Adam H Marblestone
Email: adam.h.marblestone [at] gmail
Publications: google scholar
Patents: google patents
CV: PDF

Gaussian Gated Linear Networks
with David Budden*, Eren Sezener*, Tor Lattimore, Greg Wayne** and Joel Veness**

We propose the Gaussian Gated Linear Network (G-GLN), an extension to the recently proposed GLN family of deep neural networks. Instead of using backpropagation to learn features, GLNs have a distributed and local credit assignment mechanism based on optimizing a convex objective. This gives rise to many desirable properties including universality, data-efficient online learning, trivial interpretability and robustness to catastrophic forgetting. We extend the GLN framework from classification to multiple regression and density modelling by generalizing geometric mixing to a product of Gaussian densities. The G-GLN achieves competitive or state-of-the-art performance on several univariate and multivariate regression benchmarks, and we demonstrate its applicability to practical tasks including online contextual bandits and density estimation via denoising.
Preprint: ArXiv
Product Kanerva Machines: Factorized Bayesian Memory
with Yan Wu* and Greg Wayne
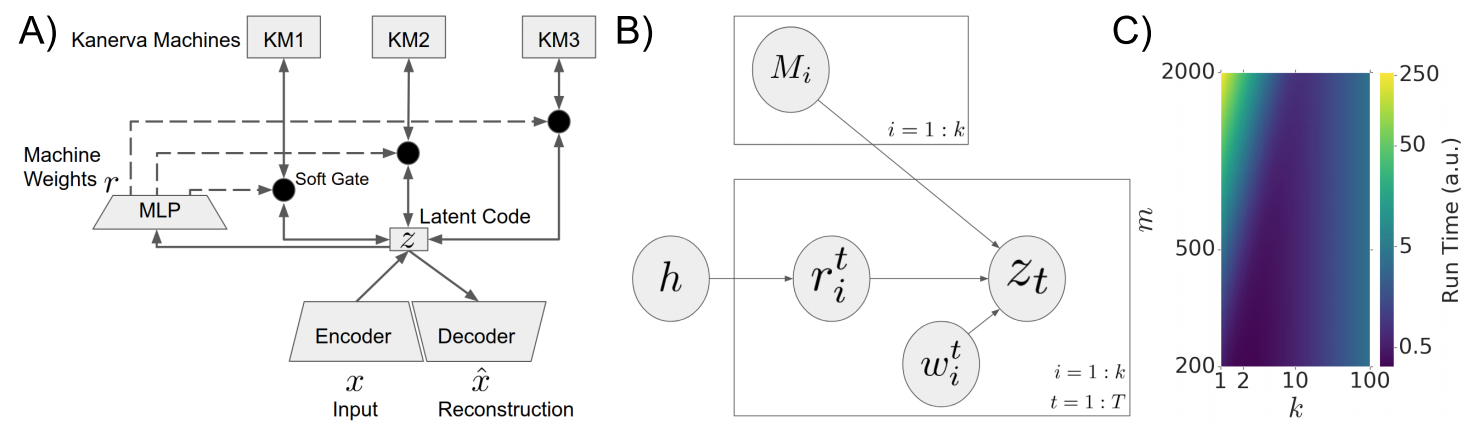
An ideal cognitively-inspired memory system would compress and organize incoming items. The Kanerva Machine (Wu et al, 2018) is a Bayesian model that naturally implements online memory compression. However, the organization of the Kanerva Machine is limited by its use of a single Gaussian random matrix for storage. Here we introduce the Product Kanerva Machine, which dynamically combines many smaller Kanerva Machines. Its hierarchical structure provides a principled way to abstract invariant features and gives scaling and capacity advantages over single Kanerva Machines. We show that it can exhibit unsupervised clustering, find sparse and combinatorial allocation patterns, and discover spatial tunings that approximately factorize simple images by object.
Preprint: ArXiv
Video presentation from ICLR BAICS workshop: html
Malthusian Reinforcement Learning
work led by Joel Leibo et al
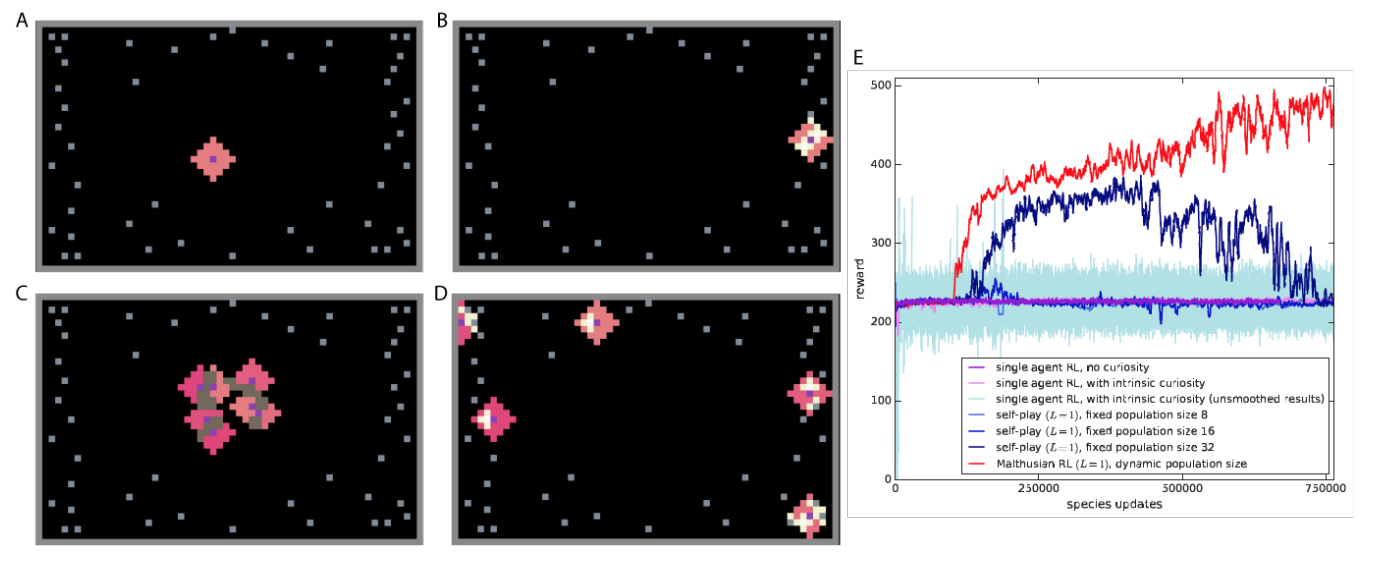
Here we explore a new algorithmic framework for multi-agent reinforcement learning, called Malthusian reinforcement learning, which extends self-play to include fitness-linked population size dynamics that drive ongoing innovation. In Malthusian RL, increases in a subpopulation's average return drive subsequent increases in its size, just as Thomas Malthus argued in 1798 was the relationship between preindustrial income levels and population growth. Malthusian reinforcement learning harnesses the competitive pressures arising from growing and shrinking population size to drive agents to explore regions of state and policy spaces that they could not otherwise reach. Furthermore, in environments where there are potential gains from specialization and division of labor, we show that Malthusian reinforcement learning is better positioned to take advantage of such synergies than algorithms based on self-play.
Preprint: ArXiv
Automatically inferring scientific semantics
with Tom Dean and Ed Boyden
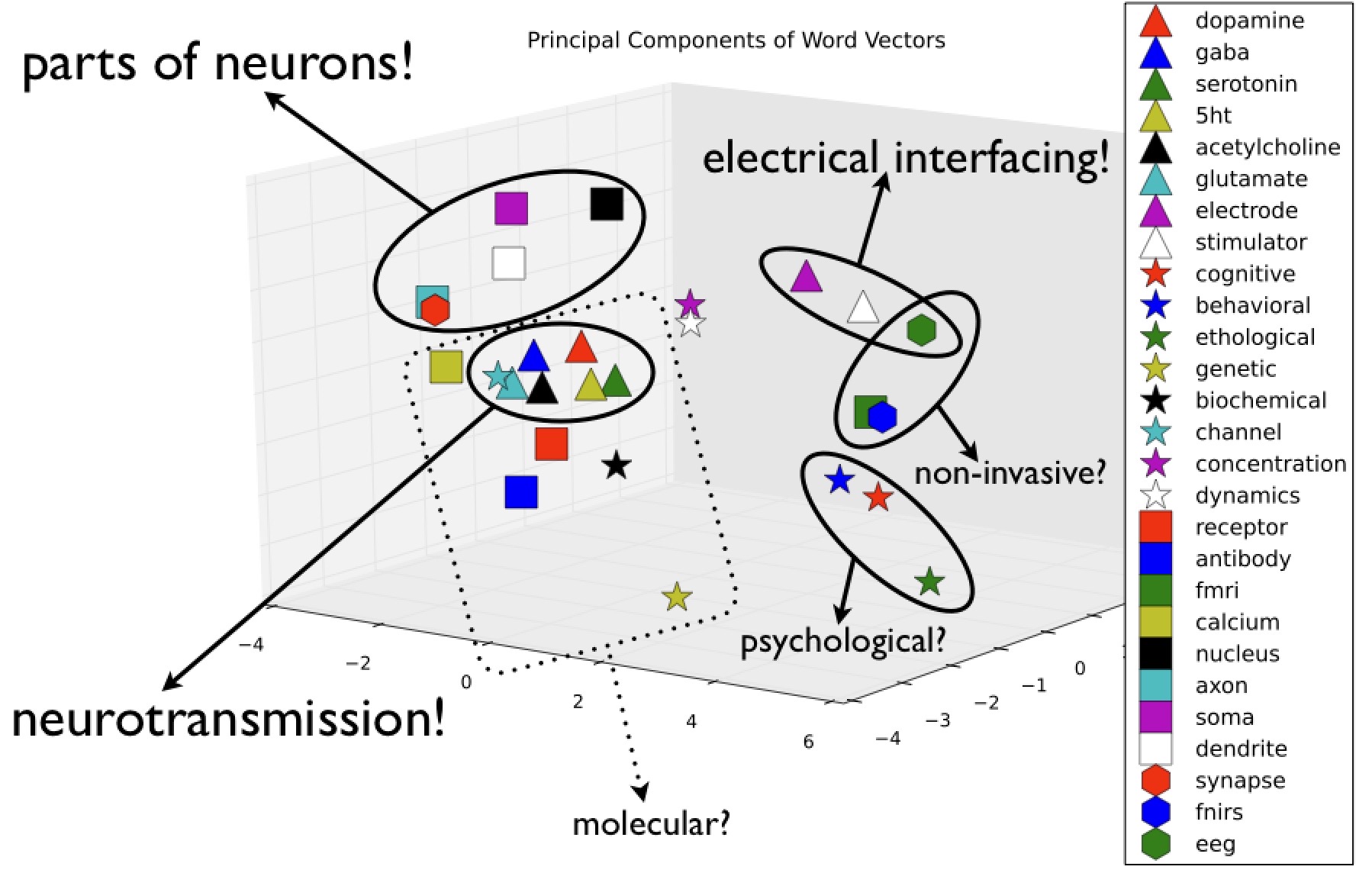
How can one gain comprehension of an unfamiliar field as quickly as possible? While some have developed strategies for learning the structures of entire fields, better web-based tools might facilitate such learning. The citation graph of the scientific literature reveals community and topic structure which can be extracted automatically, yet a full citation graph of the literature is not yet publicly available. Thus, we explored whether meaningful information about scientific semantics and topic structure can be automatically inferred purely from publicly available data, such as paper abstracts.
Project description: HTML