I work in the interdisciplinary area of computational perception and cognition - at the intersection of computer science and cognitive science. I focus on the human and computer processing of visual data, which spans computer vision, human vision and memory, machine learning, human computer interaction, and visualization.
At the cross-section of these research areas are applications to user interfaces, visual content design, and educational tools. By studying how humans attend to, remember, and process visual stimuli, the goal of my research is to contribute to cognitive science, while using this understanding for building computational applications.
Find me on: Google Scholar.
My research can be categorized into the following 3 main directions:
- Information Visualizations and Infographics: how do humans and machines perceive visual displays of data?
- Image Saliency and Importance: what are the most important image regions?
- Image Memorability: what makes an image memorable?
|
|
Eye-tracking and visual attention |
|
Human memory and image memorability |
|
|
Information visualizations and infographics |
|
Evaluation, metrics, and benchmarking |
Click on an icon to highlight all projects containing the corresponding topic. Click again to toggle.
How is a visualization or infographic perceived?
This line of work has two goals:
(1) To understand how people perceive data visualizations and infographics: Which visualizations are easily remembered and why? What information can people extract from visualizations? What do people pay the most attention to?
(2) To build computational models that can perceive infographics and understand what they are about.
 |
Computational Perception for Multimodal Document Understanding
Bylinskii, Z.
MIT Ph.D. Thesis 2018 [George M. Sprowls Award for Best PhD Theses in Computer Science] [thesis] [slides] [poster] |
|
 |
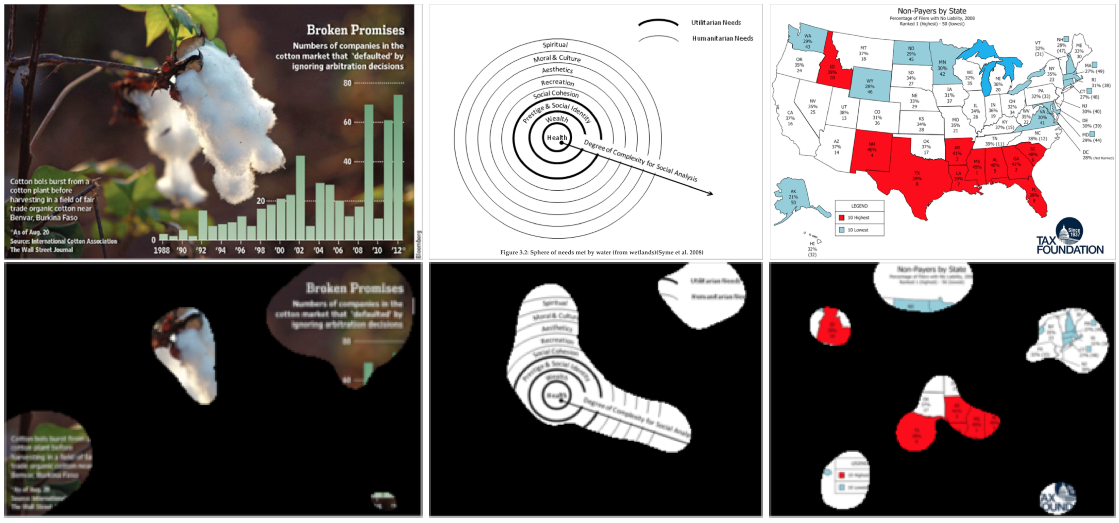
Synthetically Trained Icon Proposals for Parsing and Summarizing Infographics Madan, S.*, Bylinskii, Z.*, Tancik, M.*, Recasens, A., Zhong, K., Alsheikh, S., Pfister, H., Oliva, A., Durand, F. arXiv preprint arXiv:1807.10441 (2018) * = equal contribution [paper] [website] [code] |
|
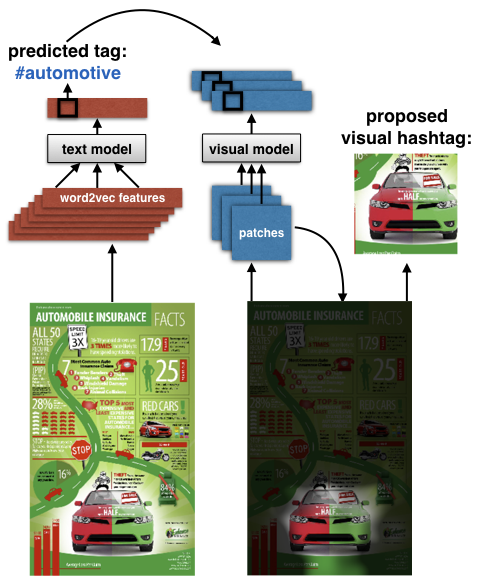 |
Understanding Infographics through Textual and Visual Tag Prediction Bylinskii, Z.*, Alsheikh, S.*, Madan, S.*, Recasens, A.*, Zhong, K., Pfister, H., Durand, F., Oliva, A. arXiv preprint arXiv:1709.09215 (2017) * = equal contribution [paper] [website] [code] |
|
|
Eye Fixation Metrics for Large Scale Evaluation and Comparison of Information Visualizations Bylinskii, Z., Borkin, M., Kim, N.W., Pfister, H. and Oliva, A. In Burch, M., Chuang, L., Fisher, B., Schmidt, A., Weiskopf, D. (Eds.) Eye Tracking and Visualization: Foundations, Techniques, and Applications (pp. 235-255). Springer International Publishing. [chapter] [book] |
|
|
 |
Beyond Memorability: Visualization Recognition and Recall Borkin, A.M.*, Bylinskii, Z.*, Kim, N.W., Bainbridge, C.M., Yeh, C.S., Borkin, D., Pfister, H., and Oliva, A. IEEE Transactions on Visualization and Computer Graphics (Proceedings of InfoVis) 2015 * = equal contribution [paper] [supplement] [website] [video] [media] |
|
 |
What Makes a Visualization Memorable? Borkin, M., Vo, A., Bylinskii, Z., Isola, P., Sunkavalli, S., Oliva, A., and Pfister, H. IEEE Transactions on Visualization and Computer Graphics (Proceedings of InfoVis) 2013 [paper] [supplement] [website] [media] |
|
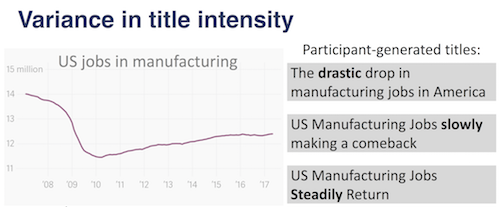 |
Effects of title wording on memory of trends in line graphs Newman, A., Bylinskii, Z., Haroz, S., Madan, S., Durand, F., Oliva, A. Vision Sciences Society (VSS) 2018 [abstract] [poster] |
|
 |
What eye movement and memory experiments can tell us about the human perception of visualizations Bylinskii, Z., Borkin, A.M., Kim, N.W., Pfister, H., Oliva, A. Vision Sciences Society (VSS) 2017 [abstract] [poster] |
|
 |
Eye Fixation Metrics for Large Scale Analysis of Information Visualizations.
Bylinskii, Z., Borkin, A.M. First Workshop on Eye Tracking and Visualization (ETVIS) in conjunction with InfoVis 2015 [paper] [slides] [data & code] |
|
 |
A Crowdsourced Alternative to Eye-tracking for Visualization Understanding.
Kim, N.W., Bylinskii, Z., Borkin, A.M., Oliva, A., Gajos, K.Z., and Pfister, H.
CHI Extended Abstracts (CHI'15 EA) 2015 [paper] [poster] |
|
Image Saliency and Importance
Saliency is a information measure of images that can be used to determine the most important image parts. Applications include image summarization and thumbnailing, user interfaces, and object detection. Many new saliency models are developped every year, and progress is improving rapidly. I am currently running the MIT Saliency Benchmark, one of the most popular datasets for evaluating saliency models. At the same time, I'm investigating new ways of crowdsourcing attentional data in order to train models to automatically discover the most salient or important image regions. Most recently, I have applied the idea of image importance to graphic designs.
Publications |
Learning Visual Importance for Graphic Designs and Data Visualizations.
Bylinskii, Z., Kim, N.W., O'Donovan, P., Alsheikh, S., Madan, S., Pfister, H., Durand, F., Russell, B., Hertzmann, A. UIST (2017) [honorable mention award] [paper] [supplement] [website & demo] [code] [talk] [slides] |
|
 |
BubbleView: an interface for crowdsourcing image importance and tracking visual attention.
Kim, N.W.*, Bylinskii, Z.*, Borkin, M., Gajos, K.Z., Oliva, A., Durand F., Pfister, H. ACM Transactions on Computer-Human Interactions (2017) * = equal contribution [paper] [supplement] [slides] [website & demo] [data files] |
|
 |
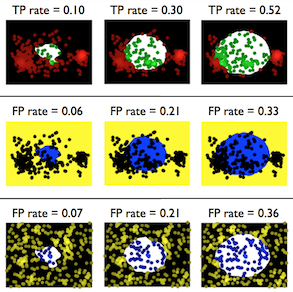
Where should saliency models look next? Bylinskii, Z., Recasens, A., Borji, A., Oliva, A., Torralba, A., Durand, F. European Conference on Computer Vision (2016) [paper] [supplement] [poster] |
|
 |
What do different evaluation metrics tell us about saliency models?
Bylinskii, Z.*, Judd, T.*, Oliva, A., Torralba, A., Durand, F. IEEE Transactions on Pattern Analysis and Machine Intelligence (2018) * = equal contribution [paper] |
|
 |
Towards the quantitative evaluation of visual attention models.
Bylinskii, Z., DeGennaro, E., Rajalingham, R., Ruda, H., Zhang, J. Tsotsos, J.K.
Vision Research 2015 [paper] |
|
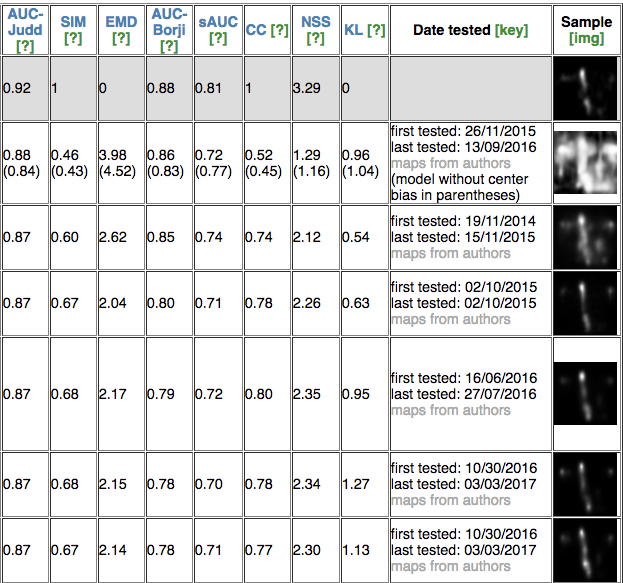 |
MIT Saliency Benchmark Bylinskii, Z., Judd, T., Borji, A., Itti, L., Durand, F., Oliva, A., and Torralba, A. Available at: http://saliency.mit.edu as of June 2014 |
|
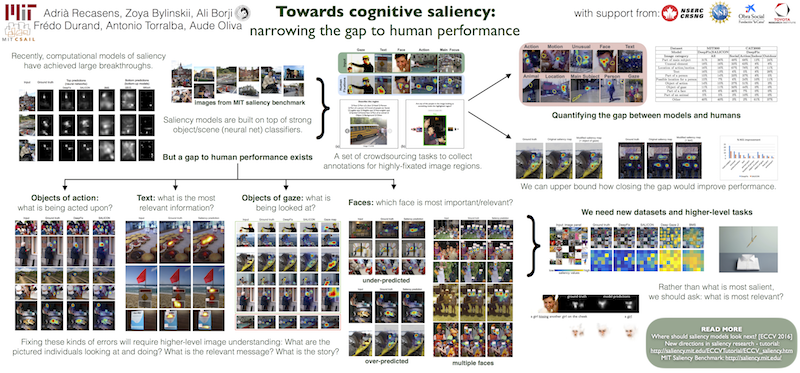 |
Towards cognitive saliency: narrowing the gap to human performance Recasens, A., Bylinskii, Z., Borji, A., Durand, F., Torralba, A., Oliva, A. Vision Sciences Society (VSS) 2017 [abstract] [poster] |
|
![[poster]](http://web.mit.edu/zoya/www/VSS2017_cognitiveSaliency.png){kind=link}
A computational understanding of image memorability
Images carry the attribute of memorability: a predictive value of whether the image will be later remembered or forgotten. Understanding how image memorability works and what it is affected by has numerous applications - from better user interfaces and design to smarter image search and education tools. This research aims to answer: to what extent is memorability consistent across individuals? How quickly can an image be forgotten? How can we model the effects of image context on memorability (can we make an image more memorable by changing its context)? Can we use people's eye movements and pupil dilations to make predictions about memorability?
Publications |
Intrinsic and Extrinsic Effects on Image Memorability Bylinskii, Z., Isola, P., Bainbridge, C., Torralba, A., Oliva, A. Vision Research 2015 [paper] [supplement] [website] |
|
 |
Image Memorability in the Eye of the Beholder: Tracking the Decay of Visual Scene Representations Vo, M., Bylinskii, Z., and Oliva, A. BioRxiv:141044 2017 [paper] |
|
 |
Computational Understanding of Image Memorability Bylinskii, Z. MIT Master's Thesis 2015 [thesis] [slides] [poster] |
|
|
How you look at a picture determines if you will remember it. Bylinskii, Z., Isola, P., Torralba, A., and Oliva, A. IEEE CVPR Scene Understanding Workshop (SUNw) 2015 [abstract] [poster] |
|
|
 |
Modeling Context Effects on Image Memorability. Bylinskii, Z., Isola, P., Torralba, A., and Oliva, A. IEEE CVPR Scene Understanding Workshop (SUNw) 2015 [abstract] [poster] |
|
 |
Quantifying Context Effects on Image Memorability. Bylinskii, Z., Isola, P., Torralba, A., and Oliva, A. Vision Sciences Society (VSS) 2015 [poster] |
|
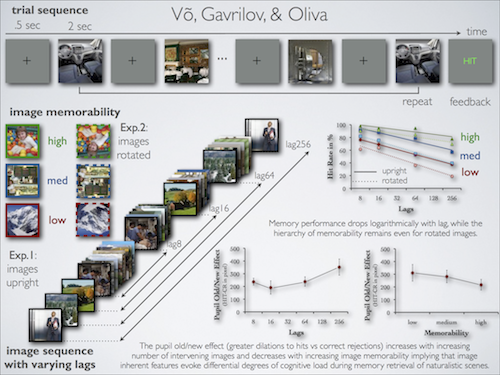 |
Image Memorability in the Eye of the Beholder: Tracking the Decay of Visual Scene Representations Vo, M., Gavrilov, Z., and Oliva, A. Vision Sciences Society (VSS) 2013 [abstract] [supplement] |
|
Other Computer Vision Projects
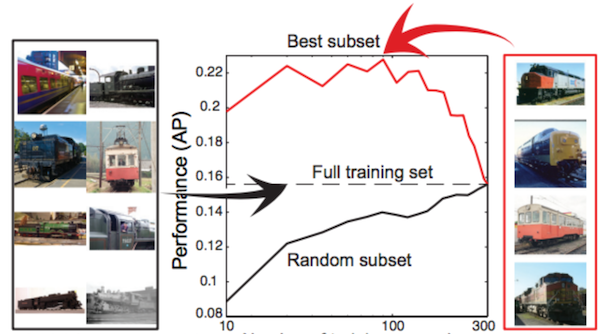 |
Are all training examples equally valuable? Lapedriza, A., Pirsiavash, H., Bylinskii, Z., Torralba, A. arXiv (1311.6510 [cs.CV]) 2013 [paper] |
|
 |
Detecting Reduplication in Videos of American Sign Language Gavrilov, Z., Sclaroff, S., Neidle, C., Dickinson, S. Proc. Eighth International Conf. on Language Resources and Evaluation (LREC) 2012 [paper] [poster] |
|
 |
Skeletal Part Learning for Efficient Object Indexing Gavrilov, Z., Macrini, D., Zemel, R., Dickinson, S. Undergraduate Research Project 2013 [poster] |
|
I have been funded by the Natural Sciences and Engineering Research Council of Canada via: the Undergraduate Summer Research Award (2010-2012), the Julie Payette Research Scholarship (2013), and the Doctoral Postgraduate Scholarship (2014-ongoing).