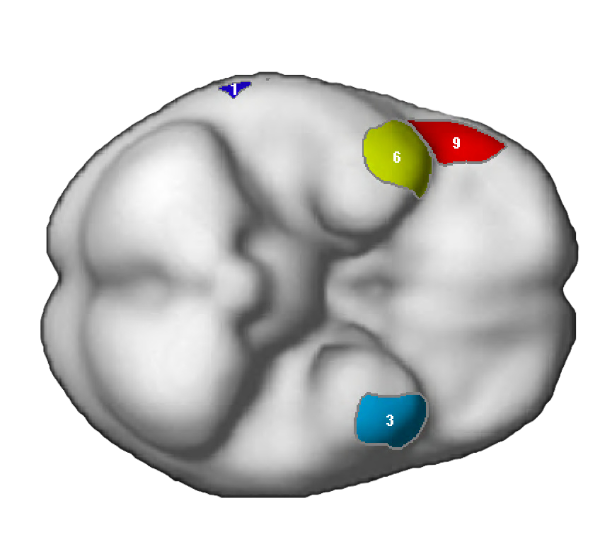
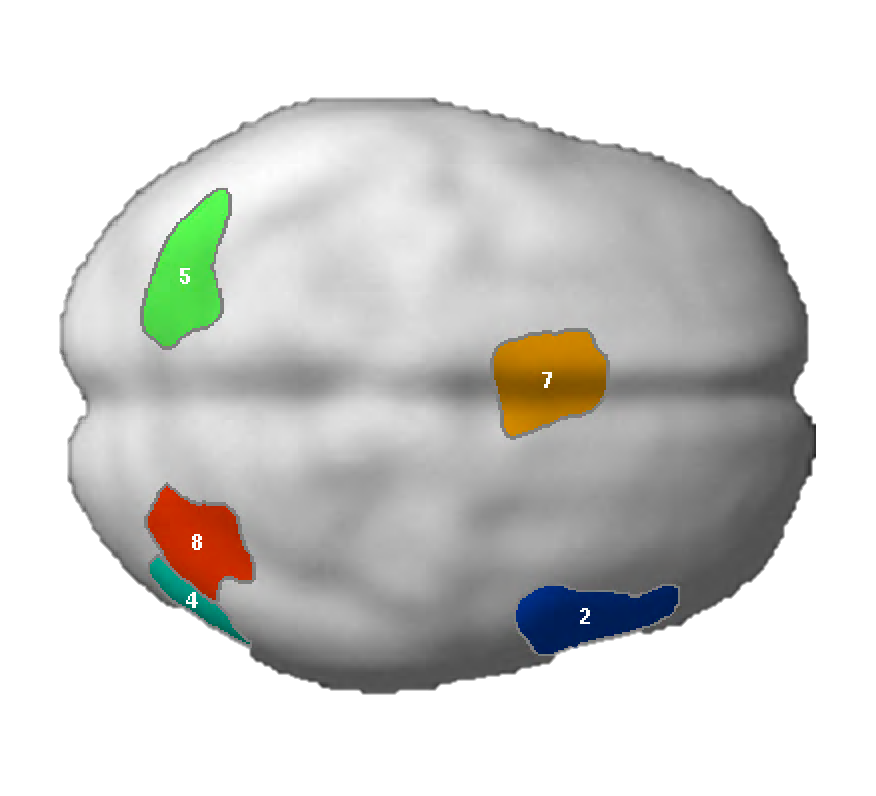
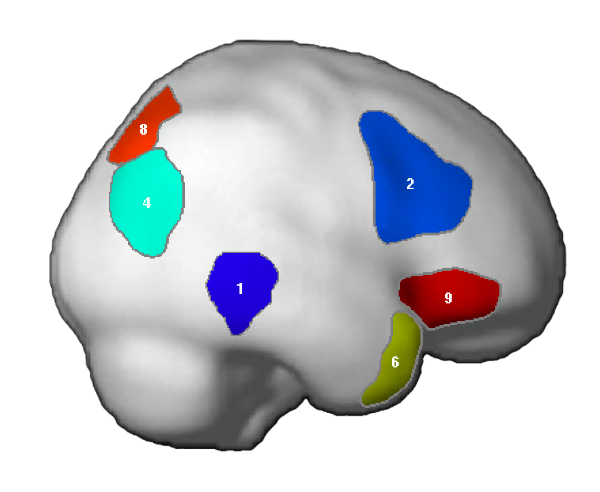
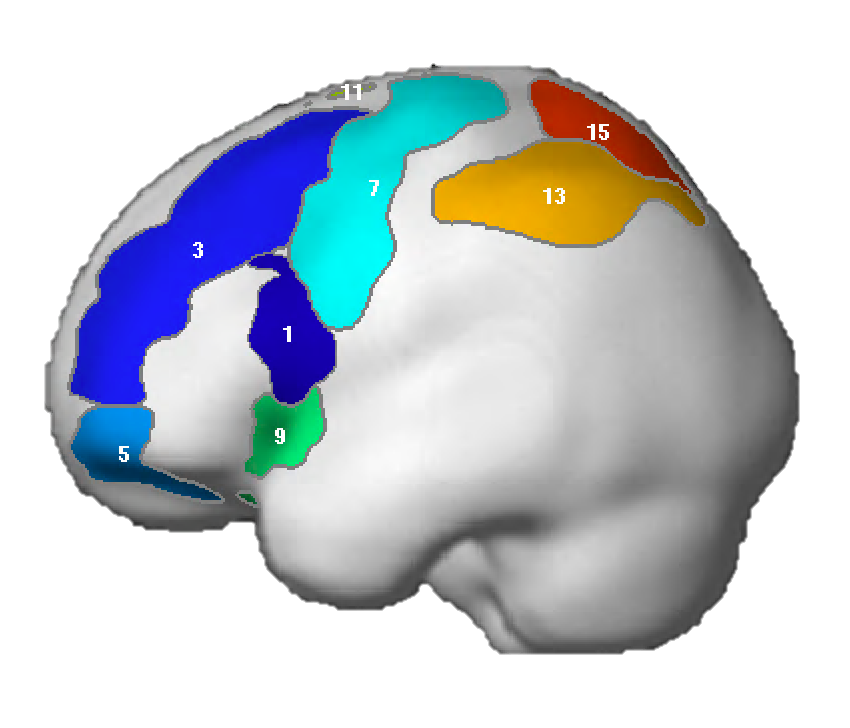
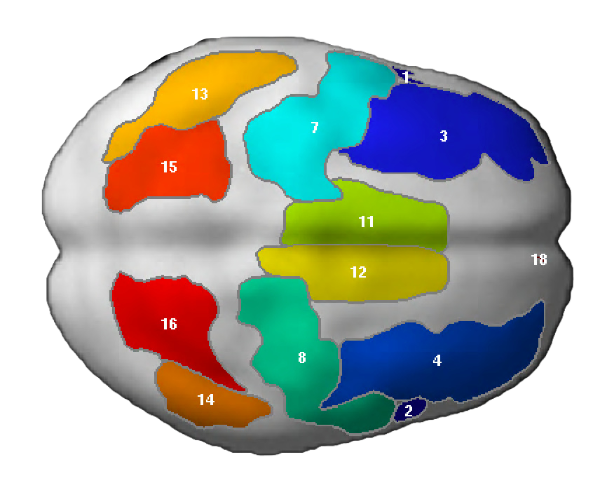
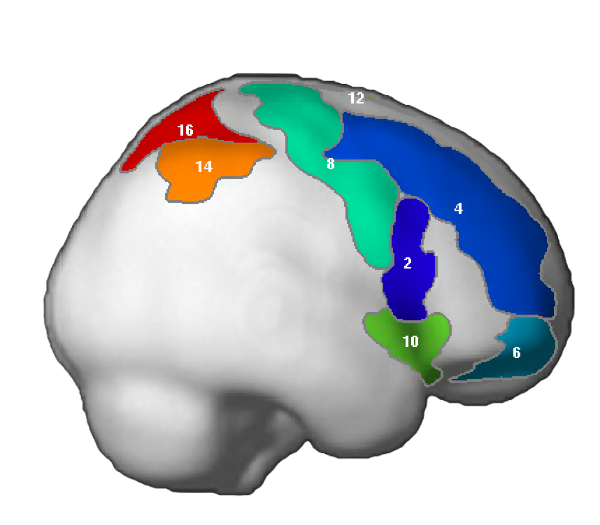
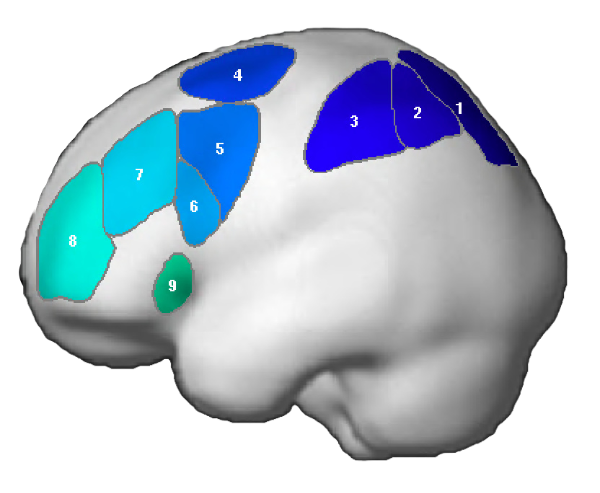
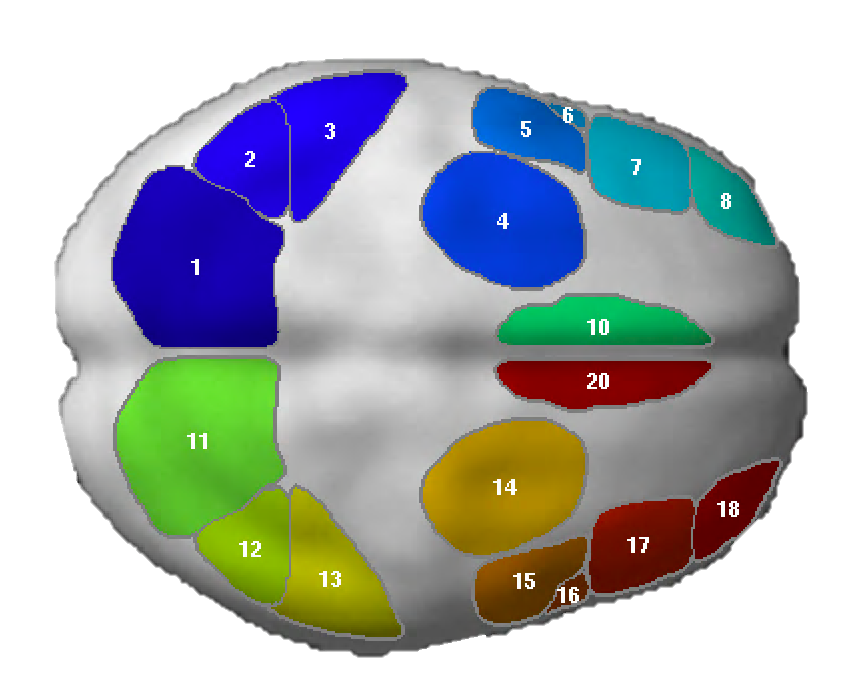
NB: These parcels are similar to the parcels reported originally in Fedorenko et al. (2010), except that the two anterior temporal parcels (LAntTemp, and LMidAntTemp) ended up being grouped together, and two posterior temporal parcels (LMidPostTemp and LPostTemp) ended up being grouped together.
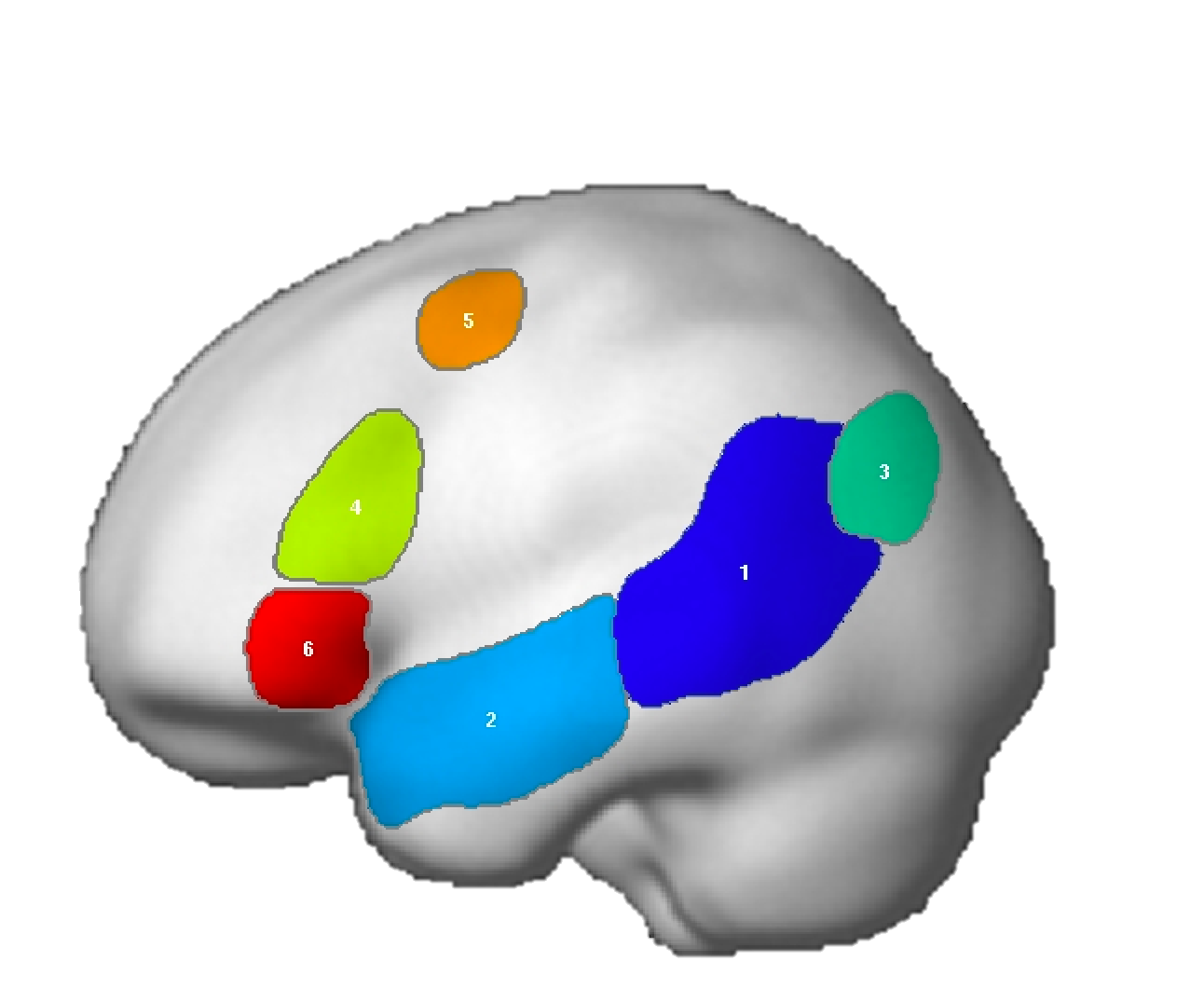
NB: For the ACC region, we edited the mask manually to restrict the region to the dorsal part of the anterior cingulate (not reflected in the visualization below, but see Fig. 3 in Fedorenko et al. (2013).
This toolbox was developed by Alfonso Nieto-Castañon and Ev Fedorenko to facilitate the process of conducting subject-specific analyses in SPM.
This toolbox uses SPM and is run in MATLAB. Example scripts can be found in spm_ss/batchexamples.
Primary use: for defining subject-specific fROIs using parcels derived from some localizer task (or using anatomical parcels; e.g., Brodmann areas), and for extracting the response from these fROIs. (For example, you can use our for intesecting with individual subjects’ activation maps for the S>N localizer contrast.)