What is surprising about scale-free networks?
The scale-free network is surprising because was not expected. In nature there are different random processes that generate Poisson distributions (e.g. radioactive decay) or exponential distributions (e. g. electronic component's lifetime), but there are very few precesses that generate scale-free distributions. In fact the work of Erdos and Renyi showed that networks that are growth by randomly adding new nodes and connections have Poisson or exponential topologies. That is the paradox, networks like WWW or the sexual partners network are growth randomly adding new nodes and new connections along time. Then, how is it possible that these neworks that were growth randomly do not have either Poisson or exponential topologies as Erdos and Renyi predicted?.
As we shown in the previous page, the Poisson topology is very different from the scale-free topology. In Poisson structures, the nodes have in average the same number of connections, whereas the most important characteristic in scale-free networks is its high heterogeneity, there are nodes with very few connections, and nodes that are extremly connected. The later are known as hubs. Is still completely unknown what are the processes that lead formation of scale-free networks, however there have been advances in the comprenhension of these networks. In the following sections we will shown some of teh mathematical formalisim to study the growth of networks.
Erdos-Renyi networks (Poisson topology)
Lets imagine a set of buttons randomly distributed on a table and initially unconnected. At time t = 0, we randomly pick a pair of buttons and we tie those together with thread. After connect them, we release again the buttons on the table an again we pick two buttons. We can select buttons that are connected with others, but we discard the pair if we selected one that has been selected before. Lets repeat the operation
times. At the end of this process, we will end with
joints between
different pairs, generating a network of buttons. Intuitively we know that if
is small compared to
, then the resultant network will be composed by many small islands. In each island the buttons will be attached by threads, but there will be disconnected from other islands. However if
is as large as
, we will end with almost all the buttons joined to each other.
After having selected pairs in a set of
buttons, what will be the degree of connections,
in the resultant network?. As we will see in a moment, the resultant network has a Poisson distribution. Before to proof that, it is important to mention that for a long time people thought that this mechanism of network growing in which pairs are randomly joined was the suitable model to describe social networks like friendship networks or sexual partners networks. It was natural to think networks like those that are growth by random meetings between people in a society could be described by the mechanism just shown. It was natural but it was incorrect.
Let calculate the probability, , for our buttons network. To start, lets consider the total number of pairs
that can be formed from a set of
buttons is:
We selected buttons pairs, so the probability
of a randomly selected pair of being attached is:
Now lets focus in one particular node, , that was randomly chosen. The total number of pairs that could contain
, is
, because we could have attached
with the remaining
nodes. However within the
selected pairs, we didn't select necessarily
all the possible times. Lets say that
was selected
times in the
pairs. Then, the probability of
of being in
of the
possible pairs is
Network growth
In the description above presented we assumed that we had a fixed population of nodes and a fixed number
of conecctions randomly added to built the network. However, networks are not fixed systems. The complex networks evolve and they grow on time by adding nodes and connections. For example, in 1969, internet network was composed only by two computers, one in the University of California at Los Angeles (UCLA) and the other in the Stanford Research Institute (SRI). In 2000 that network inlcuded 170 countries and more than 300 millions of people.
As the last example just showed, our model needs to take in count the possibility of adding new nodes and new conecctions as well as the elimination of previously present connections and nodes. In the simplest model of network growth, que can add a new node in each time step. This new node can be connected with any previously present node. Then, the probability of each node of being selected is , where
is the i-th node connectivity at time t.
The growth process starts with a unique initial node at time
. At
we add a new node
, that will be connected to the only existing node
with probability 1. At time
we add a new node
that can be connected to either
or
with the same probability 0.5. At this point, the nodes
,
and
no longer have the same connectivity. Any of these three will have two connections, whereas the other two will have just one connection.
At time
we add a new node
that can be connected to either
,
or >
with a probability that will be a function of their connectivities
,
and
. Following htis protocol, at time
we add the node
that will be connected to any of the existing nodes,
,
...
, the later will be selected with a probability
, where
is the i-th node connectivity at time
.
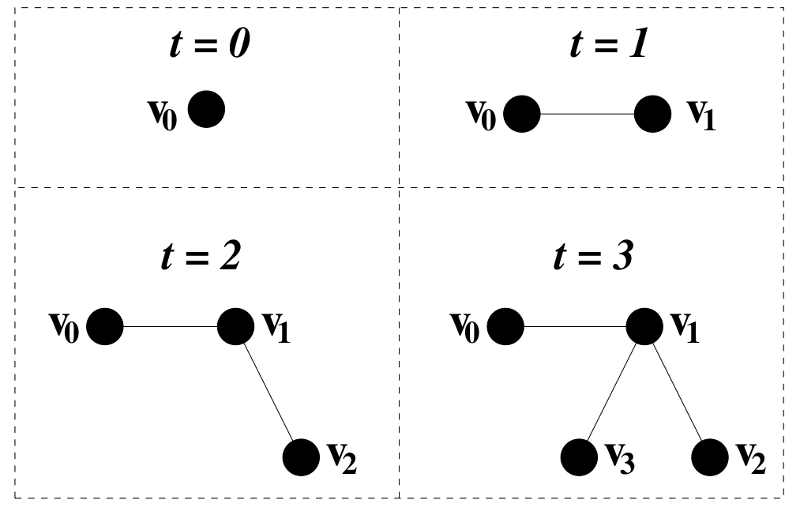
Network growth At time there is just one node
. in each subsequent step, we add a new node that will be connected to any of the previous existing nodes with a probability
that depends on the connectivity
of the i-th node at time
Lets denote as to the probability that at time
an arbitrary node within the network had
connections. It is clear that the probability depends on time. However, we expect that if we continue adding nodes for a long enough time, we will reach a point in which
no longer depends on time. Such as that point is known as stationary state. It is important to remark that the network keeps growing as we add more nodes, but the connections degree (or connections distribution )
, is the one that reaches a state in which
, the connection distribution no longer depends on time.
There are different approaches to calculate the connection distribution , but the mathematical formulation of any of those is out of the scope of this introductory page. Instead we will show just the results for the master equation approach.
The master equation approach includes the two following contributions to calculate the temporal evolution of the connection distribution, , associated to the node
.
- At time
, the node
had
connections and was selected (with probability
) to be connected with the new added node. Furthermore, at time
, the node
connections.
- At time
) to be connected with the new added node. Furthermore, at time
We should note that in order to be able to solve the time evolution of we need to know the explicit form of
, which is the probability of an existing node with conectivity
of being selected to form a connection with the new node that is added at time
. As we will see in the following section differents expressions for
led to different topologies.